
transformer 各個部分主要內容
自注意力詳解:
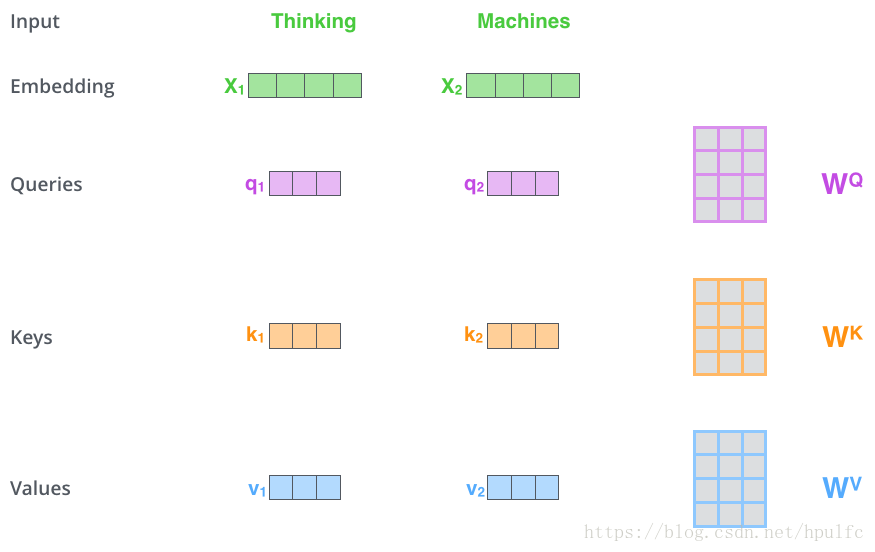
- 預處理:將資料輸入進行嵌入, 得到嵌入向量
- 獲取三個向量:嵌入向量 與 三個矩陣(訓練中的出來的) 相乘 分別得到 query 向量、key 向量、value 向量。如圖1
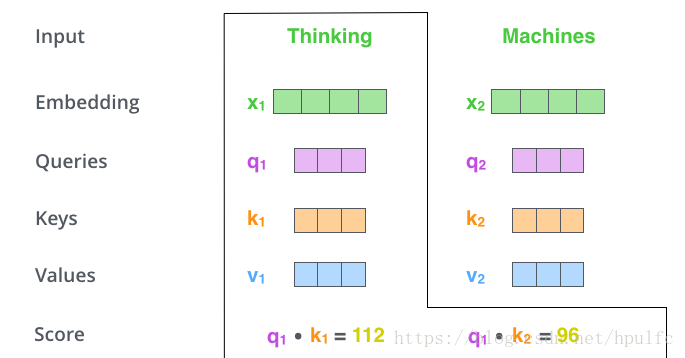
- 分數計算:將當前位置的 query 向量 與各個位置的 key 向量 進行相乘得到。表示當前位置單詞與其他單詞的相關程度。如圖2
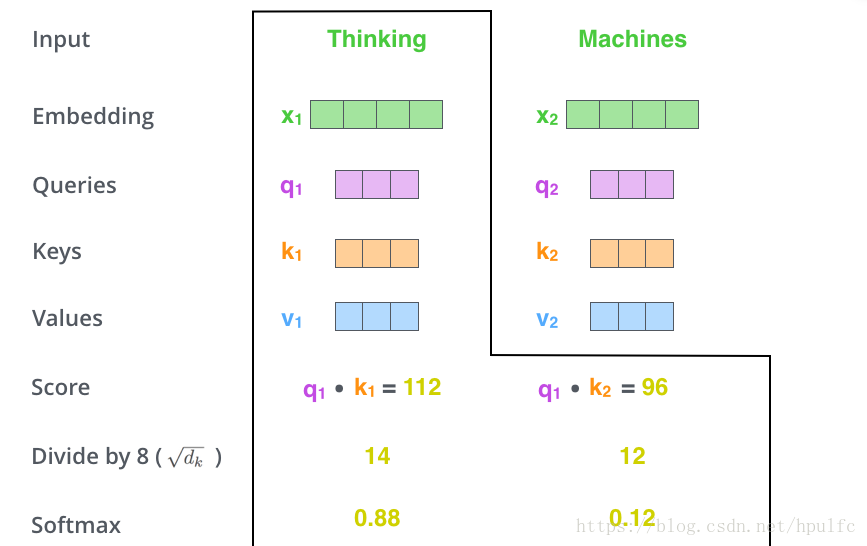
- 分數處理: 將分數除以 (key向量維數的平方根), 然後進行softmax 。這個分數表示其他單詞在這個位置的表達量。如圖3
