
第二次結對編程總結
第二次結對編程總結
成員: 陳燦 劉澤 王子博
github地址:https://github.com/USTC-ASE-P10/wf
PSP表格
| PSP2.1 | 任務內容 | 計劃完成需要的時間(min) | 實際完成需要的時間(min) |
|---|---|---|---|
| Planning | 計劃 | 30 | 30 |
| Estimate | 估計這個任務需要多少時間,並規劃大致工作步驟 | 30 | 30 |
| Development | 開發 | 670 | 590 |
| Analysis | 需求分析 (包括學習新技術) | 20 | 30 |
| Design Spec | 生成設計文檔 | 30 | 30 |
| Design Review | 設計復審 (和同事審核設計文檔) | 30 | 10 |
| Coding Standard | 代碼規範 (為目前的開發制定合適的規範) | 30 | 20 |
| Design | 具體設計 | 40 | 40 |
| Coding | 具體編碼 | 360 | 300 |
| Code Review | 代碼復審 | 60 | 40 |
| est | 測試(自我測試,修改代碼,提交修改) | 100 | 120 |
| Reporting | 報告 | 190 | 210 |
| Test Report | 測試報告 | 60 | 60 |
| Size Measurement | 計算工作量 | 30 | 30 |
| Postmortem & Process Improvement Plan | 事後總結 ,並提出過程改進計劃 | 100 | 120 |
| Summary | 合計 | 890 | 830 |
實驗要求
第0步:輸出某個英文文本文件中26個字母出現的頻率,由高到低排列,並顯示字母出現的百分比,精確到小數點後面兩位。
第一步:輸出單個文件中的前 N 個最常出現的英語單詞。
第二步: 支持 stop words。
第三步: 我們想看看常用的短語是什麽, 怎麽辦呢?
第四步:把動詞形態都統一之後再計數。
How you collaborate: working separately? pair programming? VS Live Share? other style?
一開始是兩人結對,一人領航,一人駕駛;後來的大部分工作,兩人領航,一人駕駛。
How do you discuss design guideline, coding convention and reach agreement?
我們的編碼風格主要是PEP8,然後編碼時是三個人討論具體的實現細節,然後王子博對於我一些不合風格的寫法會給予糾正,比如空格換行這些格式之類的。
How did the two of you aim high and try to deliver the optimal result with your own time constraints? is this the best your could do? what prevent you from doing your best?
我們三個人克服了一些阻礙,抽出了一定的連續時間來合作;這不是我們能做到的最好結果,因為我們的時間精力是有限的,還有很多公司的事情,生活上的事情需要處理。
List 3 strengths and 1 weak area of your partner
劉澤:
1.腦子轉得快,在先驗知識比較豐富的前提下,對於很多數理邏輯問題,能給予很快的反饋
2.解決實際問題能力強
3.對新事物的學習能力很強
4.平時編碼少,經驗不足,我也有同樣的弱點,希望能在接下來的一段時間提升自己的engineering能力
王子博:
1.對python語言有比較深刻的認識
2.領導以及表達能力優秀,能合理安排團隊的工作
3.編碼規範,工程能力強
4.據本人說,從未用過C++,理由好像是不接觸自己無法精通的領域,我反而覺得可以多去嘗試一下,不必拘泥於必須精通,嘗試過程中可能會有所改觀。
How do you use profile tools to find the performance bottleneck and improve speed? show some screenshots of your analysis
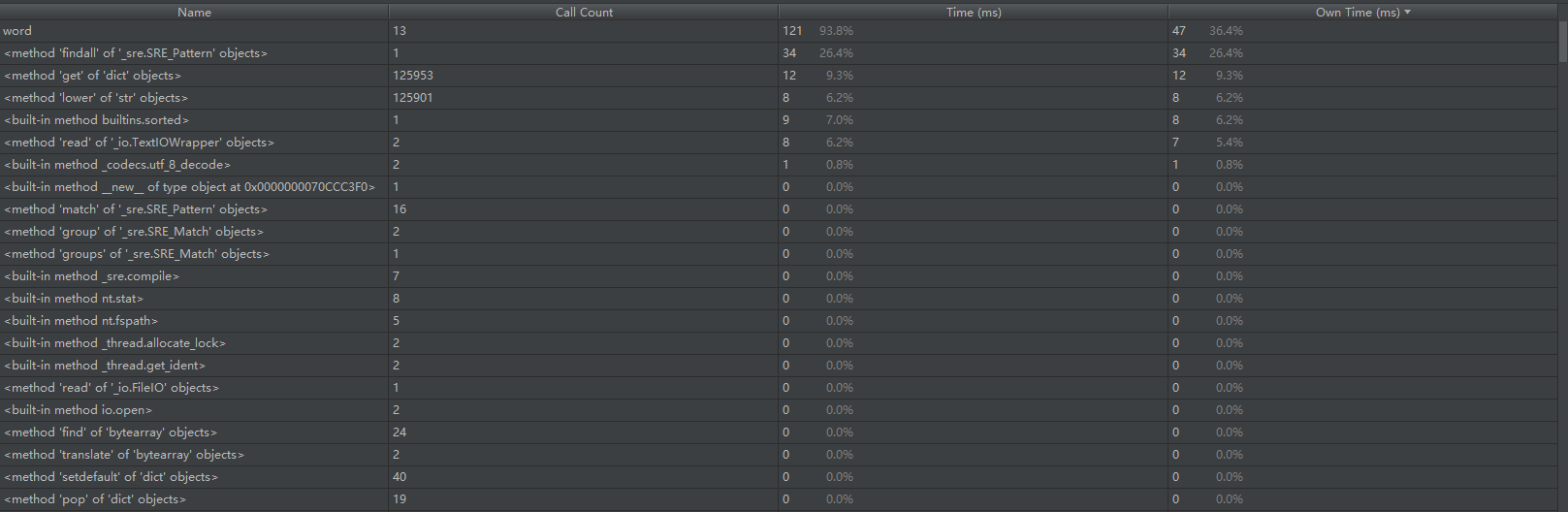
使用了Pycharm中profile進行性能分析,測試的配置是:
wf.py -f -n 10 C:\Users\v-checan\Desktop\pride-and-prejudice.txt
即統計pride-and-prejudice.txt中出現頻率前10的單詞,得到的性能分析結果:

可以看到,我們的wf.py主體是main函數,main函數裏面的__init__(),parse_args各占0.8%的時間,負責初始化和參數解析,顯然這部分也不是我們的主體。我們在統計詞頻這個功能中調用最多的是word這個函數,然後我們再分析這個函數裏面的情況:lower()占用6.2%的時間,sorted占用7.0%的時間,open占用0.0%的時間,read()占用6.2%的時間;真正的大頭在於findall函數,我們這裏采用了正則匹配的方法去找到符合我們要求的詞,但是這樣其實我們很難在這裏面進行優化,除非我們根據文本的內容以及我們要查找的實際邏輯來重新細化寫一個函數,但是這樣的話,會顯得很復雜。
接下是我們具體的數字形式的性能分析結果:
單元測試
利用python的unitest進行我們的單元測試,具體代碼可以訪問我們github地址:https://github.com/USTC-ASE-P10/wf/blob/master/tests.py
第二次結對編程總結