
Swaggy教你用python實現NBA資料統計的爬取
阿新 • • 發佈:2018-12-31
相信很多喜歡NBA的小夥伴們經常會關注NBA的資料統計,今天我就用虎撲NBA的得分榜為例,實現NBA資料的簡單爬取。
https://nba.hupu.com/stats/players是虎撲體育的NBA球員得分榜:
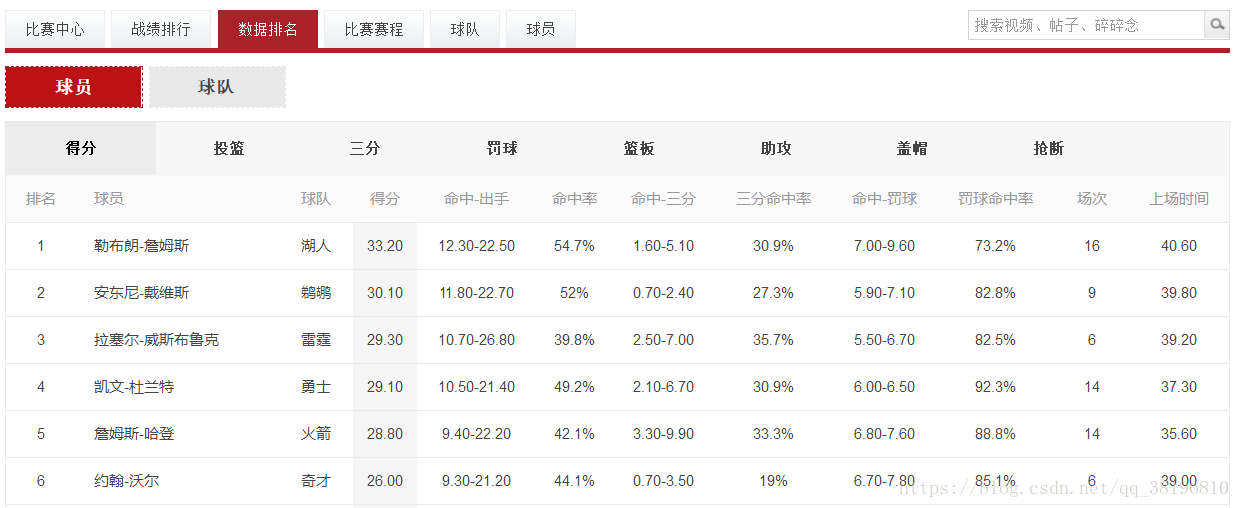
當我們右鍵檢視該網站的原始碼時,會發現所有的資料統計都存放在<tbody>的標籤下,而<tbody>下的每個<tr>標籤則表示每個球員的資訊,第1、2、4個<td>標籤分別表示球員排名、球員名字和得分。
eg.
| <tr> |
| <td width="46">1</td> |
| <td class="bg_b">33.20</td> |
| <td>12.30-22.50</td> |
| <td>54.7%</td> |
| <td>1.60-5.10</td> |
| <td>30.9%</td> |
| <td>7.00-9.60</td> |
| <td>73.2%</td> |
| <td width="50">16</td> |
| <td width="70">40.60</td> |
| </tr> |
運用requests庫和bs4庫,我們可以將球員的資料爬取下來。
首先,我們編寫一個getHTMLText方法,用於爬取網頁的資訊:
def getHTMLText(url):
try:
r = requests.get(url, timeout=30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return "" 其次,我們編寫一個fillList方法。
因為所有的資料統計都存放在<tbody>的標籤下,而<tbody>下的每個<tr>標籤則表示每個球員的資訊,第1、2、4個<td>標籤分別表示球員排名、球員名字和得分,我們採用html.parser直譯器,遍歷<tbody>標籤的所有兒子節點,將球員資料的第1、2、4個<td>標籤新增至列表中即可:
def fillList(ulist, html):
soup = BeautifulSoup(html, "html.parser")
for tr in soup.find('tbody').children:
if isinstance(tr, bs4.element.Tag):
tds = tr('td')
ulist.append([tds[0].string, tds[1].string, tds[3].string]) 最後,我們編寫printList方法,將列表中的資料依次輸出:
def printUnivList(ulist, num):
for i in range(num):
u = ulist[i]
print("{0:<6}\t{1:{3}<10}\t{2:<6}".format(u[0],u[1],u[2],chr(12288)))將以上方法組合編寫主函式如下:
def main():
uinfo = []
url = 'http://nba.hupu.com/stats/players'
html = getHTMLText(url)
fillList(uinfo, html)
printList(uinfo, 21)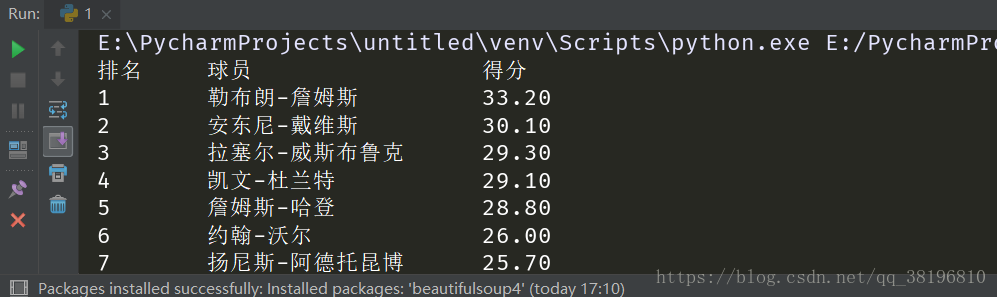 是不是很簡單呢?趕緊上手嘗試一下吧(手動滑稽)
是不是很簡單呢?趕緊上手嘗試一下吧(手動滑稽)