- 注意力的體現:如何體現注意力呢,將 value 向量分別乘上(或加上)softmax 分數。主要是為了增大對需要關注的詞的關注度,減少無關詞的關注度。
- 獲取輸出:對上一步的 所有單詞的 結果進行加權求和 作為在當前位置的單詞的輸出。如圖4

以矩陣方式進行運算可以將上面的步驟壓縮兩步即可:
- 首先獲取三個向量矩陣,也即將嵌入後的向量 和 三個權重矩陣進行相乘 得到三個 矩陣 Q 、K、V
- 然後根據數學公式完成後面的步驟:
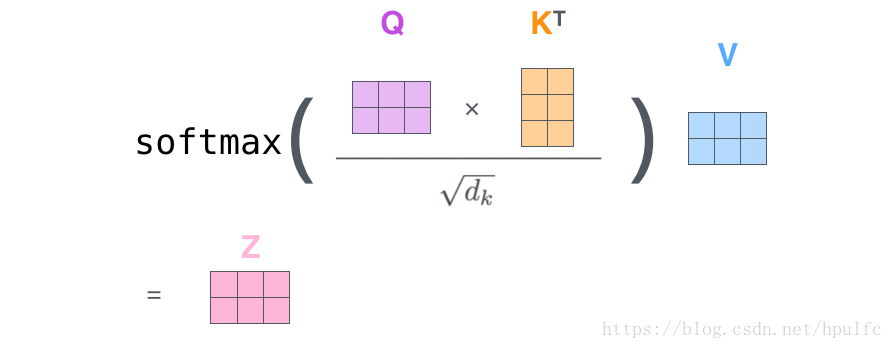
注意:權重矩陣 剛開始是隨機初始化的
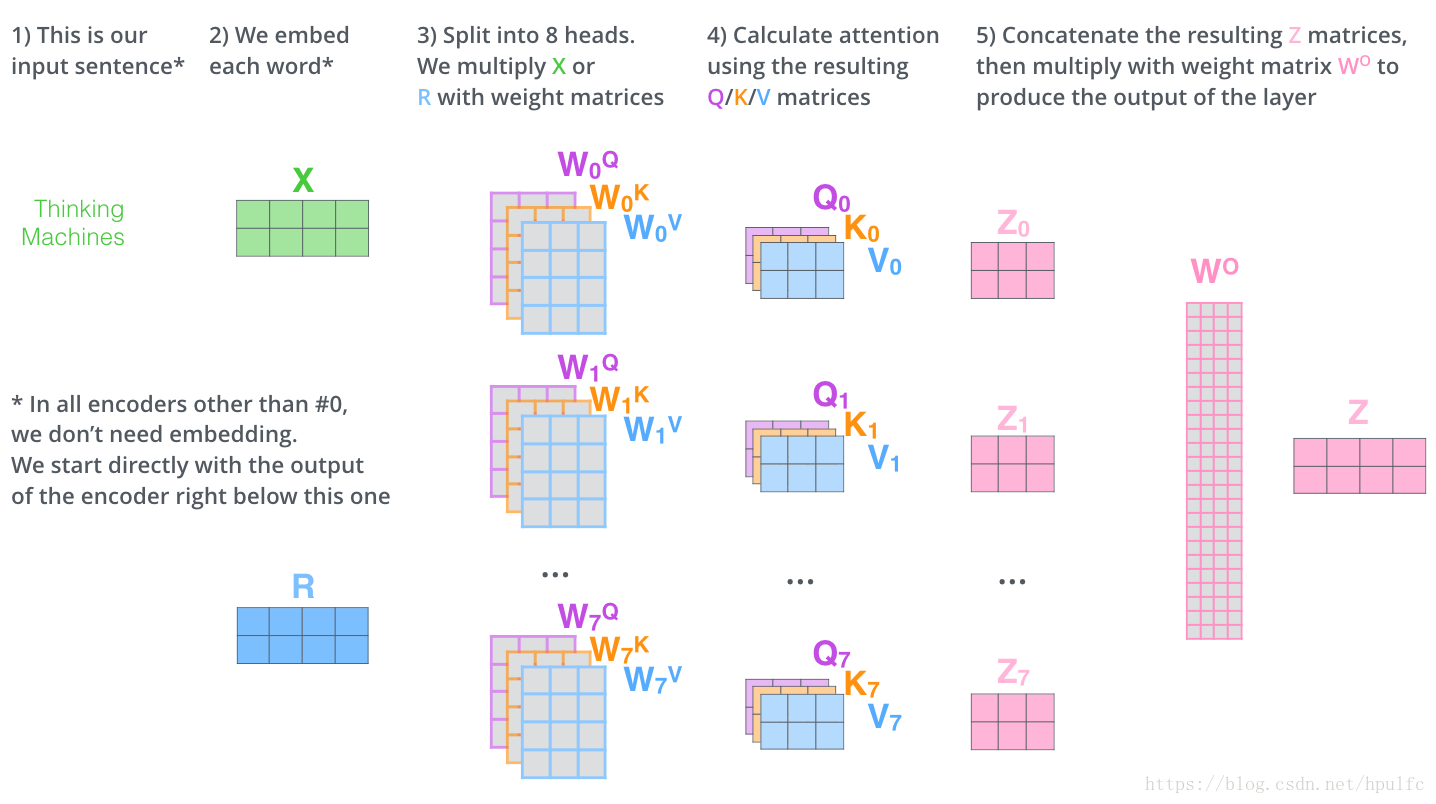
所謂多頭自注意力:
