Single-Shot Object Detection with Enriched Semantics
整合一下能夠查到的資料,然後結合自己的理解,算是對這篇文章的一個小小的總結吧。這是CVPR2018的一篇關於小目標檢測的文章,出發點是作者認為小目標的檢測資訊隨著層數的增加而不斷地丟失了,所以想利用語義分割強化淺層的特徵資訊(這裡強化可能用得不準確,但是我是這麼理解的)。整體的網路框架分為三個部分Detection Branch (這裡簡稱DB)+ Segmentation Module (這裡簡稱SM)+ Global Activation Module(這裡簡稱GAM)。SM和GAM本質上都是採用的語義分割的方式增強語義資訊並且隨著SSD往更高層進行傳遞。
整體結構框圖:
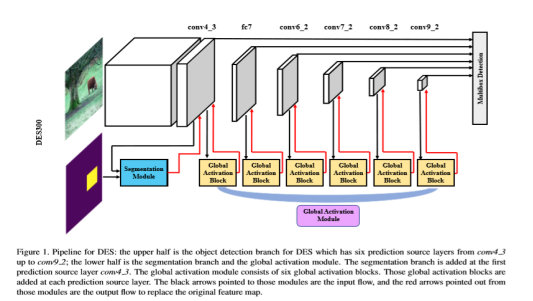
操作過程以DB為主框架:1、在淺層網路中選擇SM增強low level特徵的語義資訊。SM模組的輸入是DB主框架的con4_3輸出以及用anchor定義的語義分割ground truth, 輸出再返回到con4_3作為下一層的輸入,這樣就可以將低層的語義分割結果融合到高層特徵資訊中。2、高層通過GAM增強high level的特徵語義資訊,GAM本質上也就是attention的思想,首先計算特徵權重然後根據權重來融合多尺度的特徵資訊。
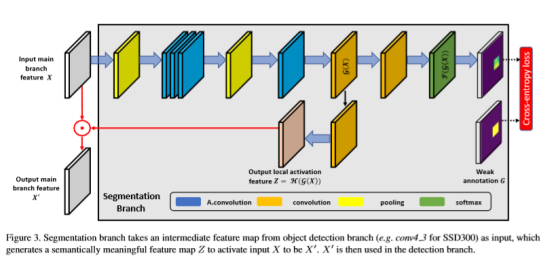
SM模組是這篇論文中重點強調的一個模組,這個部分主要有兩個作用,通俗點理解就是產生增強的語義資訊並且通過訓練使得輸出的語義資訊增強效果越來越好。其中H支路是輸入x在經過4個atrous convolution(既保證了特徵圖的尺寸不變,也能減少卷積過程中的噪聲)卷積之後經過H()函式操作得到類似attention中的mask z,最後x與z做點乘得到,且以為後續檢測工作的輸入。F支路的作用是利用損失函式訓練H支路得到的attention,和分割演算法類似,分割演算法是針對每個畫素點做分類,在F支路中訓練所用的ground truth中的每個畫素點的標籤為對應ground truth框的標籤,如果一個畫素點同時在多個ground truth框中,則該點的標籤為面積最小的那個框的標籤,其他情況的點標籤都是背景。
網上有一大堆對於sm模組的公式分析,關於通道數以及維度之類的,個人覺得文章中提到的一大串公式裡,最能體現出和語義分割關係的是公式:
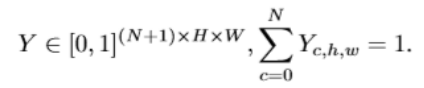
F支路最後的輸出Y中每個點的通道數為N+1,這裡的特徵投影中每個點在所有的channel上的累加和為1,而且值最大的那個點對應的標籤就是分割得到的影象中對應點的標籤。

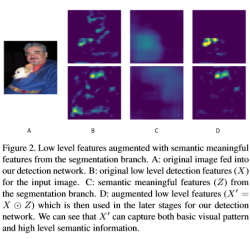
圖4表示ground truth的生成方式,影象中畫素的標籤不需要額外再標註,圖2表示segmentation module,A是輸入影象,B是輸出影象經過特徵提取之後的feature map,C是對應的輸出Z,D是B和C點乘之後的結果,也就是文章強調的需要增強的小目標的語義特徵。
由GAM模組的計算公式就可以很直觀的看出來和語義分割非常像,這個模組主要包含三個操作:spatial pooling相當於給輸入的特徵圖做了歸一化處理,而channel-wise learning則是利用兩層啟用函式突顯了特徵圖的權重資訊,最後的broadcasted multiplying將S和輸入x點乘得到最後的輸出,類似於attention的思想。
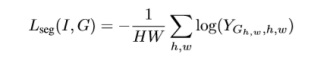
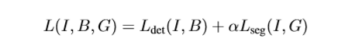
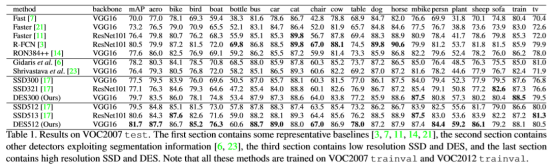
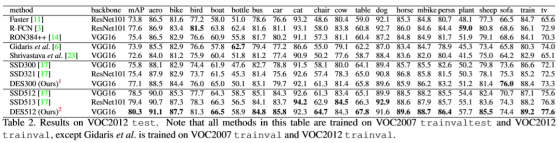
整個損失函式包括檢測的損失函式和分割損失函式,分割的損失函式就是文章設計的SM模組中的訓練損失函式。整體實驗效果雖然比同年CVPR的另外一篇文章低一點,但是結果還是很好的。