
#####好好好####從Google Visor到Microsoft NNI再到Advisor調參服務介面發展史

從Google Visor到Microsoft NNI再到Advisor調參服務介面發展史
![]()
Contributor to the world.
10 人讚了該文章
介紹
從規則程式設計到機器學習,從人工調參到AutoML(meta-machine learning),一直是整個行業發展的趨勢。目前各種黑盒優化演算法、增強學習演算法也越來越得到工業界接受,最著名的當屬來自DeepMind的AlphaGo和AlphaZero。我們都知道AlphaZero用了基於夢特卡索樹搜尋的增強學習架構來實現自我提升,但一個模型有數以千計的超引數需要調優,其背後就是基於大規模的GPU訓練叢集以及啟發式的貝葉斯優化演算法。BayesianOptimization是目前最流行的黑盒優化演算法,也就是說適用於任何函式、模型或者框架,相比與RL需要樣本量小很多,基於聯合高斯分佈的前提數理上保證收斂,除此之外還有Grid search、Random search、TPE、PSO、SMAC等主流調參演算法。
調參演算法是成熟而公開的,但不是所有開發者都需要掌握其實現,例如BayesianOptimization的實現就需要包含了Gaussian process的計算以及Acquisition function的選擇,就像大家都在用sgd/adam/adagrad/ftrl優化器也可以不瞭解其更新邏輯。因此各種實現黑盒優化演算法的調參類庫以及調參服務應用而生,這裡主要區分Library以及Service因為其使用介面區別很大,本文就將以Google Vizier、Microsoft NNI和Advisor為例介紹這些調參框架的設計和實現。
下面列舉其他非常不錯、值得參考的開源調參框架:
- Distributed Asynchronous Hyperparameter Optimization in Python hyperopt/hyperopt
- A fully decentralized hyperparameter optimization framework AIworx-Labs/chocolate
- Hyperparameter Optimization for Keras Models autonomio/talos
- AutoML library for building modular, reusable, strongly typed machine learning workflows on Spark salesforce/TransmogrifAI
- hyperparameter_hunter HunterMcGushion/hyperparameter_hunter
- Milano is a tool for automating hyper-parameters search for your models on a backend of your choice https://github.com/NVIDIA/Milano
- Repository for hyperparameter tuning kubeflow/katib
- AMLA: an AutoML frAmework for Neural Networks CiscoAI/amla
- Ray Tune https://ray.readthedocs.io/en/latest/tune.html
Google Vizier
我最早接觸自動調參是從Google CloudML的功能列表中瞭解到的,直到看到Vizier的論文全文才瞭解到其背後的實現,論文地址 https://static.googleusercontent.com/media/research.google.com/en//pubs/archive/46180.pdf 。簡單來說,Google CloudML提供了一個雲端訓練模型和自動調參的功能,使用者把Python程式碼上傳上去,定義一個HyperparameterSpec,雲平臺就會使用調參演算法並行訓練並且選擇效果最優的超參組合和模型,幕後功臣則是Google內部的Vizier服務。在Google內部,Vizier不僅提供調參服務給Google Cloud的服務,面向跟底層還提供了批量獲取推薦超參、批量更新模型結果、更新和除錯調參演算法以及Web控制檯等功能,因此內部Vizier服務才展示了最完整的調參服務概況。
