
使用Impala合併小檔案
1.文件編寫目的
Fayson在前面的文章《如何在Hadoop中處理小檔案》裡面介紹了多種處理方式。在Impala表中使用小檔案也會降低Impala和HDFS的效能,本篇文章Fayson主要介紹如何使用Impala合併小檔案。
-
內容概述
1.環境準備
2.Impala合併小檔案實現
3.驗證小檔案是否合併
-
測試環境說明
1.CM5.15.0和CDH5.14.2
2.環境準備
在這裡測試Fayson準備了4張表,兩個有資料的表ods_user和ods_user_256表,ods_user表的資料量大於Impala預設的Block(256MB)大小,ods_user_256表的資料量小於Impala預設的Block大小。
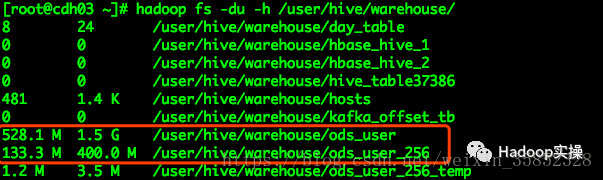
1.準備一個測試表ods_user,該表中有888個小檔案,如下截圖所示
命令列檢視該表下的資料檔案:
[[email protected] ~]# hadoop fs -ls /user/hive/warehouse/ods_user |wc -l [[email protected] ~]# hadoop fs -du -h /user/hive/warehouse/ods_user |more
(可左右滑動)
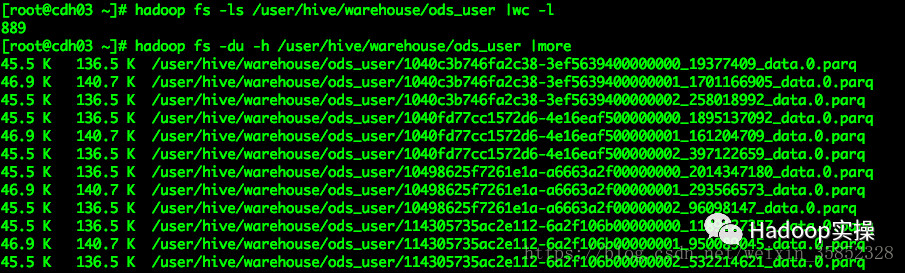
2. 準備測試表ods_user_256,該表有7個小檔案,如下截圖所示:

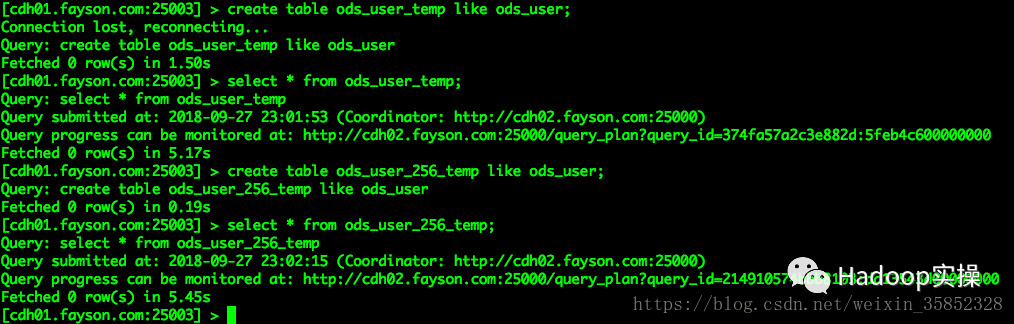
3.使用建表語句建立2個與ods_user表結構一致的表ods_user_temp和ods_user_256_temp
[cdh01.fayson.com:25003] > create table ods_user_temp like ods_user; [cdh01.fayson.com:25003] > select * from ods_user_temp; [cdh01.fayson.com:25003] > create table ods_user_256_temp like ods_user; [cdh01.fayson.com:25003] > select * from ods_user_256_temp;
(可左右滑動)
3.Impala合併小於Impala Block的小檔案
1.執行如下指令碼將ods_user_256表中的資料寫入到ods_user_256_temp表中
[cdh01.fayson.com:25003] > insert overwrite table ods_user_256_temp select * from ods_user_256;
(可左右滑動)

