
FLUME介紹 基本使用 常見問題
FLUME介紹 基本使用 常見問題
官網FLUME介紹
Flume is a distributed, reliable, and available service for efficiently collecting, aggregating, and moving large amounts of log data. It has a simple and flexible architecture based on streaming data flows. It is robust and fault tolerant with tunable reliability mechanisms and many failover and recovery mechanisms. It uses a simple extensible data model that allows for online analytic application
Flume是一種分散式、可靠和可用的服務,可以有效地收集、聚合和移動大量的日誌資料。它有一個基於流資料流的簡單而靈活的架構。它具有可調可靠性機制和許多故障轉移和恢復機制的強裝修性和容錯能力。它使用一個簡單的可擴充套件資料模型,允許線上分析應用程式

日誌上傳邏輯

flume 就是基於這個邏輯完成了這個整個日誌上傳框架
FLUME 三件套
Agent主要由:source,channel,sink三個元件組成.
我的理解是 agent就是一臺抽水機它裡面有三個元件source,channel,sink. source 就是我們抽水機的水管指向的取水地, channel 就是抽水機的水管,sink 就是水管指向的出口。
當有兩臺抽水機合作的時候,我們可以將一臺抽水機的 sink 指向 另外一個抽水機的source 這樣就完成了資料的 傳遞。
如圖下中
Source:
從資料發生器接收資料,並將接收的資料以Flume的event格式傳遞給一個或者多個通道channal,Flume提供多種資料接收的方式,比如Avro,Thrift,twitter1%等
這裡列舉幾個專案常用的Source
Exec Source

a1.sources = r1
a1.channels = c1
a1.sources.r1.type = exec
a1.sources.r1.command 這個就是常用的我們Linux 命令監控 它會一直上傳監控到的文字。但是但我們發生異常,tail -f 不能用了,或者程式中斷期間的那些檔案內容就不會上傳了,只會上傳當前監控到的檔案
Taildir Source

a1.sources = r1
a1.channels = c1
a1.sources.r1.type = TAILDIR
a1.sources.r1.channels = c1
a1.sources.r1.positionFile = /var/log/flume/taildir_position.json
a1.sources.r1.filegroups = f1 f2
a1.sources.r1.filegroups.f1 = /var/log/test1/example.log
a1.sources.r1.headers.f1.headerKey1 = value1
a1.sources.r1.filegroups.f2 = /var/log/test2/.*log.*
a1.sources.r1.headers.f2.headerKey1 = value2
a1.sources.r1.headers.f2.headerKey2 = value2-2
a1.sources.r1.fileHeader = trueTaildir Source 可以監控指定檔案,也可以用正則匹配方式來選擇自己將要上傳的檔案。 它的好處是,在flume程式停止的時候。讀取過的檔案位置是儲存在某個檔案中的。positionFile 這個屬性可以指定該json檔案位置。重啟之後,繼續從那個位置點開始上傳
Taildir Source有個弊端 就是在其filegroups 檔案目錄下,對匹配到的檔案,檔名稱進行修改後,檔案內容會重新上傳一份。 將使用這個Source 可以檢視 解決該問題http://blog.csdn.net/u012373815/article/details/62241528
Kafka Source

a1.sources.source1.type = org.apache.flume.source.kafka.KafkaSource
a1.sources.source1.kafka.bootstrap.servers = kafka-1:9093,kafka-2:9093,kafka-3:9093
a1.sources.source1.kafka.topics = mytopic
a1.sources.source1.kafka.consumer.group.id = flume-consumer
a1.sources.source1.kafka.consumer.security.protocol = SASL_PLAINTEXT
a1.sources.source1.kafka.consumer.sasl.mechanism = GSSAPI
a1.sources.source1.kafka.consumer.sasl.kerberos.service.name = kafka這個就不用多說了, 充當kafka 的消費者,我們只需配上topic 訂閱 的主題,所有消費者組的id 最好配置一下batch的屬性。這樣可以批量的上傳。
Avro Source

