
sparksql\hive on spark\hive on mr
Hive on Mapreduce
Hive的原理大家可以參考這篇大資料時代的技術hive:hive介紹,實際的一些操作可以看這篇筆記:新手的Hive指南,至於還有興趣看Hive優化方法可以看看我總結的這篇Hive效能優化上的一些總結
Hive on Mapreduce執行流程
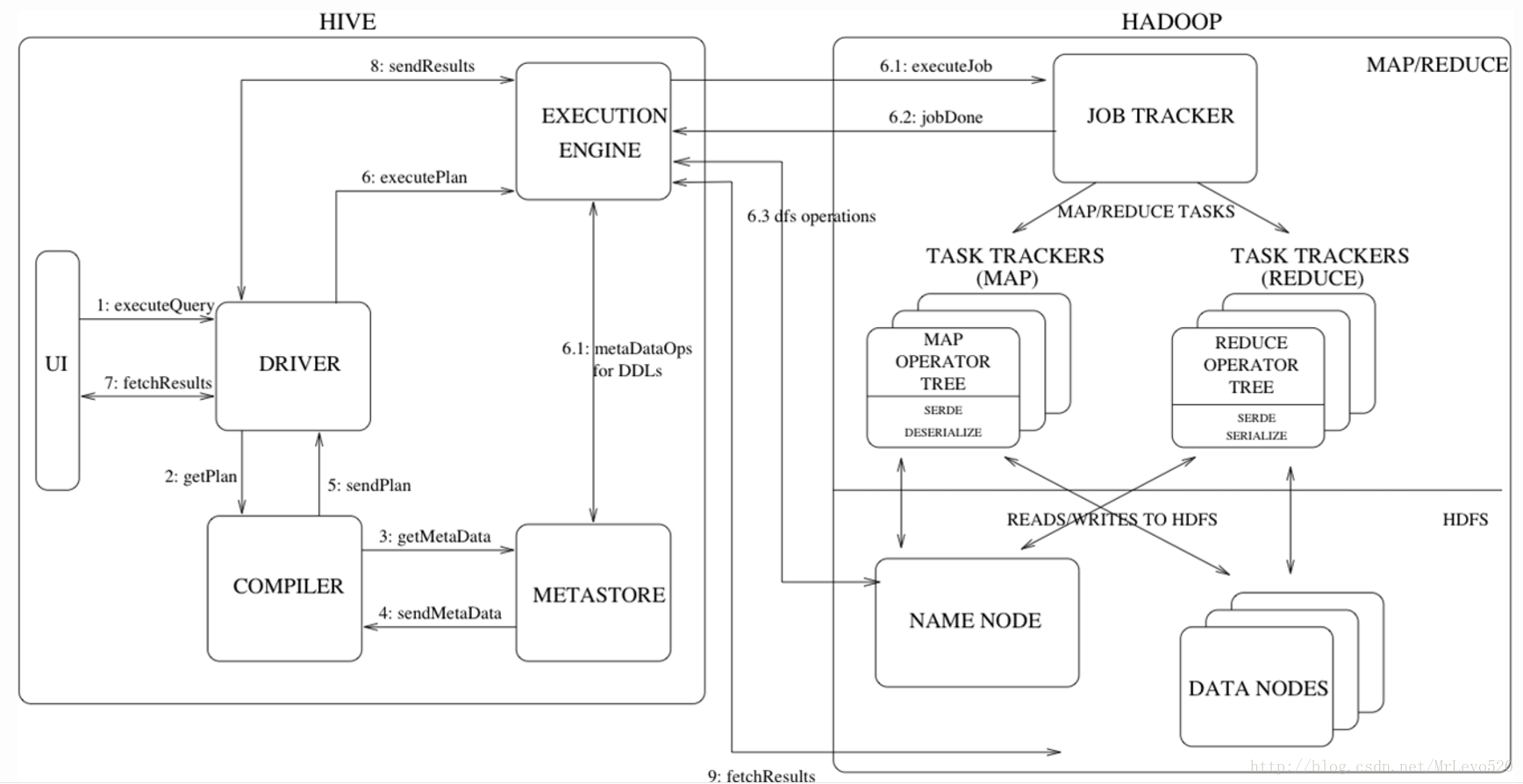
執行流程詳細解析
- Step 1:UI(user interface) 呼叫 executeQuery 介面,傳送 HQL 查詢語句給 Driver
- Step 2:Driver 為查詢語句建立會話控制代碼,並將查詢語句傳送給 Compiler, 等待其進行語句解析並生成執行計劃
- Step 3 and 4:Compiler 從 metastore 獲取相關的元資料
- Step 5:元資料用於對查詢樹中的表示式進行型別檢查,以及基於查詢謂詞調整分割槽,生成計劃
- Step 6 (6.1,6.2,6.3):由 Compiler 生成的執行計劃是階段性的 DAG,每個階段都可能會涉及到 Map/Reduce job、元資料的操作、HDFS 檔案的操作,Execution Engine 將各個階段的 DAG 提交給對應的元件執行。
- Step 7, 8 and 9:在每個任務(mapper / reducer)中,查詢結果會以臨時檔案的方式儲存在 HDFS 中。儲存查詢結果的臨時檔案由 Execution Engine 直接從 HDFS 讀取,作為從 Driver Fetch API 的返回內容。
Hive on Mapreduce特點
- 關係資料庫裡,表的載入模式是在資料載入時候強制確定的(表的載入模式是指資料庫儲存資料的檔案格式),如果載入資料時候發現載入的資料不符合模式,關係資料庫則會拒絕載入資料,這個就叫“寫時模式”,寫時模式會在資料載入時候對資料模式進行檢查校驗的操作。Hive在載入資料時候和關係資料庫不同,hive在載入資料時候不會對資料進行檢查,也不會更改被載入的資料檔案,而檢查資料格式的操作是在查詢操作時候執行,這種模式叫“讀時模式”。在實際應用中,寫時模式在載入資料時候會對列進行索引,對資料進行壓縮,因此載入資料的速度很慢,但是當資料載入好了,我們去查詢資料的時候,速度很快。但是當我們的資料是非結構化,儲存模式也是未知時候,關係資料操作這種場景就麻煩多了,這時候hive就會發揮它的優勢。
- 關係資料庫一個重要的特點是可以對某一行或某些行的資料進行更新、刪除操作,hive**不支援對某個具體行的操作,hive對資料的操作只支援覆蓋原資料和追加資料**。Hive也不支援事務和索引。更新、事務和索引都是關係資料庫的特徵,這些hive都不支援,也不打算支援,原因是hive的設計是海量資料進行處理,全資料的掃描時常態,針對某些具體資料進行操作的效率是很差的,對於更新操作,hive是通過查詢將原表的資料進行轉化最後儲存在新表裡,這和傳統資料庫的更新操作有很大不同。
