
教你如何從Google Map爬資料(切片)
轉:http://blog.csdn.net/JairusChan
在這篇博文中,筆者從實驗的角度,從爬資料的困難出發,闡述如何從Google Map上爬地圖資料。本文的出發點為實驗,而非商用。Google Map對其自己的資料具有其權益,希望讀者以博文為學習實驗之用,不要將自己所爬到的資料用於商用。如果因為此類事件所引起的糾紛,筆者概不負責。筆者也希望,大家在看到此博文後,能夠進一步改進其資料的安全性。
筆者在實驗室某個GIS專案中必須需要一定資料級的地圖資料。在百般無奈下,筆者開始從Google Map爬資料。從Google Map上採集一定量的資料有作實驗。
從Google Map爬資料的原理
Google Map所採用的是Mercator座標系。何為Mercator座標系?讀者可以詳見{連結}。在Google Map也是以金字塔模型的方式來組織切圖檔案的。至於,它的後端處理或者儲存方式或者檔案命名方式是怎麼樣,筆者不得而知。筆者只能從URL等方面進行分析,大概確定其地圖檔案的組織方式。在金字塔模型中,地圖分成若干層,每一層資料的解析度為上層的4倍(橫向與縱向各2倍)。同時,每一層資料的分辨是極其巨大,而且成指數形式增加。如果一下子,將一層的資料作為一個檔案返回給使用者,無論從網路的傳輸能力、CPU處理能力還是記憶體的儲存能力而言都是無法做到的。而且使用者所觀看的只是地圖的某一層的某一塊區域。因而,一般都會將地圖資料進行切圖,即進行切分,將地圖資料切成解析度相等的若干塊。因而,我們可以得知,每一層資料集的檔案數為上層的4倍。
筆者使用GoogleChrome來檢視Google Map的Resources,圖如下:
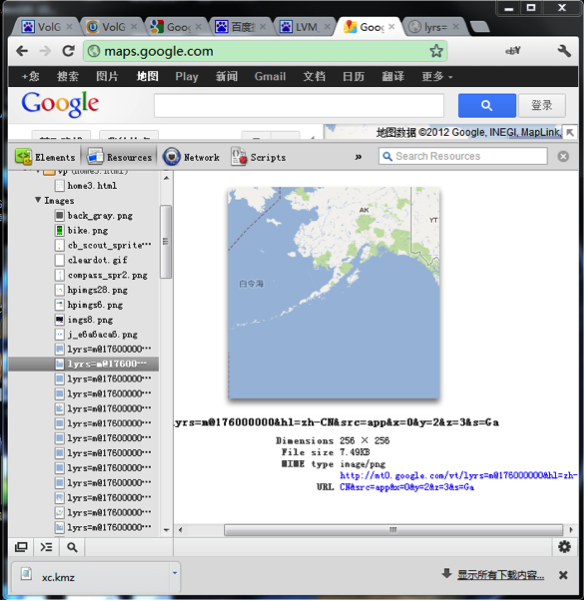
我們可以清楚地看到,在Google Map的地圖檔案並不是一次載入一整張,而是分成若干塊,每一塊的分辨為256*256。同時,我們也得到了每一塊地圖的地址,例如http://mt0.google.com/[email protected]
| x=0&y=0&z=0 |
 |
|
x=0&y=0&z=1
|
x=1&y=0&z=1 |
 |
 |
| x=0&y=1&z=1 | x=1&y=1&z=1 |
 |
 |
我們可以得知,x=xx,y=yy,z=zz的這塊資料,所在的圖層為zz層,該圖層中每塊資料的經度差為360/2^zz,緯度差為180/2^zz,左上角的經緯度為(360/2^zz*xx-180, 180/2^zz*yy-90)。同樣,我們也可從一個數據塊的左上角經緯度反推出這個檔案在zz層的x與y。這也就是我們從Google Map爬資料的原理。
從Google Map爬資料有何難點?