a1.sources = r1
a1.channels = c1
a1.sources.r1.type = avro
a1.sources.r1.channels = c1
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = 4141Avro Source 這個是分散式收集日誌的關鍵了。AVRO 底層是RPC方式。
開啟這個配置的話,flume程式會監聽4141埠。 另外flume程式 配置檔案中將sink 指向這個IP 的4141埠,那個FLUME程式的日誌就傳輸到該FLUME通道中來。
還有http Source ,Spooling Directory Source都是可能會用到的。大家自己到官網上看下吧。http://flume.apache.org/FlumeUserGuide.html#spooling-directory-source
Channel:
channal是一種短暫的儲存容器,它將從source處接收到的event格式的資料快取起來,直到它們被sinks消費掉,它在source和sink間起著一共橋樑的作用,channal是一個完整的事務,這一點保證了資料在收發的時候的一致性. 並且它可以和任意數量的source和sink連結. 支援的型別有: JDBC channel , File System channel , Memort channel等.
設計Flume資料流程圖時,根據自身伺服器配置選擇合適的Channel,分別是Memory Channel, JDBC Channel , File Channel,Psuedo Transaction Channel。比較常見的是前三種channel。具體使用那種channel,需要根據具體的使用場景。這裡我們主要用到的是File Channel 和Memory Channel,而JDBC Channel當前支援它本身嵌入的Derby 資料庫。
File Channel是一個持久化的隧道(channel),他持久化所有的事件,並將其儲存到磁碟中。因此,即使Java 虛擬機器當掉,或者作業系統崩潰或重啟,再或者事件沒有在管道中成功地傳遞到下一個代理(agent),這一切都不會造成資料丟失。Memory Channel是一個不穩定的隧道,其原因是由於它在記憶體中儲存所有事件。如果java程序死掉,任何儲存在記憶體的事件將會丟失。另外,記憶體的空間收到RAM大小的限制,而File Channel這方面是它的優勢,只要磁碟空間足夠,它就可以將所有事件資料儲存到磁碟上。
這裡舉例3個常用的通道
Memory Channel

a1.channels = c1
a1.channels.c1.type = memory
a1.channels.c1.capacity = 10000
a1.channels.c1.transactionCapacity = 10000
a1.channels.c1.byteCapacityBufferPercentage = 20
a1.channels.c1.byteCapacity = 800000
根據自己伺服器配置把。 因為放入通道中的資料 實際是放在記憶體裡面的,所以一旦程式掛掉了。記憶體裡面的資料就丟失掉了。File Channel

a1.channels = c1
a1.channels.c1.type = file
a1.channels.c1.checkpointDir = /mnt/flume/checkpoint
a1.channels.c1.dataDirs = /mnt/flume/data1.這個要注意的是在同一個agent 中也就是同一個配置中,如果有多個檔案通道同時初始化的話,只有一個能夠成功。
2.dataDirs 最好配置不同磁碟上的日誌,這樣讀取速度會快一點
Spillable Memory Channel

a1.channels = c1
a1.channels.c1.type = SPILLABLEMEMORY
a1.channels.c1.memoryCapacity = 10000
a1.channels.c1.overflowCapacity = 1000000
a1.channels.c1.byteCapacity = 800000
a1.channels.c1.checkpointDir = /mnt/flume/checkpoint
a1.channels.c1.dataDirs = /mnt/flume/data這個是檔案通道和記憶體通道的結合通道,可以設定當放入記憶體通道的資料量太大的話,會將多餘的放到磁碟上面,上面就配置超過多少位元組,然後放到磁碟上面
sink:
sink將資料儲存到集中儲存器比如Hbase和HDFS,它從channals消費資料(events)並將其傳遞給目標地. 目標地可能是另一個sink,也可能HDFS,HBase.
Avro Sink

a1.channels = c1
a1.sinks = k1
a1.sinks.k1.type = avro
a1.sinks.k1.channel = c1
a1.sinks.k1.hostname = 10.10.10.10
a1.sinks.k1.port = 45451 Avro Sink 基本都是跟 AVRO Source 一起配合使用的。兩者開啟壓縮(配置相同的compression 屬性,保證壓縮解壓縮能正常)
2 大家也可以根據原始碼對AVRO SINK做自己的擴充套件
http://blog.csdn.net/zh_yi/article/details/44948103
File Roll Sink

