
SparkSQL和hive on Spark
SparkSQL簡介
SparkSQL的前身是Shark,給熟悉RDBMS但又不理解MapReduce的技術人員提供快速上手的工具,hive應運而生,它是當時唯一執行在Hadoop上的SQL-on-hadoop工具。但是MapReduce計算過程中大量的中間磁碟落地過程消耗了大量的I/O,降低的執行效率,為了提高SQL-on-Hadoop的效率,Shark應運而生,但又因為Shark對於Hive的太多依賴(如採用Hive的語法解析器、查詢優化器等等),2014年spark團隊停止對Shark的開發,將所有資源放SparkSQL專案上
SparkSQL、Hive on Spark的關係
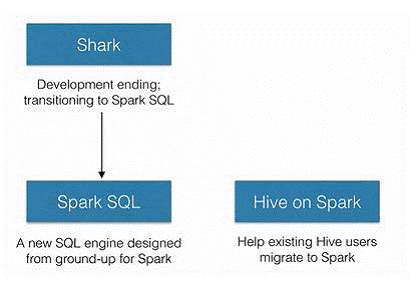
由上圖可以看出,SparkSQL之所以要從Shark中孵化出來,初衷就是為了剝離Shark對於Hive的太多依賴。SparkSQL作為Spark生態中獨立的一員繼續發展,不在受限於Hive,只是相容Hive;而Hive on Spark是Hive的發展計劃,該計劃將Spark作為Hive最底層的引擎之一,Hive不在受限於一個引擎(之前只支援map-reduce),可以採用map-reduce、Tez、Spark等計算引擎。
hive on Spark是有Cloudera發起,有Intel、MapR等公司共同參與的開源專案,其目的就是將Spark作為Hive的一個計算引擎,將Hive的查詢作為Spark的任務提交到Spark叢集上面進行計算。通過該專案,可以提高Hive查詢的效能,同事為已經部署了Hive或者Spark的使用者提供了更加靈活地選擇,從而進一步提高Hive和Spark的普及率。
hive on Spark和SparkSQL的結構類似,只是SQL引擎不同,但是計算引擎都是spark
sparkSQL通過sqlcontext來進行使用,hive on spark通過hivecontext來使用。sqlcontext和hivecontext都是來自於同一個包,從這個層面上理解,其實hive on spark和sparkSQL並沒有太大差別。
結構上來看,Hive on Spark和SparkSQL都是一個翻譯曾,將SQL翻譯成分佈是可以執行的Spark程式。
SQLContext:spark處理結構化資料的入口,允許建立DataFrame以及sql查詢。
HiveContext:Spark sql執行引擎,整合hive資料,讀取在classpath的hive-site.xml配置檔案配置hive。所以ye
SparkSQL元件和執行架構
1-SQLContext:Spark SQL提供SQLContext封裝Spark中的所有關係型功能。可以用之前的示例中的現有SparkContext建立SQLContext。
2-DataFrame:DataFrame是一個分散式的,按照命名列的形式組織的資料集合。DataFrame基於R語言中的data frame概念,與關係型資料庫中的資料庫表類似。通過呼叫將DataFrame的內容作為行RDD(RDD of Rows)返回的rdd方法,可以將DataFrame轉換成RDD。可以通過如下資料來源建立DataFrame:已有的RDD、結構化資料檔案、JSON資料集、Hive表、外部資料庫。
了私語關係型資料庫,SparkSQL中的SQL語句也是由Projection、Data source、Filter但部分組成,分別對應於sql查詢過程中的Result、Data source和Operation;SQL語句是按照Operation-》Data Source -》Result的次序來描述的。如下所示:

下面對上圖中展示的SparkSQL語句的執行順序進行詳細解釋:
1-對讀入的SQL語句進行解析(Parse),分辨出SQL語句中哪些詞是關鍵詞(如SELECT、FROM、WHERE),哪些是表示式、哪些是Projection、哪些是Data Source等,從而判斷SQL語句是否規範;
Projection:簡單說就是select選擇的列的集合,參考:SQL Projection
2-將SQL語句和資料庫的資料字典(列、表、檢視等等)進行繫結(Bind),如果相關的Projection、Data Source等都是存在的話,就表示這個SQL語句是可以執行的;
3-一般的資料庫會提供幾個執行計劃,這些計劃一般都有執行統計資料,資料庫會在這些計劃中選擇一個最優計劃(Optimize);
4-計劃執行(Execute),按Operation–>Data Source–>Result的次序來進行的,在執行過程有時候甚至不需要讀取物理表就可以返回結果,比如重新執行剛執行過的SQL語句,可能直接從資料庫的緩衝池中獲取返回結果。
SQLContext和HiveContext
當使用SparkSQL時,根據是否要使用Hive,有兩個不同的入口。推薦使用入口HiveContext,HiveContext繼承自SQLContext。它可以提供HiveQL以及其他依賴於Hive的功能的支援。更為基礎的SQLContext則僅僅支援SparlSQL功能的一個子集,子集中去掉了需要依賴Hive的功能。這種分離主要視為那些可能會因為引入Hive的全部依賴而陷入依賴衝突的使用者而設計的。因為使用HiveContext的時候不需要事先部署好Hive。如果要把一個Spark SQL連結到部署好的Hive上面,必須將hive-site.xml複製到Spark的配置檔案目錄中($SPARK_HOME/conf)。即使沒有部署好Hive,SparkSQL也可以執行,如果沒有部署好Hive,但是還要使用HiveContext的話,那麼SparkSQL將會在當前的工作目錄中創建出自己的Hive元資料倉庫,叫做metastore_db。,如果使用HiveQL中的CREATETABLE語句來建立表,那麼這些表將會被放在預設的檔案系統中的/user/hive/warehouse目錄中,這裡預設的檔案系統視情況而定,如果配置了hdfs-site.xml那麼就會存放在HDFS上面,否則就存放在本地檔案系統中。
執行HiveContext的時候hive環境並不是必須,但是需要hive-site.xml配置檔案。