
pytorch 學習(1:introduction)
學習:https://morvanzhou.github.io/tutorials/machine-learning/torch/
筆記
=============================== (1.1)簡單引入 ====================================
1.torch numpy 相互轉化
torch_data = torch.from_numpy(np_data)
tensor2array = torch_data.numpy()2.torch數學計算
torch.sin(), torch.mean()...
#tensor乘法
torch.mm(a,b)
3.把資料轉化為32位浮點數
torch.FloatTensor(data) ================================== (1.2)Variable ================================================
莫煩很好地將Tensor比作雞蛋,Variable比作雞蛋籃子
import torch from torch.autograd import Variable # torch 中 Variable 模組 # 先生雞蛋 tensor = torch.FloatTensor([[1,2],[3,4]]) # 把雞蛋放到籃子裡, requires_grad是參不參與誤差反向傳播, 要不要計算梯度 variable = Variable(tensor, requires_grad=True)
Variable 計算時, 它在背景幕布後面一步步默默地搭建著一個龐大的系統, 叫做計算圖, computational graph. 這個圖是用來幹嘛的? 原來是將所有的計算步驟 (節點) 都連線起來, 最後進行誤差反向傳遞的時候, 一次性將所有 variable 裡面的修改幅度 (梯度) 都計算出來, 而 tensor 就沒有這個能力啦.
v_out = torch.mean(variable*variable) # x^2v_out.backward() # 模擬 v_out 的誤差反向傳遞 # 下面兩步看不懂沒關係, 只要知道 Variable 是計算圖的一部分, 可以用來傳遞誤差就好. # v_out = 1/4 * sum(variable*variable) 這是計算圖中的 v_out 計算步驟 # 針對於 v_out 的梯度就是, d(v_out)/d(variable) = 1/4*2*variable = variable/2
#如果想輸出variable裡的tensor: variable.data
============================= (1.3)activation function =======================================
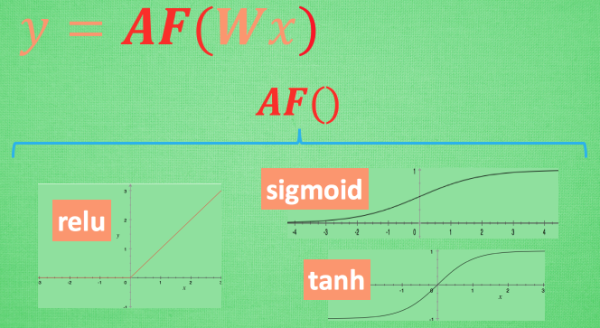
莫煩工程上的竅門
“
想要恰當使用這些激勵函式, 還是有竅門的. 比如當你的神經網路層只有兩三層, 不是很多的時候, 對於隱藏層, 使用任意的激勵函式, 隨便掰彎是可以的, 不會有特別大的影響. 不過, 當你使用特別多層的神經網路, 在掰彎的時候, 玩玩不得隨意選擇利器. 因為這會涉及到梯度爆炸, 梯度消失的問題. 因為時間的關係, 我們可能會在以後來具體談談這個問題.
最後我們說說, 在具體的例子中, 我們預設首選的激勵函式是哪些. 在少量層結構中, 我們可以嘗試很多種不同的激勵函式. 在卷積神經網路 Convolutional neural networks 的卷積層中, 推薦的激勵函式是 relu. 在迴圈神經網路中 recurrent neural networks, 推薦的是 tanh 或者是 relu (這個具體怎麼選, 我會在以後 迴圈神經網路的介紹中在詳細講解).
”
import torch.nn.functional as F # 激勵函式都在這
# 做一些假資料來觀看影象
x = torch.linspace(-5, 5, 200) # x data (tensor), shape=(100, 1)
x = Variable(x)
# 幾種常用的 激勵函式
y_relu = F.relu(x).data.numpy()
y_sigmoid = F.sigmoid(x).data.numpy()
y_tanh = F.tanh(x).data.numpy()
y_softplus = F.softplus(x).data.numpy()
# y_softmax = F.softmax(x) softmax 比較特殊, 不能直接顯示, 不過他是關於概率的, 用於分類