就是 上面的的 自注意力有N個 在transformer 中預設是8個 ,也就是說 一層中有八組 q k v 權重矩陣。那麼為什麼要用多頭呢? 此處先留個位置。。。。
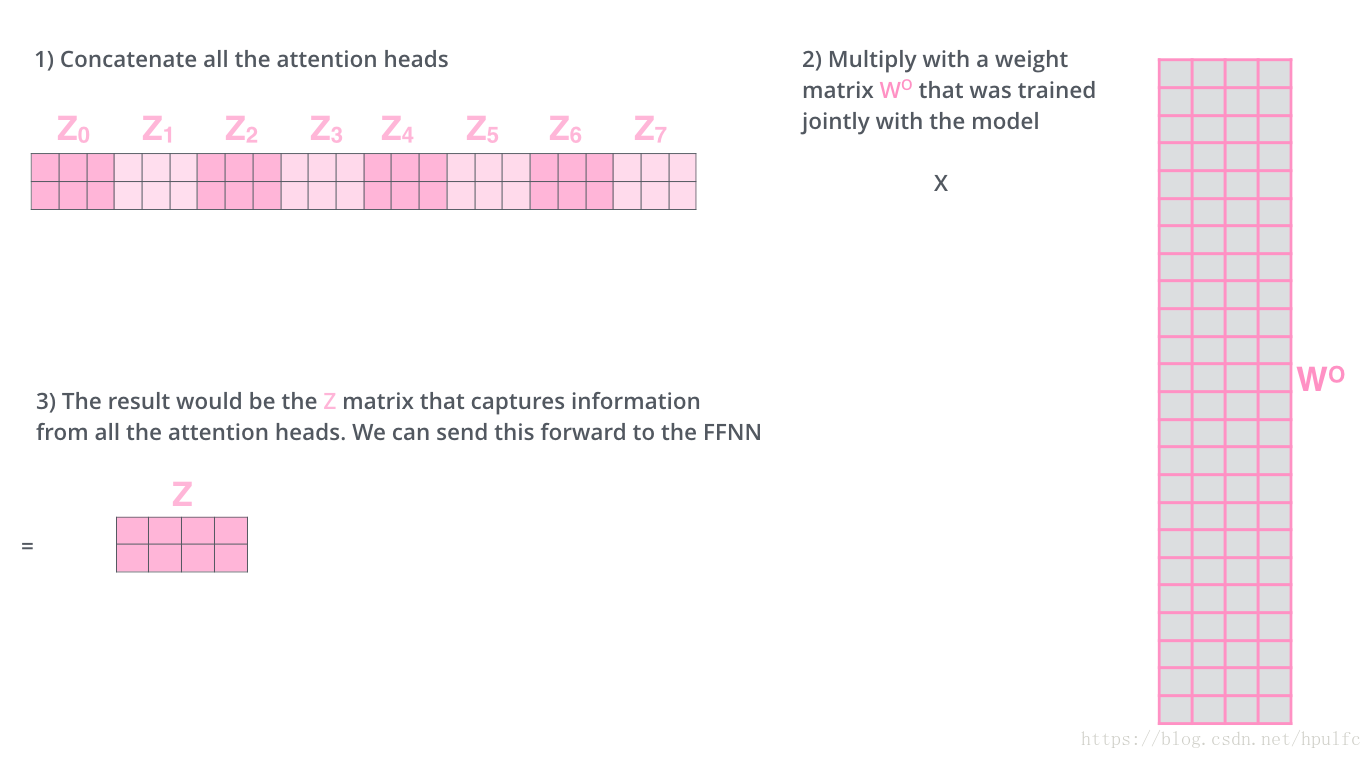
有了八組 權重矩陣 ,在隨機初始化後 進行訓練,得到對應的權重矩陣各個 嵌入向量 經過輸入 到對應的每一組自注意力 流程裡面 會產生對應的Z0 Z1 Z2 ... 也就是各個的一個分數值。那麼怎麼樣像是用單個頭一樣 輸入到前饋神經網路層呢?這裡的做法是將這8組 產生的結果進行連線 ,然後經過另外一個權重矩陣 轉換成 對用維度的 Z ,再次輸入到 前饋層
另一個重要的點:位置編碼
為什麼要進行位置編碼呢 ? 是為了吧位置資訊引入到 模型中,使得上面的一些權重矩陣可以學習到 相對的特徵。
怎麼引入位置編碼呢?位置編碼的模式又是怎樣呢?