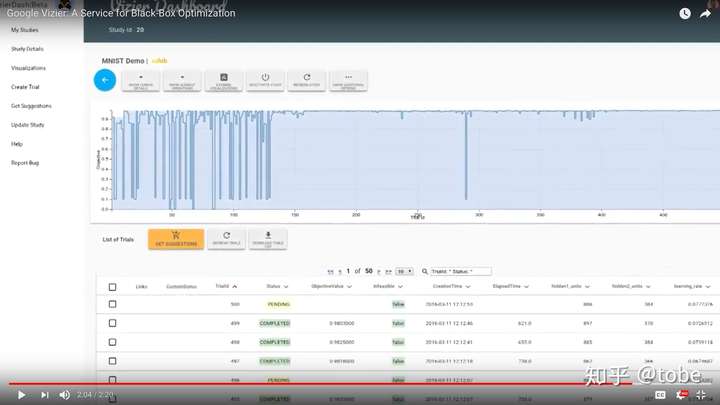
從前面提到的分類方式來講,Google Vizier屬於Service,也就是說所有的演算法和邏輯實現都在後端,客戶端只能通過API或SDK來訪問服務。這樣做的好處非常多,例如後端有新演算法的更新不需要去升級使用者程式碼,後端實現高可用比客戶端維護狀態更安全,後端演算法計算不需要佔用模型訓練者資源,當然還有最重要的一個原因,就是後端服務可以收資料。作為業界最領先的用增強學習和遷移學習來下圍棋和為機房省電的企業,Google用自動調參服務的資料來調優自動調參服務當然就在情理之中了,如果機器學習就是基於資料的meta-learning,那麼調超參的服務就是meta-meta-learning,那麼“調”調超參服務的這個服務就是meta-meta-meta-learning了。實際上Google Vizier也做不到所有超參或者超參的超參都由機器來學習調整,但他們確實從歷史調引數據中用遷移學習解決了演算法冷啟動問題,目前即使是貝葉斯優化也存在冷啟動問題,也就是說有一定量樣本後才可以開始啟發式地調優,如果沒有樣本資料只能先Random search幾把才用貝葉斯優化,Google Vizier論文則提到通過對搜尋空間的變換可以複用歷史推薦樣本,感興趣可以一起探討下細節。
當然,看似美好的介面設計也存在不足,最大的問題就是難用,或者說需要改程式碼才能用。這是所有調參框架都要面對的問題之一,因為框架需要保證使用者的模型用上了推薦的超引數,而且需要收集使用者模型的指標以便於後續超參的推薦,因此使用者程式碼至少需要加兩個介面getParameters()和outputMetrics()。前面提到Google CloudML只需要定義一個HyperparameterSpec就可以了,實際上你的模型程式碼也要改,首先是通過tf.FLAGS或者argparse等引數的方式獲取Vizier提供的超參,然後使用TensorBoard event file或者Estimator add metrics把模型的指標回報給Vizier。使用Google CloudML的話只要按照 https://cloud.google.com/ml-engine/docs/tensorflow/using-hyperparameter-tuning 這個文件的規範編碼就可以了,但開發者更多時候要在本地除錯程式碼而且也不一定非要用TensorFlow來建模,這樣Google CloudML就很難支援了。
當然Google Vizier在內部提供了更底層的API,例如可以CRUD各種資源,如Study、Trial、Metrics等,甚至可以在Algorithm Playground中新增自己實現的黑盒調優演算法。由於Google Vizier沒有開源,具體的API介面不得而知,但從我們實現的開源版Vizier發現,提供Study/Trial/Metrics介面其實並不易用,而且對使用者程式碼侵入較大,易用性遠不如基於Library的hyperopt、chocolate等框架好用。
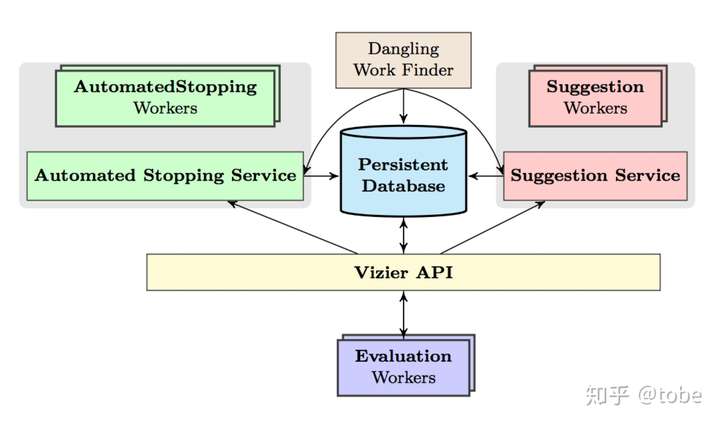
上圖是Google Vizier的整體架構,看圖其實也基本瞭解其實現了,有定義調參服務的介面API,包括Search sapce的格式規範和支援的型別,還有資料庫進行資料持久化,兩邊是可擴充套件、可插拔的Suggestion演算法和Early stopping演算法。通過對API的封裝實現了一個HyperTune subsystem,也就是Google CloudML產品中的自動調參功能。
Microsoft NNI
說完Google的調參服務,我們來看看業界另一大標杆巨硬公司的產品,NNI(Neural Network Intelligence)是Microsoft近期開源的調參工具包,專案地址 Microsoft/nni 。從名字和官方教程可以看出,NNI相比於Vizier其實是一個Library,也就是說演算法是執行在客戶端本地的,當然NNI也提供了遠端執行訓練任務的功能,執行NNI的機器相當於演算法控制器。