1. 在國內由於政治等原因,連線Google伺服器會有所中斷。
2. Google的Web伺服器,或者Google防火牆,會對某一臺客戶端的請求進行統計。如果一段時間內,請求數超過一定的值,此後的請求會直接被忽略。據說,當一天中,來自某一個IP的請求數超過7000個時,此後的請求後直接被忽略。
3. 單執行緒操作的效率太低,多執行緒情況下,效率會有很大提升。
4. Google伺服器會對每個請求檢查,判斷是否來自瀏覽器還是來自爬蟲。
5. 對於已下載的檔案無須下載,即爬蟲必須擁有“斷點續傳”的功能。不能由於網路的中斷或者人為的中斷,而導致之前的進度丟失。
對於這些難點有何解決方案
1. 對於第1點難點,我們可以使用國外的伺服器作為我們的代理。這樣,我們通過國外的伺服器來請求Google Map。而對於大名鼎鼎的GFW而言,我們連線的並不是Google的伺服器,而是其它的伺服器。只要那臺伺服器沒有被牆,我們就可以一直下載。
2. 對於第2個難點,我們依然可以使用代理。一旦,下載失敗,這個代理ip可能已經被Google Map所阻攔,我們就需要更換代理。如果,代理的連線速度較慢,或者代理的下載檔案時,超時較多,可能我們目前所使用的代理與我們的機器之間的網路連線狀態不佳,或者代理服務負載較重。我們也需要更換代理。
3. 單執行緒操作的效率太低,我們需要使用多執行緒。但是,在使用多執行緒時,由於每一個檔案的大小都很小,因而我們設計多執行緒機制時,每一個執行緒可以負責下載若干個檔案。而不同的執行緒所下載的檔案之間,沒有交集。
4. 對於第4點,我們可以在建立http連線時,設定”User-Angent”,例如:
[java] view plain copy- httpConnection.setRequestProperty("User-Agent", "Mozilla/4.0 (compatible; MSIE 5.0; Windows NT; DigExt)");
- httpConnection.setRequestProperty("User-Agent", "Mozilla/4.0 (compatible; MSIE 5.0; Windows NT; DigExt)");
5. 對於第5點,我們可以在每下一個檔案之間,事先判斷檔案是否已經完成。這有很多種解決方法,筆者在這裡,採用file.exists()來進行判斷。因為,對於下載一個檔案而言,檢查檔案系統上某一個檔案的代價會小很多。
改進與具體實現
1. 代理的獲取
代理的獲取有很多種方式。但如果一開始就配置所有的代理,那麼,當這些代理都已經無法使用時,系統也將無法執行下去。當然,我們也不想那麼麻煩地不斷去更換代理。筆者是一個lazy man,所以還是由計算機自己來更換代理吧。筆者在此使用www.18daili.com。www.18daili.com會將其收集到代理已web的形式釋出出來。因而,我們可以下載這張網頁,對進行解析,便可以得最新可用的代理了。筆者在這裡使用Dom4J來進行網頁的解析。
2. 架構

其中,分成三個模組:Downloader, DownloadThread, ProxyConfig。Downloader負責初化化執行緒池以存放DownloaderThread。每一個DownloadThread都會負責相應的若干個切圖資料的下載。DownloadThread從ProxyConfig那裡去獲取代理,並從檔案系統中檢查某一個檔案是否已經下載完成,並將下載完成檔案按一定的規則儲存到檔案系統中去。ProxyConfig會從www.18daili.com更新現有的代理,在筆者的系統,每取1024次代理,ProxyCofig就會更新一次。
原碼
Downloader:
[java] view plain copy- package ??;
- import java.util.concurrent.ExecutorService;
- import java.util.concurrent.Executors;
- public class Downloader {
- private static int minLevel = 0;
- private static int maxLevel = 10;
- private static String dir = "D:\\data\\google_v\\";
- private static int maxRunningCount = 16;
- private static int maxRequestLength = 100;
- public static void download() {
- ExecutorService pool = Executors.newFixedThreadPool(maxRunningCount);
- for (int z = minLevel; z <= maxLevel; z++) {
- int curDt = 0;
- int requests[][] = null;
- int maxD = (int) (Math.pow(2, z));
- for (int x = 0; x < maxD; x++) {
- for (int y = 0; y < maxD; y++) {
- if (curDt % maxRequestLength == 0) {
- String threadName = "dt_" + z + "_" + curDt;
- DownloadThread dt = new DownloadThread(threadName, dir, requests);
- pool.execute(dt);
- curDt = 0;
- requests = new int[maxRequestLength][3];
- }
- requests[curDt][0] = y;
- requests[curDt][1] = x;
- requests[curDt][2] = z;
- curDt++;
- }
- }
- DownloadThread dt = new DownloadThread("", dir, requests);
- pool.execute(dt);
- }
- pool.shutdown();
- }
