
Few-shot Object Detection via Feature Reweighting (ICCV2019)
論文:https://arxiv.org/abs/1812.01866
程式碼:https://github.com/bingykang/Fewshot_Detection
1.研究背景
深度卷積神經網路最近在目標檢測方面的成功很大程度上依賴於大量帶有準確邊界框標註的訓練資料。當標記資料不足時,CNNs會嚴重過度擬合而不能泛化。計算機視覺系統需要從少量樣本中進行檢測的學習能力,因為一些物件類別天生就樣本稀缺,或者很難獲得它們的註釋。
這種只有少量樣本的檢測稱為few-shot目標檢測問題。獲得一個few-shot的檢測模型對許多應用都是有用的。然而,目前任然缺乏有效的方法。最近,元學習為類似的問題提供了很多可行的解決方案。但是目前的一些模型都是用於few-shot分類,而目標檢測在本質上要困難得多,因為它不僅涉及到類的預測,還涉及到目標的定位,因此現成的few-shot分類方法不能直接應用於few-shot檢測問題。以匹配網路和原型網路為例,由於影象中可能存在無關類的分散注意力的物件或根本沒有目標物件,如何構建匹配和定位的物件原型還不清楚。
2.本文解決方案
本文提出了一種新的檢測模型,該模型通過充分利用一些基類的檢測訓練資料,並根據幾個support examples快速調整檢測預測網路來預測新的類,從而提供few-shot的學習能力。提出的模型首先從基類中學習元特徵,這些基類可泛化為檢測不同的物件類。然後利用一些support examples有效地識別出對檢測新類有重要區別意義的元特徵,並相應地將檢測知識從基類轉移到新類。
因此,本文的模型引入了一個新的檢測框架(如圖2所示),包含兩個模組,即,元特徵學習器和輕量級特徵權重調整模組。給出一個query image和一些新類的support images,特徵學習器從query image中提取元特徵。權重調整模組學習捕獲support images的全域性特徵,並將其嵌入到權重調整係數中,以調整query image的元特徵。因此,query image的元特徵能夠有效地接收支援資訊,並適應於新類的檢測。然後自適應的元特徵被送入檢測預測模組中預測query的類和邊界框。
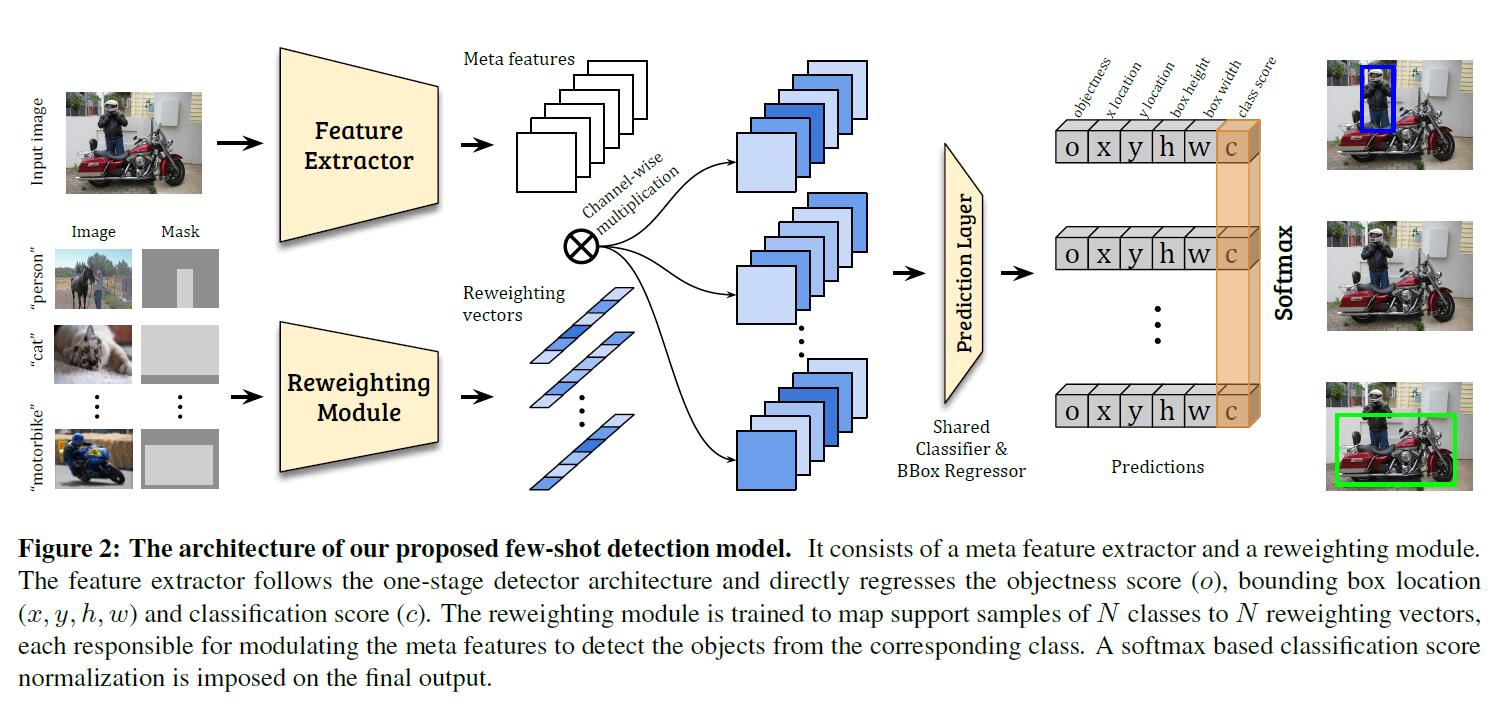
對元特徵學習器和加權模組以及檢測預測模組進行端到端的訓練。為了保證few-shot的泛化能力,採用兩階段學習方案對整個few-shot檢測模型進行訓練:首先從基類中學習元特徵和良好的權值調整模組;然後對檢測模型進行微調以適應新的類。為了解決檢測學習中的困難(例如,存在分散注意力的物件),它引入了一個新的損失函式。
3.方案具體實施
關於資料集
本文針對few-shot目標檢測,設定了兩種資料,即,基類和新類。基類包含豐富的帶標籤的樣本,而新類只有少數帶標籤的樣本。目標是通過利用基類的先驗知識,使得模型能夠在測試中檢測新類的目標。
關於模型
該模型將元特徵學習器D和權重調整模組M引入到一個one-stage檢測框架中。通過檢測預測模組P,將每個anchor的特徵直接回歸到檢測相關輸出,包括分類得分和目標邊界框座標(如圖2所示)。模型採用YOLOv2的backbone(DarkNet-19)作為元特徵提取器D,並遵循與YOLOv2相同的anchor設定。對於權重調整模組M,模型採用一個輕量級的CNN。
具體來說,讓I表示一個輸入的影象。其對應的元特徵由D產生;F=D(I)。生成的元特徵有m個特徵對映。我們將表示要檢測的目標類的support images及其相關的邊界框註釋分別表示為Ii和Mi(i表示不同的類,i = 1,…,N)。權重調整模組M以一個支援影象(Ii, Mi)為輸入,將其嵌入到一個類特定的表示向量wi=M(Ii, Mi),它將負責調整元特徵的權重,並突出更重要、更相關的特徵,以檢測來自類i的目標物件。具體來說,模型在獲得類特定的權重係數wi後,通過以下方式應用它來獲得新類i的特定特徵Fi:

在獲得類特定的特徵Fi之後,我們將它們輸入到預測模組P中,對每個預定義anchor的目標度評分o、bbox位置偏移量(x、y、h、w)和分類分數ci進行迴歸:

其中ci為one-vs-all分類得分,表示對應物件屬於第i類的概率。
訓練方法
訓練分為兩個階段,第一階段是基礎訓練階段。在這個階段,雖然每個基類都有豐富的標籤,但是我們仍然會聯合訓練元特徵學習器D,檢測預測模組P和權重調整模組M。這是為了使它們以期望的方式進行協調:模型需要通過引用一個良好的重權向量來學習檢測感興趣的物件。第二階段是少few-shot微調。在這個階段,對模型進行基類和新類的聯合訓練。由於只有k個標記的邊界框可用於新類,為了平衡來自基類和新類的樣本,每個基類也只能包含k個box。訓練過程與第一階段相同,不同之處在於,模型收斂所需的迭代次數明顯減少。
損失函式
損失函式為:

其中,

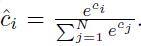
Lbbx和Lobj按照YOLOv2相同的計算方式。
4.實驗過程和結果分析
實驗在Pascal VOC和COCO上分別進行了實驗,實驗對比了5個不同的baseline模型,結果分別如表1、表2所示:


比較結果分析
1) 本文模型表現都要好於其他模型
2) 本文所提出的二階段的訓練方式要優於一階段的方式
3) 本文模型在各種不同的類別劃分下表現都要優於其他模型
速度分析
如圖3所示,本文模型在微調階段的收斂速度明顯好於其他模型

