
redis 一致性hash演算法
快取最關鍵的就是命中率這個因素,如果命中率非常低,那麼快取也就失去了它的意義。如採用一般的CRC取餘的hash演算法雖然能達到負載均衡的目的,但是它存在一個嚴重的問題,那就是如果其中一臺伺服器down掉,那麼就需要在計算快取過程中將這臺伺服器去掉,即N臺伺服器,目前就只有N-1臺提供快取服務,此時需要一個rehash過程,而reash得到的結果將導致正常的使用者請求不能找到原來快取資料的正確機器,其他N-1臺伺服器上的快取資料將大量失效,此時所有的使用者請求全部會集中到資料庫上,嚴重可能導致整個生產環境掛掉.
舉個例子,有5臺伺服器,編號分別是0(A),1(B),2(C),3(D),4(E) ,正常情況下,假設使用者資料hash值為12,那麼對應的資料應該快取在12%5=2號伺服器上,假設編號為3的伺服器此時掛掉,那麼將其移除後就得到一個新的0(A),1(B),2(C),3(E)(注:這裡的編號3其實就是原來的4號伺服器)伺服器列表,此時使用者來取資料,同樣hash值為12,rehash後的得到的機器編號12%4=0號伺服器,可見,此時使用者到0號伺服器去找資料明顯就找不到,出現了cache不命中現象,如果不命中此時應用會從後臺資料庫重新讀取資料再cache到0號伺服器上,如果大量使用者出現這種情況,那麼後果不堪設想。同樣,增加一臺快取伺服器,也會導致同樣的後果。
可以有一種設想,要提高命中率就得減少增加或者移除伺服器rehash帶來的影響,那麼有這樣一種演算法麼?Consistent hashing演算法就是這樣一種hash演算法,簡單的說,在移除/新增一個 cache 時,它能夠儘可能小的改變已存在 key 對映關係,儘可能的滿足單調性的要求。
1.環形Hash空間
按照常用的hash演算法來將對應的key雜湊到一個具有2^32個桶的空間中,即0~(2^32)-1的數字空間中。可以將這些數字頭尾相連,想象成一個閉合的環形。如下圖:

2.把資料通過一定的hash演算法處理後對映到環上
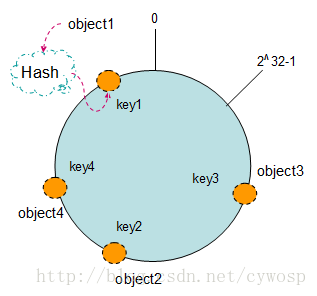
現在將object1、object2、object3、object4四個物件通過特定的Hash函式計算出對應的key值,然後雜湊到Hash環上。如下圖:
Hash(object1) = key1;
Hash(object2) = key2;
Hash(object3) = key3;
Hash(object4) = key4;
3.將機器通過hash演算法對映到環上
在採用一致性雜湊演算法的分散式叢集中將新的機器加入,其原理是通過使用與物件儲存一樣的Hash演算法將機器也對映到環中(一般情況下對機器的hash計算是採用機器的IP或者機器唯一的別名作為輸入值),然後以順時針的方向計算,將所有物件儲存到離自己最近的機器中。
假設現在有NODE1,NODE2,NODE3三臺機器,通過Hash演算法得到對應的KEY值,對映到環中,其示意圖如下:
Hash(NODE1) = KEY1;
Hash(NODE2) = KEY2;
Hash(NODE3) = KEY3;
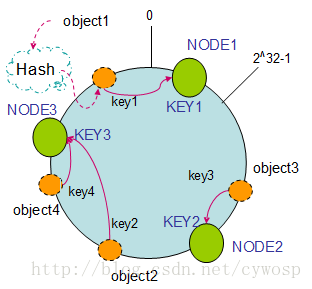
通過上圖可以看出物件與機器處於同一雜湊空間中,這樣按順時針轉動object1儲存到了NODE1中,object3儲存到了NODE2中,object2、object4儲存到了NODE3中。在這樣的部署環境中,hash環是不會變更的,因此,通過算出物件的hash值就能快速的定位到對應的機器中,這樣就能找到物件真正的儲存位置了。
4.機器的刪除與新增
普通hash求餘演算法最為不妥的地方就是在有機器的新增或者刪除之後會照成大量的物件儲存位置失效,這樣就大大的不滿足單調性了。下面來分析一下一致性雜湊演算法是如何處理的。
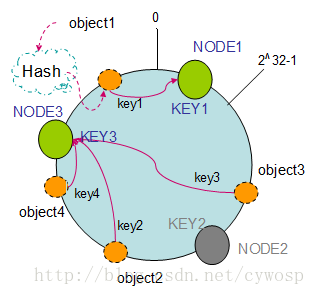
1. 節點(機器)的刪除
以上面的分佈為例,如果NODE2出現故障被刪除了,那麼按照順時針遷移的方法,object3將會被遷移到NODE3中,這樣僅僅是object3的對映位置發生了變化,其它的物件沒有任何的改動。如下圖:
2. 節點(機器)的新增
如果往叢集中新增一個新的節點NODE4,通過對應的雜湊演算法得到KEY4,並對映到環中,如下圖:
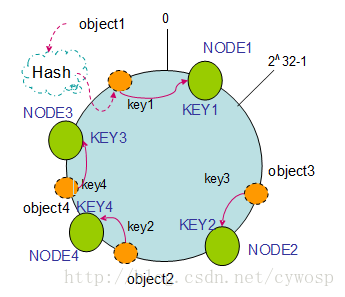
通過按順時針遷移的規則,那麼object2被遷移到了NODE4中,其它物件還保持這原有的儲存位置。通過對節點的新增和刪除的分析,一致性雜湊演算法在保持了單調性的同時,還是資料的遷移達到了最小,這樣的演算法對分散式叢集來說是非常合適的,避免了大量資料遷移,減小了伺服器的的壓力。
5.平衡性
根據上面的圖解分析,一致性雜湊演算法滿足了單調性和負載均衡的特性以及一般hash演算法的分散性,但這還並不能當做其被廣泛應用的原由,因為還缺少了平衡性。下面將分析一致性雜湊演算法是如何滿足平衡性的。