NNI與Hyperopt類似(實際上NNI內建的TPE演算法就是用的hyperopt),使用體驗上要比Vizier好不少,同樣地使用者需要定義Search space和修改程式碼來獲取引數、匯出Metrics結果,但提供了一個執行配置,可以像本地命令列一樣執行模型訓練程式碼,不論使用者使用TensorFlow還是CNTK等任意框架,下面是官方提供的使用流程圖。

如果深入看NNI原始碼,本體是Python實現的命令列工具,和大部分調參Library實現類似,亮點是可以整合其他類庫的調參演算法,因此藉此可以介紹下一般通用調參框架的架構實現。
首先,所有調參服務都有自定義的Search space格式規範,為什麼不能有統一的規範讓所有框架去實現?是因為不同框架實現的處理方式有區別,例如Google Vizier支援了INTEGER、DOUBLE、DISCRETE、CATEGORICAL這幾種型別描述,而Microsoft NNI因為相容hyperopt演算法,開源類庫chocolate也有相似的定義,支援的都是類似hyperopt.hp.uniform()、hyperopt.hp.choice()的超參描述。雖然框架不同,但Search space基本都可以用JSON來表達,對於Service型別調參框架因為只能通過API請求,因此必須是標準的JSON資料,不能包含Python SDK函式,而Library型別調參框架可以像Hyperopt用函式來表示,也可以像NNI用標準JSON資料格式來表示。如果我們去取所有框架搜尋空間型別的子集,理論上所有框架的演算法都可以互通互用,在後面要提到的Advisor調參服務上,我們也是參考NNI實現了對Hyperopt的TPE、Random search、Simulate anneal演算法以及Chocolate的Quasi random search、Random search、Grid search、Bayes search、CMAES、MOCMAES演算法整合。
第二步就是調參演算法的實現,在NNI中除了前面提到的Hyperopt TPE演算法,底層實現了Evolution tuner也就是進化演算法。對於這類演算法的實現,主要是要實現一個generate_parameters()介面,當然好的演算法需要根據歷史的訓練資料來“啟發式”推薦引數,因此NNI也提供一個receive_trial_result()介面,演算法可以根據使用者模型的結果動態更新調參演算法本身的引數。下面是Microsoft NNI各種調參演算法實現的基類介面。

在Advisor專案中,我們的演算法定義就更加簡潔了,當然從極致的效能角度考慮,Library型別框架可以把調參物件放在記憶體中維護,生成超參不需要重新載入歷史結果因此效率更高,不過調參服務效能不會是調參瓶頸因此一般可以不考慮。
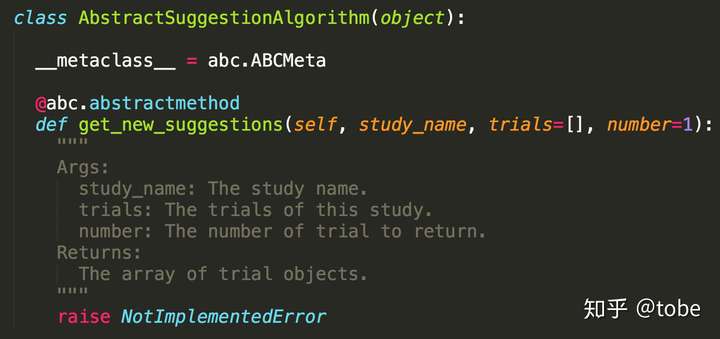
最後就是定義調參的API和SDK,這也是直接影響使用者體驗和應用場景的關鍵。前面提到Google Vizier目前只能在Google CloudML中使用,因此只能優化TensorFlow模型的超參,而NNI提供了pynni的Python SDK,因此只要是Python應用都可以使用,也就是幾乎所有的機器學習建模指令碼(CNTK、TensorFlow、PyTroch、MXNet等等)都可以應用。而且相比於純SDK的接入方式,NNI還提供一個命令列工具nnictl,使用者可以寫一個配置檔案,然後使用nnictl來啟動訓練和調參任務,而且通過拓展NNI的TrainingServicePlatform,目前支援把任務執行在local和remote,實現上也不復雜使用了TypeScript的ssh庫,當然未來很容易可以拓展讓任務執行在Kubernetes、Mesos、Yarn等分散式平臺上。除了NNI這類使用方式,還有更機制的調參框架整合,例如針對Scikit-learn封裝Hyperopt而成的hyperopt-sklearn,只要簡單替換Scikit-learn中的Estimator物件就可以實現全自動的多工調參過程,這種封裝在已經實現了調參核心演算法和邏輯的框架上就非常好實現了。
Advisor
看完Google Vizier和Microsoft NNI服務的架構,其實最想重點介紹的是Advisor,一個基於Vizier論文實現的調參服務,同時也集成了NNI的介面使用特點,當然還有最流行的BayesianOptimization等演算法實現,開源地址 tobegit3hub/advisor 。

