
關於什麼是一致性hash演算法
當需要分散式快取的時候,通過key的hash值分散資料儲存hash(n)%快取伺服器臺數,同時也可以快速查詢資料而不用遍歷所有的伺服器。如下圖:

但是這樣,當業務拓展想要增加一臺伺服器的話,要麼快取伺服器資料全部需要重新計算儲存 -----hash(n)%5 。 要麼需要遍歷所有快取伺服器。不夠靈活。
所以就出現了一致性hash演算法,來解決這樣的問題。
Hash環,如下圖所示:

一致性Hash演算法是key的hash值,對2^32取模,對伺服器確定確定此資料在環上的位置(比如A,B,C,D)。
資料進來後對2^32 取模,得到一個值K1,在Hash環中順時針找到伺服器節點。
假如B伺服器節點失效:
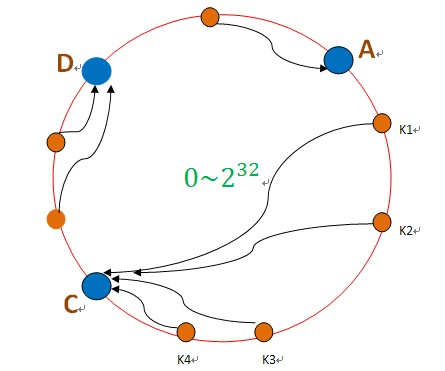
如果是B失效了,將B的資料遷移至C即可,對於原本雜湊在A和D的資料,不需要做任何改變。
總結:一致性hash演算法(DHT)通過減少影響範圍的方式解決了增減伺服器導致的資料雜湊問題,從而解決了分散式環境下負載均衡問題。
相關推薦
關於什麼是一致性hash演算法
當需要分散式快取的時候,通過key的hash值分散資料儲存hash(n)%快取伺服器臺數,同時也可以快速查詢資料而不用遍歷所有的伺服器。如下圖: 但是這樣,當業務拓展想要增加一臺伺服器的話,要麼快取伺服器資料全部需要重新計算儲存 -----hash(n)%5 。 要麼需要遍歷所有快取伺服器。不夠靈活。
一致性Hash演算法的深入理解
總結: 1、使用一致性Hash演算法,儘管增強了系統的伸縮性,但是也有可能導致負載分佈不均勻,解決辦法就是使用虛擬節點代替真實節點, 2、Hash演算法的選擇上,首先我們考慮簡單的String.HashCode()方法,這個演算法的缺點是,相似的字串如N1(10.0.
memcache客戶端實現叢集之一致性hash演算法
一致性雜湊的演算法把取餘演算法的等於號來選擇mem伺服器變成了大於號來選擇mem伺服器,這應該是才是關鍵,可以使一個鍵的mem伺服器落點變成是動態選擇(一個伺服器down掉然後選擇crc32(key)後大於這個伺服器的落點....) 新增虛擬節點,虛擬節點其實還是原來那幾臺伺服器,每個虛擬節
分散式演算法(一致性Hash演算法)
一、分散式演算法 在做伺服器負載均衡時候可供選擇的負載均衡的演算法有很多,包括: 輪循演算法(Round Robin)、雜湊演算法(HASH)、最少連線演算法(Least Connection)、響應速度演算法(Response Time)、加權法
一致性hash演算法程式碼實現
什麼是一致性hash 一致性雜湊演算法(Consistent Hashing Algorithm)是一種分散式演算法,常用於負載均衡。Memcached client也選擇這種演算法,解決將key-value均勻分配到眾多Memcached server上的問題。它可以取代傳統的取模操作
Java架構/一致性Hash演算法在資料庫分表中的實踐
最近有一個專案,其中某個功能單表資料在可預估的未來達到了億級,初步估算在90億左右。與同事詳細討論後,決定採用一致性Hash演算法來完成資料庫的自動擴容和資料遷移。整個程式細節由我同事完成,我只是將其理解併成文,供有相同問題的同行參考。 參看此文的兄弟,預設各位已經熟悉一致性hash
一致性Hash演算法在資料庫分表中的實踐
最近有一個專案,其中某個功能單表資料在可預估的未來達到了億級,初步估算在90億左右。與同事詳細討論後,決定採用一致性Hash演算法來完成資料庫的自動擴容和資料遷移。整個程式細節由我同事完成,我只是將其理解併成文,供有相同問題的同行參考。 參看此文的兄弟,預設各位已經熟悉一致性hash演算法了。此文僅僅闡述程式
一致性Hash演算法,Java程式碼實現
一致性Hash演算法 關於一致性Hash演算法,在我之前的博文中已經有多次提到了,MemCache超詳細解讀一文中"一致性Hash演算法"部分,對於為什麼要使用一致性Hash演算法、一致性Hash演算法的演算法原理做了詳細的解讀。 演算法的具體原理這裡再次貼上: 先構造
分散式一致性hash演算法
寫在前面 在學習Redis的叢集內容時,看到這麼一句話:Redis並沒有使用一致性hash演算法,而是引入雜湊槽的概念。而分散式快取Memcached則是使用分散式一致性hash演算法來實現分散式儲存。所以就專門學習了一下 什麼是分散式?什麼是一致性?什麼是雜湊? 1
什麼是一致性Hash演算法?