- Hive也可以在hadoop做實時查詢上做一份自己的貢獻,那就是和hbase整合,hbase可以進行快速查詢,但是hbase不支援類SQL的語句,那麼此時hive可以給hbase提供sql語法解析的外殼,可以用類sql語句操作hbase資料庫。
- Hive可以認為是MapReduce的一個封裝、包裝。Hive的意義就是在業務分析中將使用者容易編寫、會寫的Sql語言轉換為複雜難寫的MapReduce程式,從而大大降低了Hadoop學習的門檻,讓更多的使用者可以利用Hadoop進行資料探勘分析。
與傳統資料庫之間對比—From:Hive和傳統資料庫進行比較
| 比較項 | SQL | HiveQL |
|---|---|---|
| ANSI SQL | 支援 | 不完全支援 |
| 更新 | UPDATE\INSERT\DELETE | insert OVERWRITE\INTO TABLE |
| 事務 | 支援 | 不支援 |
| 模式 | 寫模式 | 讀模式 |
| 資料儲存 | 塊裝置、本地檔案系統 | HDFS |
| 延時 | 低 | 高 |
| 多表插入 | 不支援 | 支援 |
| 子查詢 | 完全支援 | 只能用在From子句中 |
| 檢視 | Updatable | Read-only |
| 可擴充套件性 | 低 | 高 |
| 資料規模 | 小 | 大 |
| …. | …… | …… |
SparkSQL
SparkSQL簡介
SparkSQL的前身是Shark,給熟悉RDBMS但又不理解MapReduce的技術人員提供快速上手的工具,hive應運而生,它是當時唯一執行在Hadoop上的SQL-on-hadoop工具。但是MapReduce計算過程中大量的中間磁碟落地過程消耗了大量的I/O,降低的執行效率,為了提高SQL-on-Hadoop的效率,Shark應運而生,但又因為Shark對於Hive的太多依賴(如採用Hive的語法解析器、查詢優化器等等),2014年spark團隊停止對Shark的開發,將所有資源放SparkSQL專案上
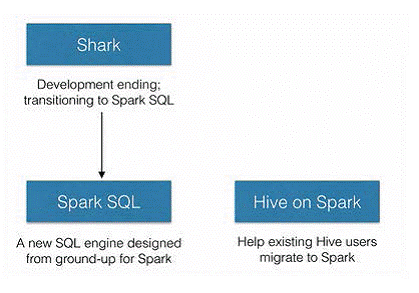
其中SparkSQL作為Spark生態的一員繼續發展,而不再受限於Hive,只是相容Hive;而Hive on Spark是一個Hive的發展計劃,該計劃將Spark作為Hive的底層引擎之一,也就是說,Hive將不再受限於一個引擎,可以採用Map-Reduce、Tez、Spark等引擎。
-
SparkSQL的兩個元件