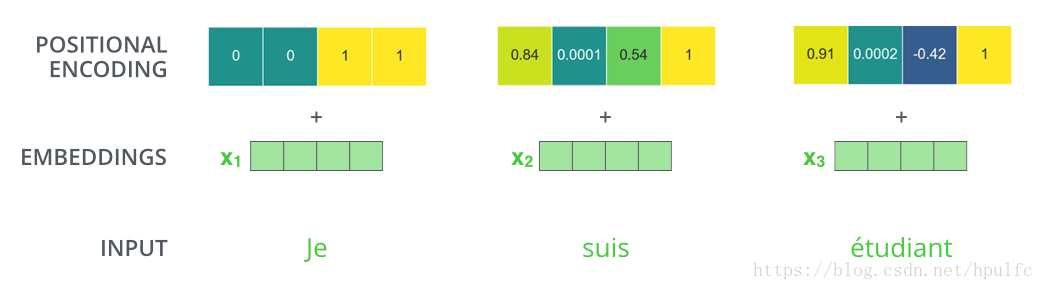
首先第一個,怎麼引入,transformer模型中是直接對於每一個經過嵌入的 嵌入向量 加上一個 位置向量。這個位置向量是每一個詞都有的,如圖7。它是怎麼來的呢,看下面
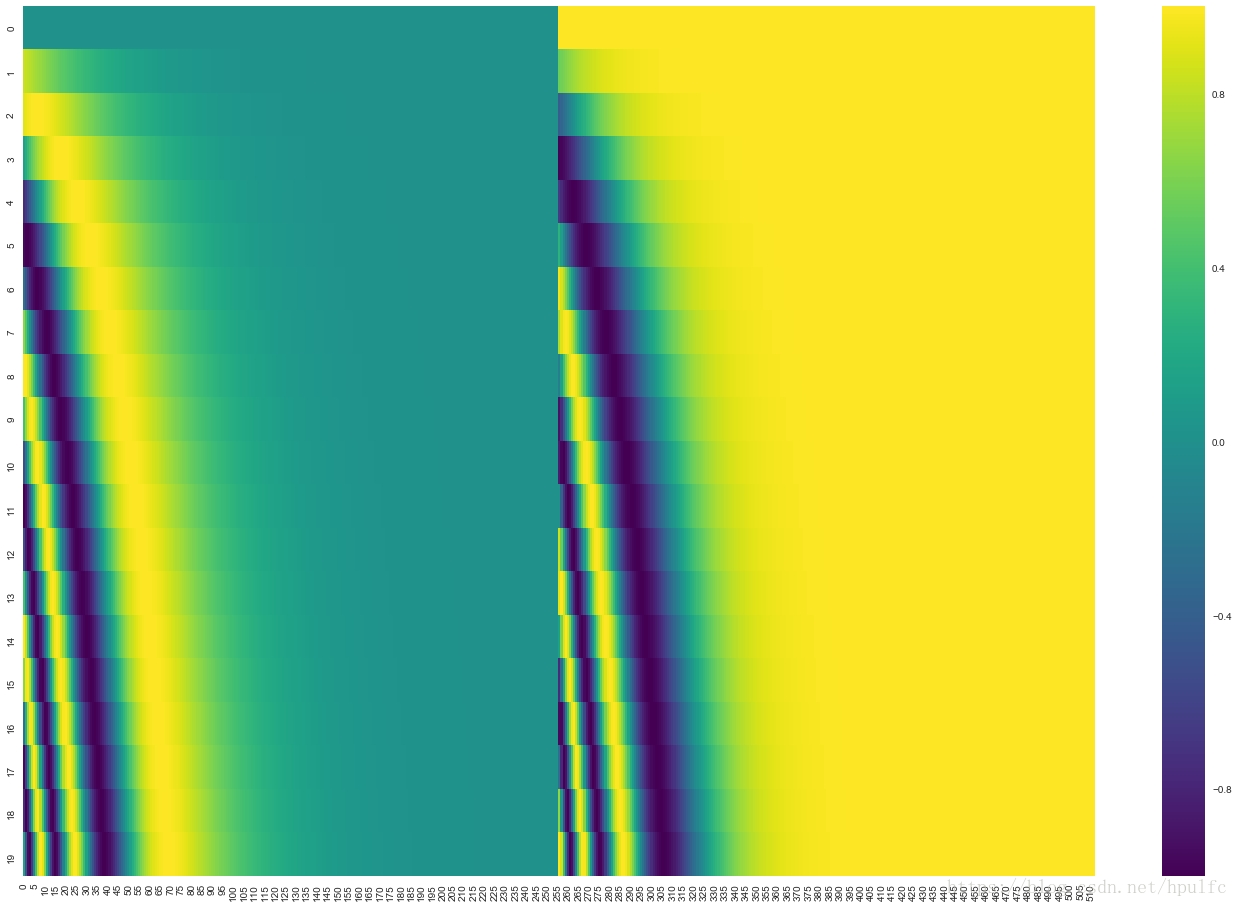
第二個就是 編碼模式是怎樣的,為了使得向量可以相加,對於單個詞的位置向量的維度是512 