最近有小夥伴跑過來問什麼是Hash一致性演算法,說面試的時候被問到了,因為不瞭解,所以就沒有回答上,問我有沒有相應的學習資料推薦,當時上班,沒時間回覆,晚上回去了就忘了這件事,今天突然看到這個,加班為大家整理一下什麼是Hash一致性演算法,希望對大家有幫助!文末送書,長按抽獎助手小程式即可參與,祝君好運!
twemproxy0.4原理分析-一致性hash演算法實現ketama分析
概述 本文是一致性hash演算法的一種開原始碼的實現:ketama的原始碼分析。 本文是我多年前的一篇文章整理而來,以前的那篇文章的連結可以在這裡檢視。 簡介 若我們在後臺使用NoSQL叢集,必然會涉及到key的分配問題,叢集中某臺機器宕機時如何key又該如何分配的問題。
一致性 Hash 演算法(分散式或均衡演算法)
簡介: 一致性雜湊演算法在1997年由麻省理工學院提出的一種分散式雜湊(DHT)實現演算法,設計目標是為了解決因特網中的熱點(Hot spot)問題,初衷和CARP十分類似。一致性雜湊修正了CARP使用的簡單雜湊演算法帶來的問題,使得分散式雜湊(DHT)可以在P
一致性 hash 演算法( consistent hashing )
1 基本場景 比如你有 N 個 cache 伺服器(後面簡稱 cache ),那麼如何將一個物件 object 對映到 N 個 cache 上呢,你很可能會採用類似下面的通用方法計算 object 的 hash 值,然後均勻的對映到到 N 個 cache hash(obj
一致性 Hash 演算法學習(分散式或均衡演算法)
簡介: 一致性雜湊演算法在1997年由麻省理工學院提出的一種分散式雜湊(DHT)實現演算法,設計目標是為了解決因特網中的熱點(Hot spot)問題,初衷和CARP十分類似。一致性雜湊修正了CARP使用的簡單雜湊演算法帶來的問題,使得分散式雜湊(DHT)可以在P2P環境中真
資料結構和算法系列 - 一致性hash演算法
1 基本場景 比如你有 N 個 cache 伺服器(後面簡稱 cache ),那麼如何將一個物件 object 對映到 N 個 cache 上呢,你很可能會採用類似下面的通用方法計算 object 的 hash 值,然後均勻的對映到到 N 個 cache ; hash(object)%N
深入解讀快取(二)——一致性Hash演算法
上一篇文章中,我們已經介紹了,分散式快取的叢集,與應用伺服器的叢集策略有所不同。分散式快取叢集,每一個節點上快取的資料各不相同。 快取策略 常見的策略有求留餘數法和一致性Hash演算法。 快取的本質是一個記憶體Hash表,網站應用中,資料快取以一對Key、Value的形式
redis叢集方案-一致性hash演算法
前奏 叢集的概念早在 Redis 3.0 之前討論了,3.0 才在原始碼中出現。Redis 叢集要考慮的問題: 節點之間怎麼據的同步,如何做到資料一致性。一主一備的模式,可以用 Redis 內部實現的主從備份實現資料同步。但節點不斷增多,存在多個 master 的時候,
redis 一致性hash演算法
網站為了支撐更大的使用者訪問量,往往需要對使用者訪問的資料做cache,服務機群和負載均衡來專門處理快取,負載均衡的演算法很多,輪循演算法、雜湊演算法、最少連線演算法、響應速度演算法等,hash演算法是比較常用的一種,它的常用思想是先計算出一個hash值,然後使用
redis分散式一致性hash演算法
當我們在部署redis節點時,使用者連結redis儲存資料會通過hash演算法來定位具體連結那個redis節點,在redis節點數量沒有改變的前提下,之前的使用者通過hash演算法會固定的連結某一臺redis節點,但是若此時我們增加了redis節點,使用者再次
一致性hash演算法和redis叢集動態資料儲存
記錄:對一致性Hash演算法,Java程式碼實現的深入研究連結地址: http://www.cnblogs.com/xrq730/p/5186728.html全部來自:https://mp.weixin.qq.com/s/yimfkNYF_tIJJqUIzV7TFAhttps