- SQLContext:Spark SQL提供SQLContext封裝Spark中的所有關係型功能。可以用之前的示例中的現有SparkContext建立SQLContext。
- DataFrame:DataFrame是一個分散式的,按照命名列的形式組織的資料集合。DataFrame基於R語言中的data frame概念,與關係型資料庫中的資料庫表類似。通過呼叫將DataFrame的內容作為行RDD(RDD of Rows)返回的rdd方法,可以將DataFrame轉換成RDD。可以通過如下資料來源建立DataFrame:已有的RDD、結構化資料檔案、JSON資料集、Hive表、外部資料庫。
SparkSQL執行架構
類似於關係型資料庫,SparkSQL也是語句也是由Projection(a1,a2,a3)、Data Source(tableA)、Filter(condition)組成,分別對應sql查詢過程中的Result、Data Source、Operation,也就是說SQL語句按Operation–>Data Source–>Result的次序來描述的。
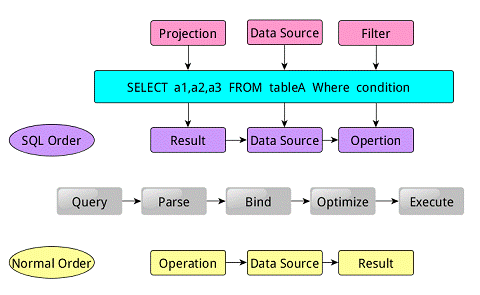
當執行SparkSQL語句的順序
- 對讀入的SQL語句進行解析(Parse),分辨出SQL語句中哪些詞是關鍵詞(如SELECT、FROM、WHERE),哪些是表示式、哪些是Projection、哪些是Data Source等,從而判斷SQL語句是否規範;
- Projection:簡單說就是select選擇的列的集合,參考:SQL Projection
- 將SQL語句和資料庫的資料字典(列、表、檢視等等)進行繫結(Bind),如果相關的Projection、Data Source等都是存在的話,就表示這個SQL語句是可以執行的;
- 一般的資料庫會提供幾個執行計劃,這些計劃一般都有執行統計資料,資料庫會在這些計劃中選擇一個最優計劃(Optimize);
- 計劃執行(Execute),按Operation–>Data Source–>Result的次序來進行的,在執行過程有時候甚至不需要讀取物理表就可以返回結果,比如重新執行剛執行過的SQL語句,可能直接從資料庫的緩衝池中獲取返回結果。
Hive on Spark
hive on Spark是由Cloudera發起,由Intel、MapR等公司共同參與的開源專案,其目的是把Spark作為Hive的一個計算引擎,將Hive的查詢作為Spark的任務提交到Spark叢集上進行計算。通過該專案,可以提高Hive查詢的效能,同時為已經部署了Hive或者Spark的使用者提供了更加靈活的選擇,從而進一步提高Hive和Spark的普及率。
Hive on Spark與SparkSql的區別
hive on spark大體與SparkSQL結構類似,只是SQL引擎不同,但是計算引擎都是spark!敲黑板!這才是重點!