hash演算法是不保證平衡的,如上面只部署了NODE1和NODE3的情況(NODE2被刪除的圖),object1儲存到了NODE1中,而object2、object3、object4都儲存到了NODE3中,這樣NODE3節點由於承擔了NODE2節點的資料,所以NODE3節點的負載會變高,NODE3節點很容易也宕機,這樣依次下去可能造成整個叢集都掛了。
在一致性雜湊演算法中,為了儘可能的滿足平衡性,其引入了虛擬節點。“虛擬節點”( virtual node )是實際節點(機器)在 hash 空間的複製品(replica),一實際個節點(機器)對應了若干個“虛擬節點”,這個對應個數也成為“複製個數”,“虛擬節點”在 hash 空間中以hash值排列。即把想象在這個環上有很多“虛擬節點”,資料的儲存是沿著環的順時針方向找一個虛擬節點,每個虛擬節點都會關聯到一個真實節點。
圖中的A1、A2、B1、B2、C1、C2、D1、D2都是虛擬節點,機器A負載儲存A1、A2的資料,機器B負載儲存B1、B2的資料,機器C負載儲存C1、C2的資料。由於這些虛擬節點數量很多,均勻分佈,因此不會造成“雪崩”現象。
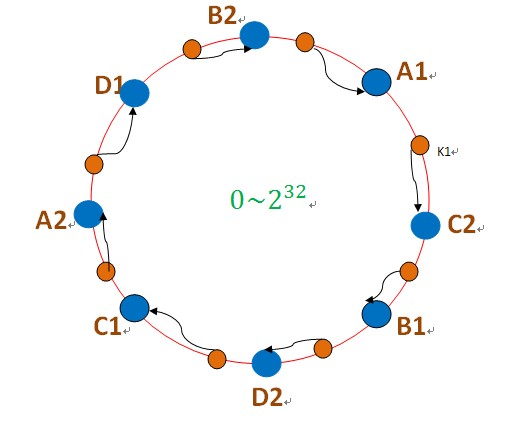
使用虛擬節點的思想,為每個物理節點(伺服器)在圓上分配100~200個點。這樣就能抑制分佈不均勻,最大限度地減小伺服器增減時的快取重新分佈。使用者資料對映在虛擬節點上,就表示使用者資料真正儲存位置是在該虛擬節點代表的實際物理伺服器上。
下面有一個圖描述了需要為每臺物理伺服器增加的虛擬節點。
x軸表示的是需要為每臺物理伺服器擴充套件的虛擬節點倍數(scale),y軸是實際物理伺服器數,可以看出,當物理伺服器的數量很小時,需要更大的虛擬節點,反之則需要更少的節點,從圖上可以看出,在物理伺服器有10臺時,差不多需要為每臺伺服器增加100~200個虛擬節點才能達到真正的負載均衡。
public class ConsistentHash<T> {
/**
* 雜湊函式
*/
private final HashFunction hashFunction;
/**
* 虛擬節點數 , 越大分佈越均衡,但越大,在初始化和變更的時候效率差一點。 測試中,設定200基本就均衡了。
*/
private final int numberOfReplicas;
/**
* 環形Hash空間
*/
private final SortedMap<Integer, T> circle = new TreeMap<Integer, T>();
/**
* @param hashFunction
* ,雜湊函式
* @param numberOfReplicas
* ,虛擬伺服器係數
* @param nodes
* ,伺服器節點
*/
public ConsistentHash(HashFunction hashFunction, int numberOfReplicas,
Collection<T> nodes) {
this.hashFunction = hashFunction;
this.numberOfReplicas = numberOfReplicas;
for (T node : nodes) {
this.addNode(node);
}
}
/**
* 新增物理節點,每個node 會產生numberOfReplicas個虛擬節點,這些虛擬節點對應的實際節點是node
*/
public void addNode(T node) {
for (int i = 0; i < numberOfReplicas; i++) {
int hashValue = hashFunction.hash(node.toString() + i);
circle.put(hashValue, node);
}
}
/**移除物理節點,將node產生的numberOfReplicas個虛擬節點全部移除
* @param node
*/
public void removeNode(T node) {
for (int i = 0; i < numberOfReplicas; i++) {
int hashValue = hashFunction.hash(node.toString() + i);
circle.remove(hashValue);
}
}
/**
* 得到對映的物理節點
*
* @param key
* @return
*/
public T getNode(Object key) {
if (circle.isEmpty()) {
return null;
}
int hashValue = hashFunction.hash(key);
// System.out.println("key---" + key + " : hash---" + hash);