檢視ods_user_256_temp表資料檔案數量
[[email protected] ~]# hadoop fs -du -h /user/hive/warehouse/ods_user_256_temp
(可左右滑動)

上圖可以看到檔案數量由原表的7個減少到3個但還是生成了多個小檔案,這裡應該跟Impala節點數有關。
2.將ods_user_256_temp表中的資料再寫回ods_user_256表中,注意在這一步Fayson會進行小檔案合併操作,具體執行命令如下
[cdh01.fayson.com:25003] > set NUM_NODES=1;
[cdh01.fayson.com:25003] > insert overwrite table ods_user_256 select * from ods_user_256_temp;
(可左右滑動)

在命令列檢視ods_user_256表資料檔案數量
[[email protected] ~]# hadoop fs -du -h /user/hive/warehouse/ods_user_256
(可左右滑動)

由上圖可以看到ods_user_256表的檔案數量被合併為1個了。
4.Impala合併大於Impala Block的小檔案
1.執行如下指令碼將ods_user表中的資料寫入到ods_user_temp表中
[cdh01.fayson.com:25003] > insert overwrite table ods_user_temp select * from ods_user;
(可左右滑動)

檢視ods_user_temp表資料檔案數量
[[email protected] ~]# hadoop fs -du -h /user/hive/warehouse/ods_user_temp
(可左右滑動)

2.將ods_user_temp表中的資料再寫回ods_user表中,注意在這一步Fayson會進行小檔案合併操作,具體執行命令如下
[cdh01.fayson.com:25003] > set NUM_NODES=1;
[cdh01.fayson.com:25003] > insert overwrite table ods_user select * from ods_user_temp;
(可左右滑動)

在命令列檢視ods_user表資料檔案數量
[[email protected] ~]# hadoop fs -du -h /user/hive/warehouse/ods_user
(可左右滑動)

由上圖可以看到ods_user表生成了多個檔案,但每個檔案的大小在Impala預設的block大小範圍內。
5.總結
1.在設定了NUM_NODES=1後,如果合併的資料量超過Impala預設的Parquet Block Size(256MB)大小時會生成多個檔案,每個檔案的大小在256MB左右,如果合併的資料量小於256MB則最終只會生成一個檔案。
2.通過設定NUM_NODES=1強制Impala使用一個節點Daemon來處理整個Query,因此最終只會輸出一個檔案到HDFS。
3.在使用該配置項時會引起單個主機的資源利用率增加,導致SQL執行緩慢,超出記憶體限制或查詢掛起等。
4.該引數沒辦法設定超過1,即無論你有多少臺機器,多大資料量,想使用該方法,也只能設定為1,讓一臺機器來慢慢幫你合併檔案,所以該方法不是太實用,僅供參考。
6.備註:NUM_NODES引數說明
該引數用來限制執行查詢作業的節點數,常見的場景是用於除錯/debug查詢的時候。它是一個數值型別,但只有兩個值,預設是0即使用所有節點來執行查詢,也可以設定為1即所有的查詢子任務都會在coordinator節點上個執行。
如果你在除錯某個查詢作業,懷疑是因為分散式計算才導致的執行時間較長,可以將NUM_NODES設定為1,從而可以校驗同樣的作業在單個節點上執行時是否問題依舊存在。當然也可以在執行INSERT或者CREATE TABLE AS SELECT加上這個引數的設定來解決小檔案的問題,也即是本篇文章正文所分析的內容。
注意:設定該引數會導致單臺節點資源使用增加,從而影響叢集上別的查詢作業比如導致執行緩慢,hang住或者OOM。所以建議在開發/測試環境中使用,或者如果你的生產系統不是太繁忙的時候使用。