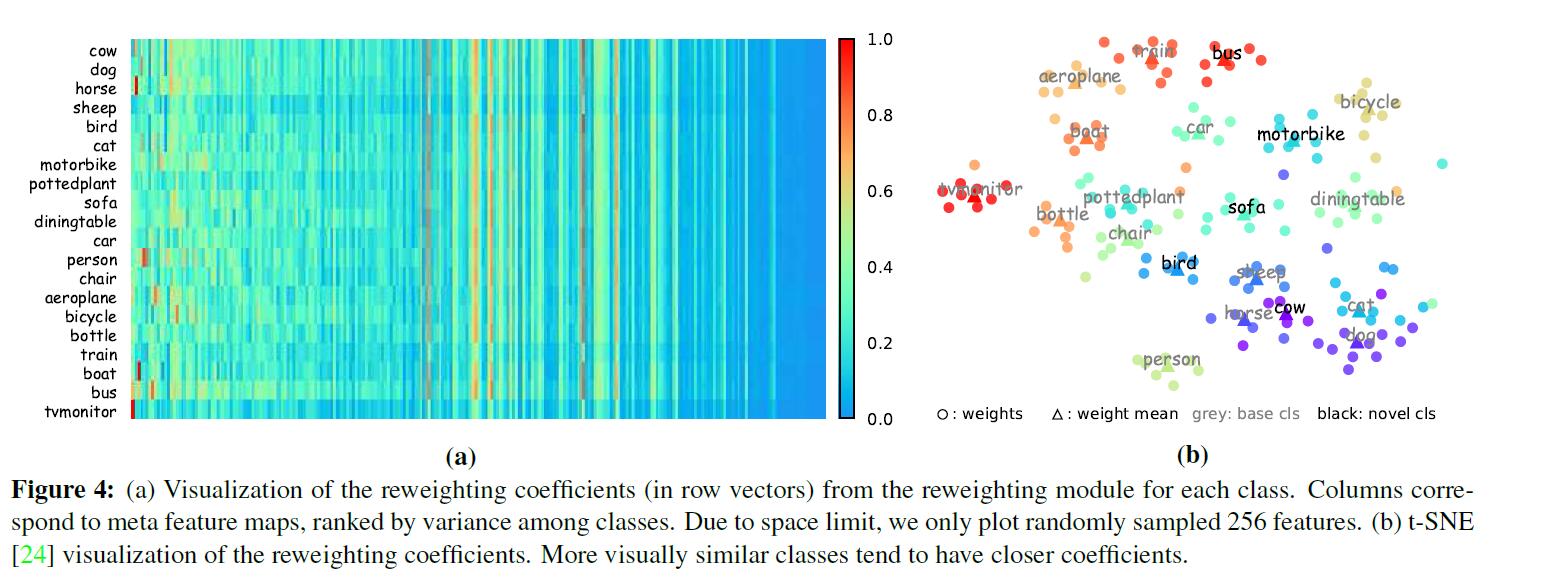
元特徵權值分析
圖4(a)所示,各個元特徵在不同類目標中的權值不同,但其中有大約一半的特徵在各個類中權重差不多,即,這些特徵對於檢測分類的重要性是極小的。
圖4(b)所示,將各個目標的加權向量視覺化,可以發現,同類目標的向量權值是十分接近的,而不同類目標,若是外形相似,其向量權值也比較接近,也就是說各個元特徵在這些目標中的重要性很接近。
第一階段過程分析
比較第一階段訓練後得到的模型在基類上的對映。結果如表3所示。儘管本文的檢測器是為few-shot場景設計的,但它也具有強大的表示能力,以達到與在大量樣本上訓練的原始YOLOv2檢測器相當的效能。

消融實驗
作者分別進行了3個實驗,首先是在特徵圖的不同層上進行加權,結果如表4所示,在越深的層上進行加權效果越好。

其次,採用不同的損失函式,結果如表5所示,在3種損失函式中,softmax的效果最好。

最後,support images選擇不同輸入形式,結果如表6所示,本文提出的對目標用mask進行標註的方式效果最好。

5.總結
這項工作是第一個探索實際和具有挑戰性的few-shot目標檢測問題。通過例項介紹了一種快速調整基本特徵的貢獻來檢測新類的新模型。在實際基準資料集上的實驗清楚地證明了它的有效性。該工作還比較了模型的學習速度,分析了預測的權重向量和每個設計元件的貢獻,對所提出的模型提供了深入的理解