if (!circle.containsKey(hashValue)) {
// 返回鍵大於或等於hash的node,即沿環的順時針找到一個虛擬節點
SortedMap<Integer, T> tailMap = circle.tailMap(hashValue);
// System.out.println(tailMap);
// System.out.println(circle.firstKey());
hashValue = tailMap.isEmpty() ? circle.firstKey() : tailMap.firstKey();
}
// System.out.println("hash---: " + hash);
return circle.get(hashValue);
}
static class HashFunction {
/**
* MurMurHash演算法,是非加密HASH演算法,效能很高,
* 比傳統的CRC32,MD5,SHA-1(這兩個演算法都是加密HASH演算法,複雜度本身就很高,帶來的效能上的損害也不可避免)
* 等HASH演算法要快很多,而且據說這個演算法的碰撞率很低. http://murmurhash.googlepages.com/
*/
int hash(Object key) {
ByteBuffer buf = ByteBuffer.wrap(key.toString().getBytes());
int seed = 0x1234ABCD;
ByteOrder byteOrder = buf.order();
buf.order(ByteOrder.LITTLE_ENDIAN);
long m = 0xc6a4a7935bd1e995L;
int r = 47;
long h = seed ^ (buf.remaining() * m);
long k;
while (buf.remaining() >= 8) {
k = buf.getLong();
k *= m;
k ^= k >>> r;
k *= m;
h ^= k;
h *= m;
}
if (buf.remaining() > 0) {
ByteBuffer finish = ByteBuffer.allocate(8).order(
ByteOrder.LITTLE_ENDIAN);
finish.put(buf).rewind();
h ^= finish.getLong();
h *= m;
}
h ^= h >>> r;
h *= m;
h ^= h >>> r;
buf.order(byteOrder);
return (int) h;
}
}
}
public class Test {
public static void main(String[] args) {
HashSet<String> serverNode = new HashSet<String>();
serverNode.add("127.1.1.1#A");
serverNode.add("127.2.2.2#B");
serverNode.add("127.3.3.3#C");
serverNode.add("127.4.4.4#D");
Map<String, Integer> serverNodeMap = new HashMap<String, Integer>();
ConsistentHash<String> consistentHash = new ConsistentHash<String>(
new HashFunction(), 200, serverNode);
int count = 50000;
for (int i = 0; i < count; i++) {
String serverNodeName = consistentHash.getNode(i);
// System.out.println(i + " 對映到物理節點---" + serverNodeName);
if (serverNodeMap.containsKey(serverNodeName)) {
serverNodeMap.put(serverNodeName,
serverNodeMap.get(serverNodeName) + 1);
} else {
serverNodeMap.put(serverNodeName, 1);
}
}
// System.out.println(serverNodeMap);
showServer(serverNodeMap);
serverNodeMap.clear();
consistentHash.removeNode("127.1.1.1#A");
System.out.println("-------------------- remove 127.1.1.1#A");