維的 也就是說要和 嵌入向量維度相同。然後編碼的話是經過正弦餘弦得到對應的位置向量的。如圖8, 是20個詞的位置編碼,前半部分是正弦獲取的值,後半部分是餘弦獲取的值,連在一起就是位置向量了。當然這不是唯一的編碼方式,這種好處就是可以編碼很(超)長的位置。
殘差:
這是 transformer 結構中的另外一個細節地方,殘差的操作在每一個子層都有,也就是 自注意力層和前饋層中,同時是結合了normalize 同時進行的。是在 進行 自注意力操作之前 的向量 和 之後的向量相加 然後進行normalize操作。在前饋層同樣也是這樣的,如圖9

值得注意的是運用在 解碼器層的時候 ,這種思想是在 進行 encode-decoder attention 之前和之後,同樣也進行了殘差 和normalize 操作,如圖10 ,也就是decoder#1 和decoder#2 分別表示 之前和之後,然後像上邊那樣進行殘差和normalize
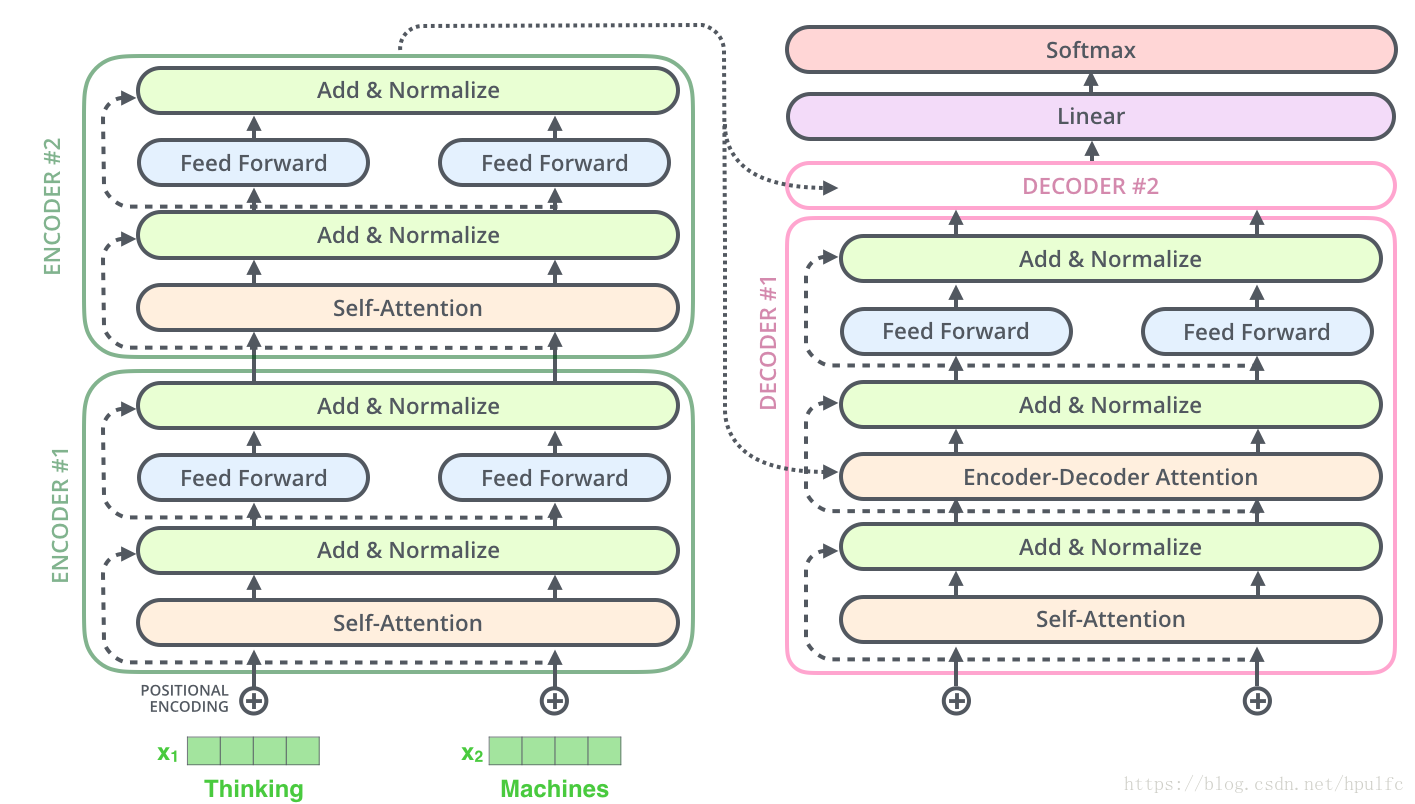
前面是主要講了一些基本的操作,那麼最主要的就是 怎麼進行decode呢?
解碼過程
主要是 : 每一個時間步驟都通過 編碼器的輸出得到一個詞,並且在得到輸出的詞之後,在下一個時間步將這個詞 喂入到解碼器進行嵌入、位置編碼、自注意力並且和 