- public static void main(String[] strs) {
- download();
- }
- }
DownloadThread:
[java] view plain copy- package ??;
- import java.io.BufferedInputStream;
- import java.io.File;
- import java.io.FileInputStream;
- import java.io.FileOutputStream;
- import java.io.InputStream;
- import java.net.HttpURLConnection;
- import java.net.Proxy;
- import java.net.URL;
- import java.text.SimpleDateFormat;
- import java.util.Date;
- public class DownloadThread extends Thread {
- private static int BUFFER_SIZE = 1024 * 8;// 緩衝區大小
- private static int MAX_TRY_DOWNLOAD_TIME = 128;
- private static int CURRENT_PROXY = 0;
- private String threadName = "";
- private String dir;
- // private int level;
- private String tmpDir;
- private Proxy proxy;
- private int[][] requests;
- private String ext = ".png";
- private static SimpleDateFormat dateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
- public DownloadThread(String threadName, String dir, int[][] requests) {
- this.threadName = threadName;
- this.dir = dir;
- this.requests = requests;
- }
-
相關推薦
教你如何從Google Map爬資料(切片)
轉:http://blog.csdn.net/JairusChan 在這篇博文中,筆者從實驗的角度,從爬資料的困難出發,闡述如何從Google Map上爬地圖資料。本文的出發點為實驗,而非商用。Google Map對其自己的資料具有其權益,希望讀者以博文為學習實驗之用,不要將自己所爬到的資料用於商
教你如何從Google Map爬資料
在這篇博文中,筆者從實驗的角度,從爬資料的困難出發,闡述如何從Google Map上爬地圖資料。本文的出發點為實驗,而非商用。Google Map對其自己的資料具有其權益,希望讀者以博文為學習實驗之用,不要將自己所爬到的資料用於商用。如果因為此類事件
React + Django + nginx + uwsgi 生產環境部署(一步一步教你從開發環境到線上環境)
剛剛在本地測試環境寫完專案,目前本地測試是一切順利,未發現異常,準備打包到生產環境伺服器上. 前端React + antd + React-Router + axios 後端Python3.6 + Django1.10.1 腳手架用的是create-rea
Swaggy教你用python實現NBA資料統計的爬取
相信很多喜歡NBA的小夥伴們經常會關注NBA的資料統計,今天我就用虎撲NBA的得分榜為例,實現NBA資料的簡單爬取。https://nba.hupu.com/stats/players是虎撲體育的NBA球員得分榜:當我們右鍵檢視該網站的原始碼時,會發現所有的資料統計都存放在&
一張思維導圖教你使用google一下
聯系 type ogl 頁面包含 mage str 包含 class 對比 導圖總覽 google搜索技巧.png 雙引號 代表完全匹配搜索 也就是說搜索結果返回的頁面包含雙引號中出現的所有的詞,連順序也必須完全匹配 例如搜索"java 排
手把手教你從零開始做一個好看的 APP
@+ error 教你 教授 wip rac tco 需要 apt 前言 從零開始,手把手帶你實現一個「專註睡前的 APP」。睡覺之前如果能有一個 APP,能讓我們寫一寫這一天的見聞或者心得,同時又能看一會段子、瞄一會好看的妹子,放松一下疲憊的身心那該多好,這也是我完成這
偽標籤:教你玩轉無標籤資料的半監督學習方法
對於每個機器學習專案而言,資料是基礎,是不可或缺的一部分。在本文中,作者將會展示一個名為偽標籤的簡單的半監督學習方法,它可以通過使用無標籤資料來提高機器學習模型的效能。 偽標籤 為了訓練機器學習模型,在監督學習中,資料必須是有標籤的。那這是否意味著無標籤的資料對於諸如分類和迴歸之類的監督任務
聰哥哥教你學Python之爬取金庸系列的小說
話不多說,程式碼貼起: # -*- coding: utf-8 -*- import urllib.request from bs4 import BeautifulSoup #獲取每本書的章節內容 def get_chapter(url): # 獲取網頁的原始碼 html
馳騁股市!手把手教你如何用Python和資料科學賺錢?python
金融領域或許是資料科學應用場景中最充滿想象力的部分,畢竟它跟財富結合地無比緊密。 不管是否是經濟達人,資料科學都是一種幫你瞭解一支股票的高效方式。本文作者把資料科學和機器學習技術應用到金融領域中,向你展示如何通過資料分析的方式馳騁股市,搭建自己的金融模型! 讓我們先了解一些基本
教你建立一個私密資料夾
教大家建立一個別人既無法進入又無法刪除的資料夾相信大家都遇到過自己的一些隱私檔案不願意讓別人看到的情況吧, 怎麼解決呢?隱藏起來?換個名字?或者加密?這些辦法都可以辦到,其實還有一種方法,就是建立一個別人既不能進入 又不能刪除的資料夾,把自己的隱私檔案放進去,別人就看不到啦,下面講講如何實
神奇回車鍵教你快速錄入Excel表格資料,開啟高效率工作模式!
