
機器學習術語通俗易懂的解釋
人工智慧是基於資料做出判斷和預測,機器學習能夠讓計算機實現資料驅動的決策,但是目前機器學習很多演算法名詞非常複雜,本文試圖用淺顯易懂的語言解釋機器學習領域的相關術語.
監督學習Supervised Learning
讓程式首先基於預先定義的資料集進行訓練,離開這些訓練資料以後,這個程式還能基於新的資料進行精確判斷。
非監督學習Unsupervised Learning
程式自己能夠窄一段資料集中自己自動發現模式和關係。比如,分析Email資料集,能夠自動根據主題進行分類歸組,在這之前無需任何事先的相關知識資料的訓練。(先天的判斷力,無需後天培養)。
分類Classification
這是監督學習的子目錄,分類是對某種資料輸入,能夠為他們分配標籤進行分類(比如將人分為男人和女人,不過出於對人的尊重,儘量不要對人標籤化)。分類通常是用在預測結果是離散的,要麼是肯定,要麼是否定的情況下。比如,將一張人的圖片分類為男人或女人。
迴歸Regression
監督學習的另外一個子目錄,當預測結果不是簡單的的"是"或"否"時,也就是說,預測結果是一段連續的範圍,比如"多少錢"或"多少東西"等。
決策樹
使用類似樹形結構的圖模型進行決策判斷和可能後果的判斷,比如下面:
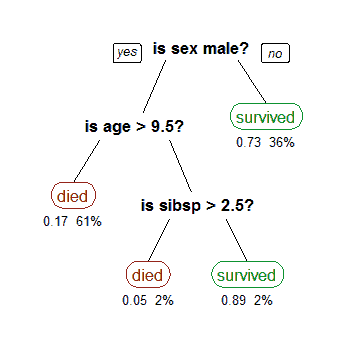
生成模型Generative Model
在概率和數理統計中,生成模型是在一些引數被隱藏時用於產生資料值。生成模型既可以直接用來建模資料,也可以作為中間步驟用來形成條件概率密度函式,比如你建模p(x,y)是為進行預測,
它能使用貝葉斯規則轉為p(x|y),也能夠生成像(x,y)資料對,能夠廣泛應用在非監督學習中。生成模型包括:Naive Bayes, Latent Dirichlet Allocation 和 Gaussian Mixture Model.
判別模型Discriminative Model
判別模型或條件化模型是用來建模基於變數x的依賴變數y,因為這個模型需要計算條件概率,如p(y|x),經常用在監督學習中,具體有: Logistic Regression, SVMs 和 Neural Networks.
深度學習
使用人工神經網路產生模型,能夠解決圖片辨識問題,因為它有能力獲得識別事物的特徵。
神經網路和人工神經網路
被定義為為統計學習模型,用於實現依賴大量的輸入的估算或近似函式。神經網路通常用於有大量輸入資料,這些資料對於標準的機器學習太大了。

Text Analysis blog | Aylien — 10 Machine Learning