a1.channels = c1
a1.sinks = k1
a1.sinks.k1.type = file_roll
a1.sinks.k1.channel = c1
a1.sinks.k1.sink.directory = /var/log/flume1.這比較好理解 ,就是將通道中的資料放到指定的檔案中,不停的滾動生成,可以指定他的字首,字尾
Kafka Sink

a1.sinks.k1.channel = c1
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.kafka.topic = mytopic
a1.sinks.k1.kafka.bootstrap.servers = localhost:9092
a1.sinks.k1.kafka.flumeBatchSize = 20
a1.sinks.k1.kafka.producer.acks = 1
a1.sinks.k1.kafka.producer.linger.ms = 1
a1.sinks.k1.kafka.producer.compression.type = snappy1.Kafka Sink使用FlumeEvent header中的主題和關鍵屬性將事件傳送給Kafka。如果主題存在於header中,事件將被髮送到特定主題,覆蓋為該接收器配置的主題。如果標題中存在鍵,則Kafka將使用鍵來分割槽主題分割槽之間的資料
HTTP Sink

a1.channels = c1
a1.sinks = k1
a1.sinks.k1.type = http
a1.sinks.k1.channel = c1
a1.sinks.k1.endpoint = http://localhost:8080/someuri
a1.sinks.k1.connectTimeout = 2000
a1.sinks.k1.requestTimeout = 2000
a1.sinks.k1.acceptHeader = application/json
a1.sinks.k1.contentTypeHeader = application/json
a1.sinks.k1.defaultBackoff = true
a1.sinks.k1.defaultRollback = true
a1.sinks.k1.defaultIncrementMetrics = false
a1.sinks.k1.backoff.4XX = false
a1.sinks.k1.rollback.4XX = false
a1.sinks.k1.incrementMetrics.4XX = true
a1.sinks.k1.backoff.200 = false
a1.sinks.k1.rollback.200 = false
a1.sinks.k1.incrementMetrics.200 = true1 這個接收器的行為是它將從通道接收事件,並使用HTTP POST請求將這些事件傳送到遠端服務。事件內容作為POST主體傳送
2.這個接收器的錯誤處理行為取決於目標伺服器返回的HTTP響應。接收器的backoff /就緒狀態是可配置的,因為事務提交/回滾的結果以及事件有助於成功的事件消耗計數
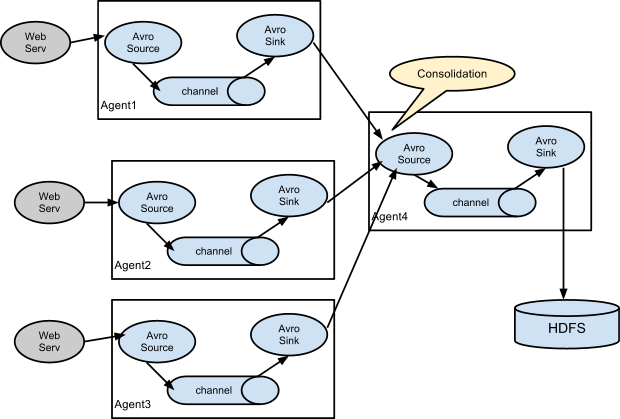
它的組合形式舉例:
以上介紹的flume的主要元件,下面介紹一下Flume外掛:
Interceptors攔截器
用於source和channel之間,用來更改或者檢查Flume的events資料
管道選擇器 channels Selectors
在多管道是被用來選擇使用那一條管道來傳遞資料(events). 管道選擇器又分為如下兩種:
預設管道選擇器: 每一個管道傳遞的都是相同的events
多路複用通道選擇器: 依據每一個event的頭部header的地址選擇管道.
3.sink執行緒
用於啟用被選擇的sinks群中特定的sink,用於負載均衡.