我們來看下,在pyspark中使用Hive on Spark是中怎麼樣的體驗
<span style="color:#000000"><code class="language-python"><span style="color:#880000">#初始化Spark SQL</span>
<span style="color:#880000">#匯入Spark SQL</span>
<span style="color:#000088">from</span> pyspark.sql <span style="color:#000088">import</span> HiveContext,Row
<span style="color:#880000"># 當不能引入Hive依賴時</span>
<span style="color:#880000"># from pyspark.sql import SQLContext,Row</span>
<span style="color:#880000"># 注意,上面那一點才是關鍵的,他兩來自於同一個包,你們區別能有多大</span>
hiveCtx = HiveContext(sc) <span style="color:#880000">#建立SQL上下文環境</span>
input = hiveCtx.jsonFile(inputFile) <span style="color:#880000">#基本查詢示例</span>
input.registerTempTable(<span style="color:#009900">"tweets"</span>) <span style="color:#880000">#註冊輸入的SchemaRDD(SchemaRDD在Spark 1.3版本後已經改為DataFrame)</span>
<span style="color:#880000">#依據retweetCount(轉發計數)選出推文</span>
topTweets = hiveCtx.sql(<span style="color:#009900">"SELECT text,retweetCount FROM tweets ORDER BY retweetCount LIMIT 10"</span>)</code></span>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
我們可以看到,sqlcontext和hivecontext都是出自於pyspark.sql包,可以從這裡理解的話,其實hive on spark和sparksql並沒有太大差別
結構上Hive On Spark和SparkSQL都是一個翻譯層,把一個SQL翻譯成分散式可執行的Spark程式。而且大家的引擎都是spark
SparkSQL和Hive On Spark都是在Spark上實現SQL的解決方案。Spark早先有Shark專案用來實現SQL層,不過後來推翻重做了,就變成了SparkSQL。這是Spark官方Databricks的專案,Spark專案本身主推的SQL實現。Hive On Spark比SparkSQL稍晚。Hive原本是沒有很好支援MapReduce之外的引擎的,而Hive On Tez專案讓Hive得以支援和Spark近似的Planning結構(非MapReduce的DAG)。所以在此基礎上,Cloudera主導啟動了Hive On Spark。這個專案得到了IBM,Intel和MapR的支援(但是沒有Databricks)。—From SparkSQL與Hive on Spark的比較
Hive on Mapreduce和SparkSQL使用場景
Hive on Mapreduce場景
- Hive的出現可以讓那些精通SQL技能、但是不熟悉MapReduce 、程式設計能力較弱與不擅長Java語言的使用者能夠在HDFS大規模資料集上很方便地利用SQL 語言查詢、彙總、分析資料,畢竟精通SQL語言的人要比精通Java語言的多得多
- Hive適合處理離線非實時資料
SparkSQL場景
- Spark既可以執行本地local模式,也可以以Standalone、cluster等多種模式執行在Yarn、Mesos上,還可以執行在雲端例如EC2。此外,Spark的資料來源非常廣泛,可以處理來自HDFS、HBase、 Hive、Cassandra、Tachyon上的各種型別的資料。
- 實時性要求或者速度要求較高的場所
Hive on Mapreduce和SparkSQL效能對比
結論:sparksql和hive on spark時間差不多,但都比hive on mapreduce快很多,官方資料認為spark會被傳統mapreduce快10-100倍