作為一名辦公職員,我們經常會用到excel。當有大量資料需要錄入Excel表格時,我們會發現既需要雙手操作鍵盤,又需要一隻手控制滑鼠點選單元格,導致工作效率真是出奇的低。所以,今天給大家分享一下關於Excel快速錄入資料的技巧。 方法一: 開啟"檔案",點選"選項"—"高階",更改"按
零基礎學ui設計教學教你從0基礎建立設計規範
從一開始的立項到現在落地上線,可以說是從零開始進行APP全部細節的梳理並且規定規範,這一路走過來還是能總結出很多心得,本文將分為3個部分,闡述如何從0到1建立設計規範。 目錄: 一、如何確定內容,規範裡要寫什麼 二、如何寫 三、如何推動規範落地 一、如何確定內容? 這裡我總結了三步:
【手把手教你】Python獲取財經資料和視覺化分析
內容來自:微信公眾號:python金融量化 關注可瞭解更多的金融與Python乾貨。 “巧婦難為無米之炊”,找不到資料,量化分析也就無從談起。對於金融分析者來說,獲取資料是量化分析的第一步。Python的一個強大功能之一就是資料獲取(爬蟲)。但是對於沒時間學爬蟲程式的小白來說,pytho
害怕別人偷看資料?教你一招將Excel資料變"*"號,從此不再擔心!
今天和大家分享一波好用的Excel小技巧,喜歡的小夥伴千萬不要錯過了! 1.兩個表格快速相加 我們如何讓兩個格式相同但資料不同的表格需要相加呢?我們只需要複製其中一個表格,然後在另一個表格右擊【選擇性貼上】,在運算中選擇【加】,就能快速相加了。
三個月教你從零入門人工智慧+深度學習精華實踐課程|深度學習視訊教程2018
課程特色: 規劃全面:涵蓋目前主流的深度學習領域,包括影象識別,影象檢測,自然語言處理,GAN,分散式訓練框架等等。掌握每 一項技能都能在從事該領域邁進一步。 重點突出:摒棄繁冗的數學證明,一切從實際出發,突出重點,短時間內掌握重點知識。 實戰演練:課程包含多
手把手教你從零開始搭建SpringBoot後端專案框架
原料 新鮮的IntelliJ IDEA、一雙手、以及電腦一臺。 搭建框架 新建專案 開啟IDE,點選File -> New Project。在左側的列表中的選擇Maven專案,點選Next。 填寫GroupId和ArtifactId 什麼是GroupId和Ar
教你從0開始打造一場成功的微信抽獎活動方案!
網際網路已經進入了下半場,已經越來越成熟,流量已經成為了眾多網際網路公司所要爭奪的第一戰場,而流量在一 般意義上便是指使用者規模。只有當用戶的規模做起來之後,我們才能有更加廣闊的發展空間,而社交流量卻在整 個流量體系中佔據了絕大多數的比例,只要掌握了社交的流量,能夠將朋友圈的資源完全
神級python工程師教你從網站篩選工作需求資訊,助你就業
本文以Python爬蟲、資料分析、後端、資料探勘、全棧開發、運維開發、高階開發工程師、大資料、機器學習、架構師 這10個崗位,從拉勾網上爬取了相應的職位資訊和任職要求,並通過資料分析視覺化,直觀地展示了這10個職位的平均薪資和學歷、工作經驗要求。 1、先獲取薪資和學歷、工
一步一步教你從零開始寫C語言連結串列---構建一個連結串列
為什麼要學習連結串列? 連結串列主要有以下幾大特性: 1、解決陣列無法儲存多種資料型別的問題。 2、解決陣列中,元素個數無法改變的限制(C99的變長陣列,C++也有變長陣列可以實現)。 3、陣列移動元素的過程中,要對元素進行大範圍的移動,很耗時間,效率也不高。
教你從零開始寫一個雜湊表--導讀
雜湊表是一個可以提供快速實現關聯陣列的資料結構。“雜湊”一詞會讓人產生困惑,下面我做了個總結。 雜湊表由一系列的桶組成,每一個桶儲存一個鍵值對。為了能夠確定一個鍵值對應該儲存在哪個桶裡,關鍵字要傳遞給雜湊函式。雜湊函式返回一個指明桶陣列索引的整數。當我們想要查詢一個鍵值對時,我們對關