如果想了解Advisor的架構特點和領域抽象,可以直接參考Vizier論文,因為裡面定義的Study、Trial、TrialMetrics都與Vizier一致(好的抽象很重要!),甚至Search space的配置也保持與Vizier相容,而選擇Service的實現方式有助於未來遷移學習的演算法實現。在Vizier的架構基礎上,我們可以擺脫對TensorFlow的繫結,提供無侵入的使用體驗。前面提到使用所有調參框架都必須修改程式碼呼叫getParameters()和outputMetrics()介面,所謂“無侵入”只能通過約定的方式實現,參考Google CloudML我們可以把超參作為命令列引數傳入,這樣與使用者在本地命令列除錯模型的體驗一致,而回報模型指標只需要使用者在stdout最後一行列印Metrics即可,這比NNI必須依賴SDK來獲取引數和回報指標跟進一步。
下面是使用Scikit-learn進行MNIST模型訓練的一個例子,這個程式碼邏輯可以由開發者在命令列通過調參來觀察模型效果進而選擇最優的超參,同樣也可以直接使用Advisor進行自動的分散式的調參。
import argparse
from sklearn import datasets, svm, metrics
parser = argparse.ArgumentParser()
parser.add_argument("-gamma", type=float, default=0.001)
parser.add_argument("-C", type=float, default=0.5)
parser.add_argument("-kernel", type=str, default="sigmoid")
parser.add_argument("-coef0", type=float, default=0.1)
args = parser.parse_args()
def main():
digits = datasets.load_digits()
images_and_labels = list(zip(digits.images, digits.target))
n_samples = len(digits.images)
data = digits.images.reshape((n_samples, -1))
classifier = svm.SVC(
gamma=args.gamma, C=args.C, kernel=args.kernel, coef0=args.coef0)
classifier.fit(data[:n_samples // 2], digits.target[:n_samples // 2])
expected = digits.target[n_samples // 2:]
predicted = classifier.predict(data[n_samples // 2:])
accuracy = metrics.accuracy_score(expected, predicted)
print(accuracy)
if __name__ == "__main__":
main()
對於Adhoc的Python函式,在我們不知道函式是否可導或者有極值的情況下,我們也可以用Advisor來計算(算力越大效果越好),不同場景也可以選用BO、RS、GS、TPE、PSO等對應的調參演算法,是真正的黑盒優化,甚至是不同程式語言實現的機器學習框架也原生支援。
import argparse
parser = argparse.ArgumentParser()
parser.add_argument("-x", type=float, default=0.0)
args = parser.parse_args()
def main():
# Read parameters
x = args.x
# Compute or learning
y = x * x - 2 * x + 1
print("Formula: {}, input: {}, output: {}".format("y = x * x - 2 * x + 1", x, y))
# Output the metrics
print(y)
if __name__ == "__main__":
main()