for (int i = 0; i < count; i++) {
String serverNodeName = consistentHash.getNode(i);
// System.out.println(i + " 對映到物理節點---" + serverNodeName);
if (serverNodeMap.containsKey(serverNodeName)) {
serverNodeMap.put(serverNodeName,
serverNodeMap.get(serverNodeName) + 1);
} else {
serverNodeMap.put(serverNodeName, 1);
}
}
showServer(serverNodeMap);
serverNodeMap.clear();
consistentHash.addNode("127.5.5.5#E");
System.out.println("-------------------- add 127.5.5.5#E");
for (int i = 0; i < count; i++) {
String serverNodeName = consistentHash.getNode(i);
// System.out.println(i + " 對映到物理節點---" + serverNodeName);
if (serverNodeMap.containsKey(serverNodeName)) {
serverNodeMap.put(serverNodeName,
serverNodeMap.get(serverNodeName) + 1);
} else {
serverNodeMap.put(serverNodeName, 1);
}
}
showServer(serverNodeMap);
serverNodeMap.clear();
consistentHash.addNode("127.6.6.6#F");
System.out.println("-------------------- add 127.6.6.6#F");
count *= 2;
System.out.println("-------------------- 業務量加倍");
for (int i = 0; i < count; i++) {
String serverNodeName = consistentHash.getNode(i);
// System.out.println(i + " 對映到物理節點---" + serverNodeName);
if (serverNodeMap.containsKey(serverNodeName)) {
serverNodeMap.put(serverNodeName,
serverNodeMap.get(serverNodeName) + 1);
} else {
serverNodeMap.put(serverNodeName, 1);
}
}
showServer(serverNodeMap);
}
/**
* 伺服器執行狀態
*
* @param map
*/
public static void showServer(Map<String, Integer> map) {
for (Entry<String, Integer> m : map.entrySet()) {
System.out.println(m.getKey() + ", 儲存資料量 " + m.getValue());
}
}
}
127.4.4.4#D, 儲存資料量 13177
127.2.2.2#B, 儲存資料量 11834
127.3.3.3#C, 儲存資料量 12827
127.1.1.1#A, 儲存資料量 12162
-------------------- remove 127.1.1.1#A
127.4.4.4#D, 儲存資料量 17696
127.2.2.2#B, 儲存資料量 15114
127.3.3.3#C, 儲存資料量 17190
-------------------- add 127.5.5.5#E
127.4.4.4#D, 儲存資料量 12154
127.2.2.2#B, 儲存資料量 11878
127.3.3.3#C, 儲存資料量 12908
127.5.5.5#E, 儲存資料量 13060
-------------------- add 127.6.6.6#F
-------------------- 業務量加倍
127.4.4.4#D, 儲存資料量 18420
127.2.2.2#B, 儲存資料量 20197
127.6.6.6#F, 儲存資料量 21015
127.5.5.5#E, 儲存資料量 19038
127.3.3.3#C, 儲存資料量 21330