
flume介紹
前言
本文通過對flume的架構,資料鏈路和資料的可靠性來分析flume的原理,並在文末提供了demo(官網搬運)。
架構
flume可以理解為是一個ETL工具,本身是單點的,也就是隻有agent,沒有server,但是通過強大的source-channel-sink-source…機制,可以通過在多個節點上起agent構成一個DAG,從而形成分散式形態。參考圖1,圖2(其他圖就不貼了,參考官網文件),flume支援在任意節點啟動任意數量的agent,並且agent與agent之間可以通過rpc連線。需要注意的是,1個source可以下發資料到多個channel(通過`ChannelSelector`,最常見的就是廣播,或者動態路由),1個sink只能從1個channel獲取資料,但是多個sink又可以從1個channel拉取資料(通過`SinkProcessor`)。這樣的DAG設計意圖很明顯,source生產資料通常都是比sink處理資料快的,所以channel起到資料緩衝作用,並且通過事務機制保證資料的可靠性。試想一下場景,假如資料量很大,1個source消費速度跟不上,也就是說達到了單程序的效能瓶頸,那麼可以啟動多個agent;假如資料量一般,1個source就足夠,但是處理很複雜比如IO密集型的操作,那麼可以通過多sink的方式從channel拉資料,也就是sink端做負載均衡,比如`LoadBalancingSinkProcessor`。flume這樣的設計很好的滿足了各種場景需求。
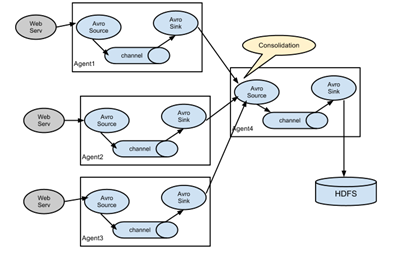
圖1
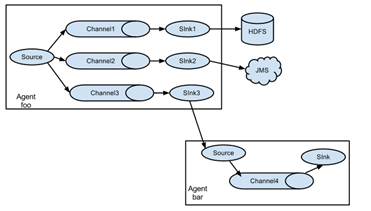
圖2
資料鏈路
參考圖3,flume的三個核心元件的資料鏈路是基於推送和拉取模式,其中Channel可以理解為列隊,也是實現資料可靠性的關鍵元件。比如常見的,採用FileChannel之類落盤的channel場景中,當source推送資料到channel失敗,那麼就會觸發source重試,當sink拉取資料操作失敗,那麼回通知channel回滾,直到sink操作成功才提交之前的那些資料,從而使得channel移除那些已經被成功處理的資料。

圖3
flume的元件也不僅僅只有source,channel,sink這三個。參考圖4,完整的資料鏈路還有ChannelProcessor和SinkeProcessor。ChannelProcessor主要功能有兩個,1.對事件進行攔截,提供修改事件的入口; 2.對channel的選擇,我們知道1個source可以傳送資料到多個channel,但是具體傳送到哪些channel呢?這裡就是選擇器決定了source傳送到哪些channel。SinkProcessor的功能其實也類似,由於一個channel的事件可以被多個sink拉取,那麼SinkProcessor決定了sink拉取的策略,這裡flume衍生出了sinkGroup的概念,一般情況下,1個sink對應1個執行緒,而sinkGroup可以包含多個sink共用1個執行緒。
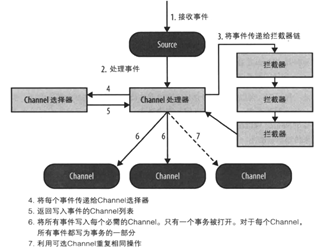
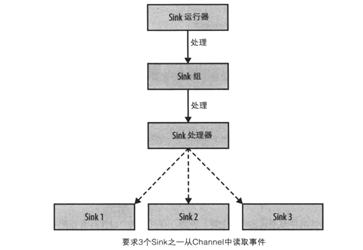
圖4
資料可靠性
資料可靠性是非常重要的一個特性,所以拉出來單獨做一下說明。
flume基於Channel和Transaction介面實現資料不丟失的特性。其中channel負責對資料持久化,維護了所有沒有被事務提交的事件,Transaction負責實現事務語義,類似jdbc的事務語法,如下
Transaction tx = ch.getTransaction(); try { tx.begin(); ... // ch.put(event) or ch.take() ... tx.commit(); } catch(ChannelException ex) { tx.rollback(); ... } finally { tx.close(); }
通過這兩個介面的保證,flume可以實現at leaset once的語義,這是由於sink可以出現rpc超時等一些問題,導致誤以為失敗導致事件被重複拉取。這個問題可以通過對事件分配唯一id,再通過其他大資料元件去重。
總結
flume提供一個靈活的設計思路,可以通過agent組合構建出符合自己需求的DAG,有點類似storm,但是程式更加輕量。並且提供了很多開箱即用的外掛,可以說是很良心了。
demo
下面通過一個案例來了解flume,思路是構建基於netcat的agent,然後通過telnet進行驗證。
# 建立一個新的flume配置檔案
vi example.conf
# example.conf: A single-node Flume configuration # Name the components on this agent a1.sources = r1 a1.sinks = k1 a1.channels = c1 # Describe/configure the source a1.sources.r1.type = netcat a1.sources.r1.bind = localhost a1.sources.r1.port = 44444 # Describe the sink a1.sinks.k1.type = logger # Use a channel which buffers events in memory a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
# 啟動flume agent,並開啟http的度量監控,可以通過http請求獲取相關度量資料
flume-ng agent --name a1 --conf-file example.conf -Dflume.root.logger=INFO,console -Dflume.monitoring.type=http -Dflume.monitoring.port=9999
# 通過telnet進行除錯
telnet localhost 44444
# 發現訊息,可以看到flume agent可以成功接收
參考
// flume官網文件以及原始碼
http://flume.apache.org/FlumeUserGuide.html
// 書乃本也~
《Flume 構建高可用、可擴充套件的海量日誌採集系統》