這裡介紹下使用Advisor的調參全流程,安裝是很簡單的可以使用“pip install advisor-clients”,啟動Server服務端方式有多種,使用內建的指令碼、Docker容器、docker-compose或者是Kubernetes叢集。
advisor_admin server start
docker run -d -p 8000:8000 tobegit3hub/advisor
docker-compose up -d
kubectl create -f ./kubernetes_advisor.yaml
然後編寫你的模型訓練程式碼,由於“無侵入”的約定使用者不需要再引入任務與模型無關的程式碼,例如不需要"import advsior_client",直接用前面的Scikit-learn程式碼以及原生Python指令碼即可。到目前為止我們還沒有定義Search space,實際上這是調參應用所必須定義的,也就是建立Vizier中的Stduy或者是NNI中的Experiment,這個我們參考NNI用法提供了JSON配置檔案,使用者可以在檔案中指定Search space、調優演算法、啟動目錄、啟動指令碼等系列引數。
{
"name": "demo",
"algorithm": "BayesianOptimization",
"trialNumber": 10,
"concurrency": 1,
"path": "./advisor_client/examples/python_function/",
"command": "./min_function.py",
"search_space": {
"goal": "MINIMIZE",
"randomInitTrials": 3,
"params": [
{
"parameterName": "x",
"type": "DOUBLE",
"minValue": -10.0,
"maxValue": 10.0,
"scalingType": "LINEAR"
}
]
}
}
最後命令列執行即可,啟動後可以看到終端列印的除錯資訊以及推薦的引數,使用BayesianOptimization設定可以看到樣本越多推薦的結果越接近最優解,當然這個配置Aquisition function的expolration和exploitation來控制,這裡就不贅敘了。
advisor run -f ./advisor_client/examples/python_function/config.json

考慮到使用者還有其他方式訓練模型的可能,Advisor API和SDK還有批量匯入Trial、TrialMetrics等功能,這樣就可以整合不用Advisor訓練的歷史結果提高貝葉斯優化效果,而不需要像hyperopt那樣手動插入資料到SQLite(後續單開文章介紹hyperopt的原始碼和整合TPE演算法的方法)。演算法拓展也非常容易,除了可以使用已經整合的八種演算法,只要編寫一個Python檔案實現get_new_suggestions(self, study_name, trials=[], number=1)介面即加入自己的演算法,所有演算法實現都有對應的單元測試,感興趣可以閱讀原始碼瞭解 tobegit3hub/advisor 。未來考慮提供TensorFlow/Keras/Scikit-learn/XGBoost Estimator的wrapper,為Kaggle比賽的自動調參提供極致的體驗。
總結
最後總結一下,目前自動調參服務正所謂百花齊放,Microsoft、Nvidia、Salesforce都有對應的開源產品,而Spark、Ray和Kubernetes也有高度整合的功能模組,但所有調參框架都存在介面格式不統一,程式碼侵入性較大的問題。
希望通過本文大家可以瞭解業界主流的黑合優化框架的架構設計和實現原理,對比Google Vizier、Microsoft NNI以及Advisor的介面設計程序,實現程式碼“無侵入”的調參服務,同時也歡迎大家來使用和改進Advisor,任何Issue和PR都是非常有價值的。最近(2018年10月1日)我們就收到3個來自不同地區的Pull-request,開發者分別來自法國雷恩、巴西聖保羅以及瑞士,雖然都是小改動但也是十分appreciated的。
黑盒優化作為AutoML、NAS的基礎,meta-learning中的meta,相信未來必然有更廣的應用場景!