編碼輸出同時進行注意力操作,接著流經前饋神經網路層,最終輸出這個時間步的詞。以此迴圈,直到產生特殊的結束符號表示 輸出已經完成,也就是這句話翻譯完了。如圖11 12
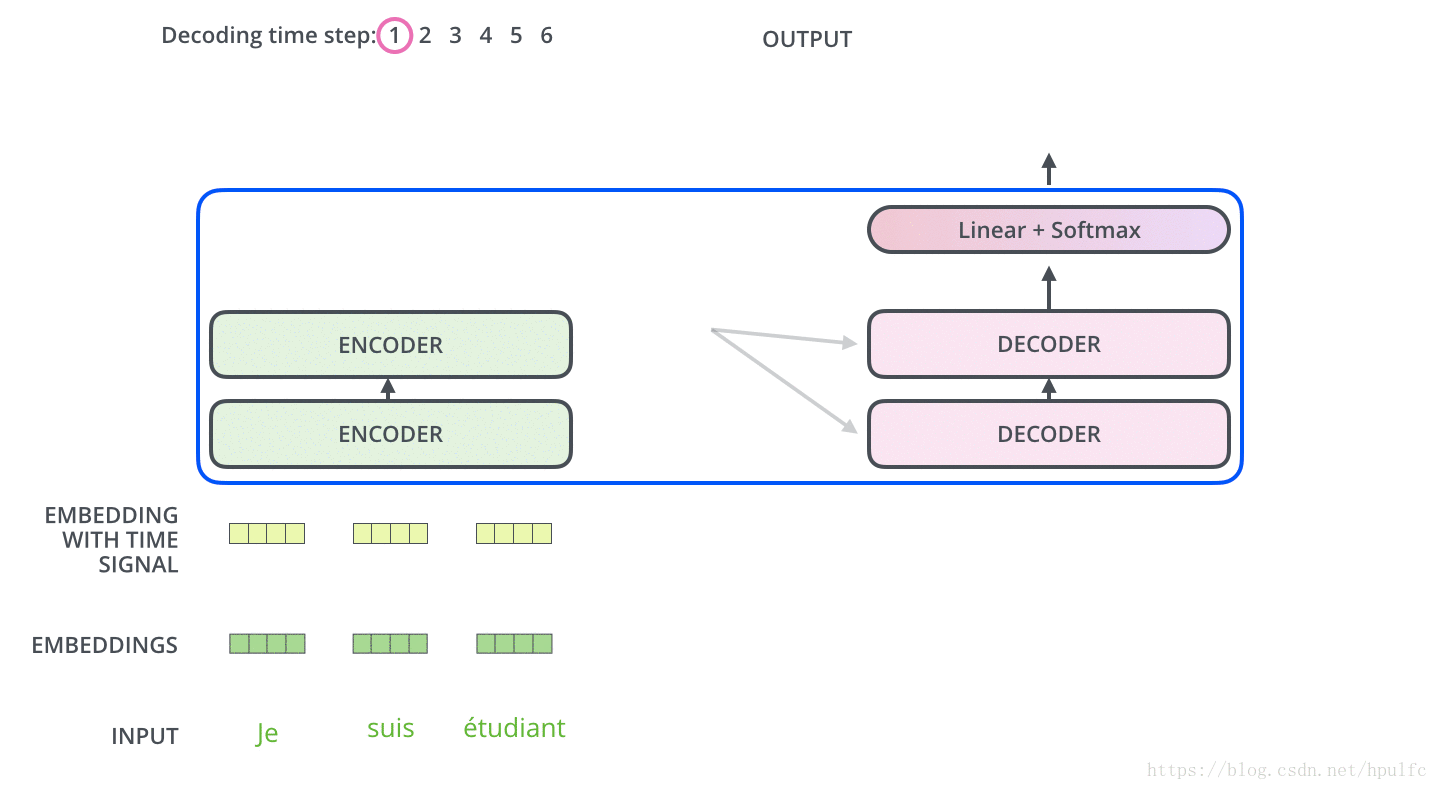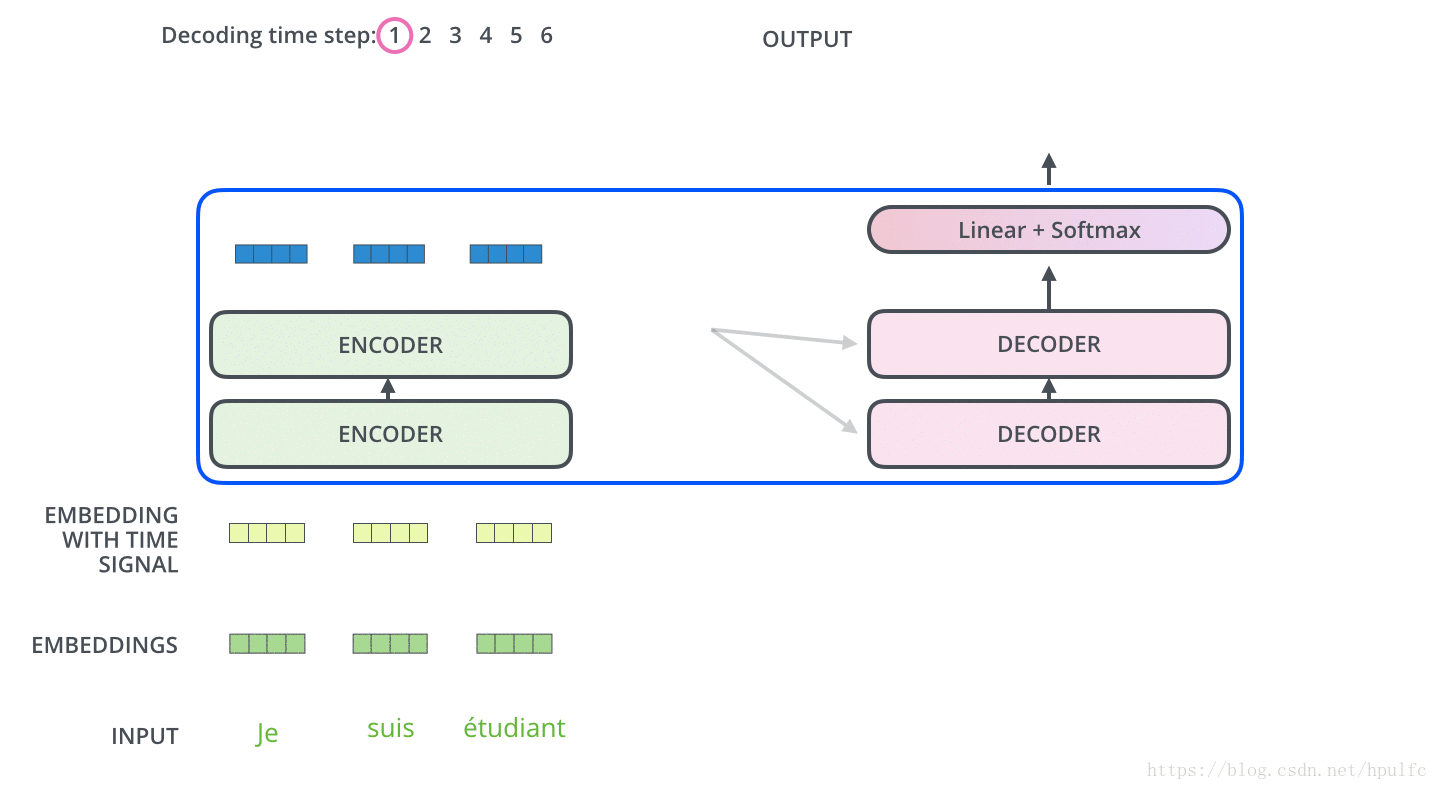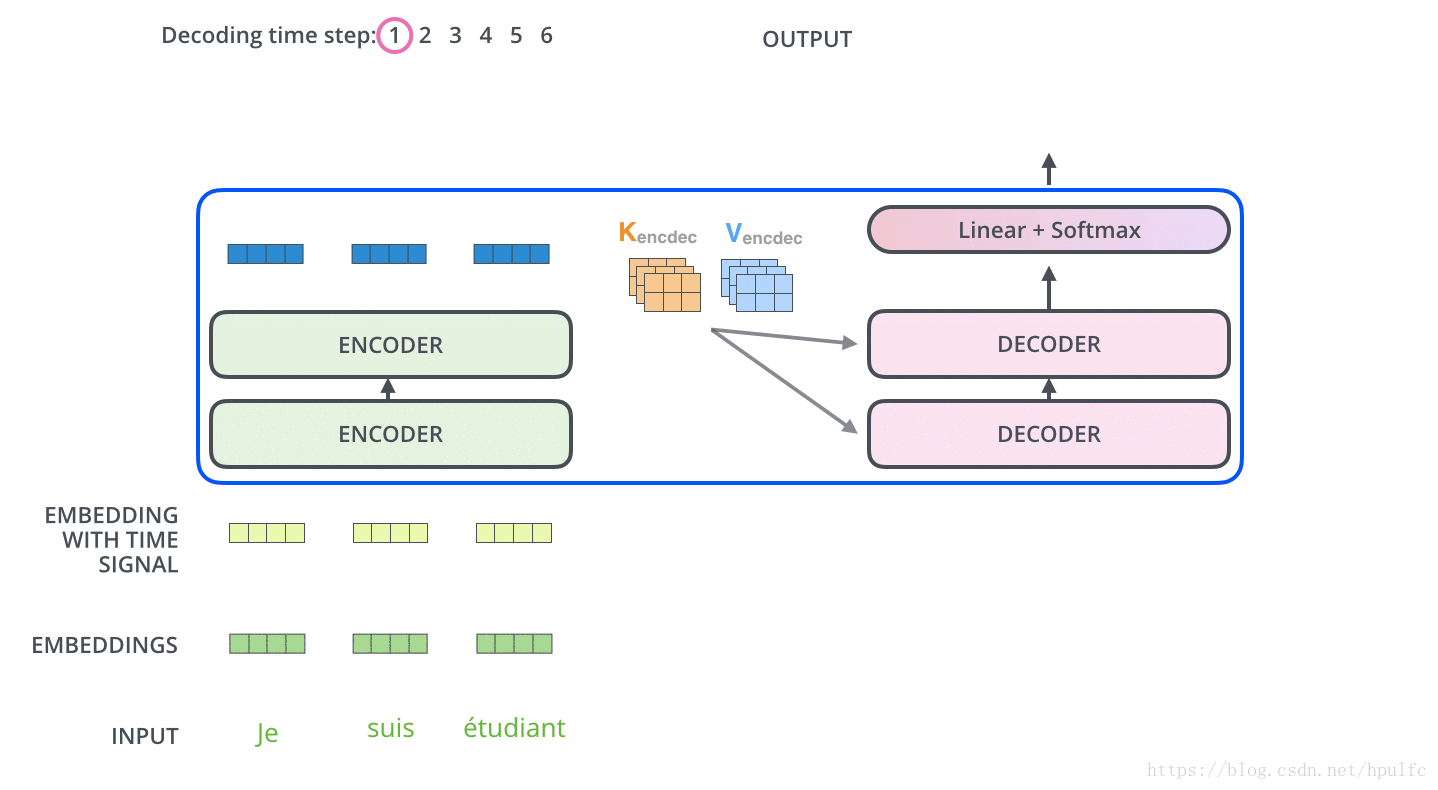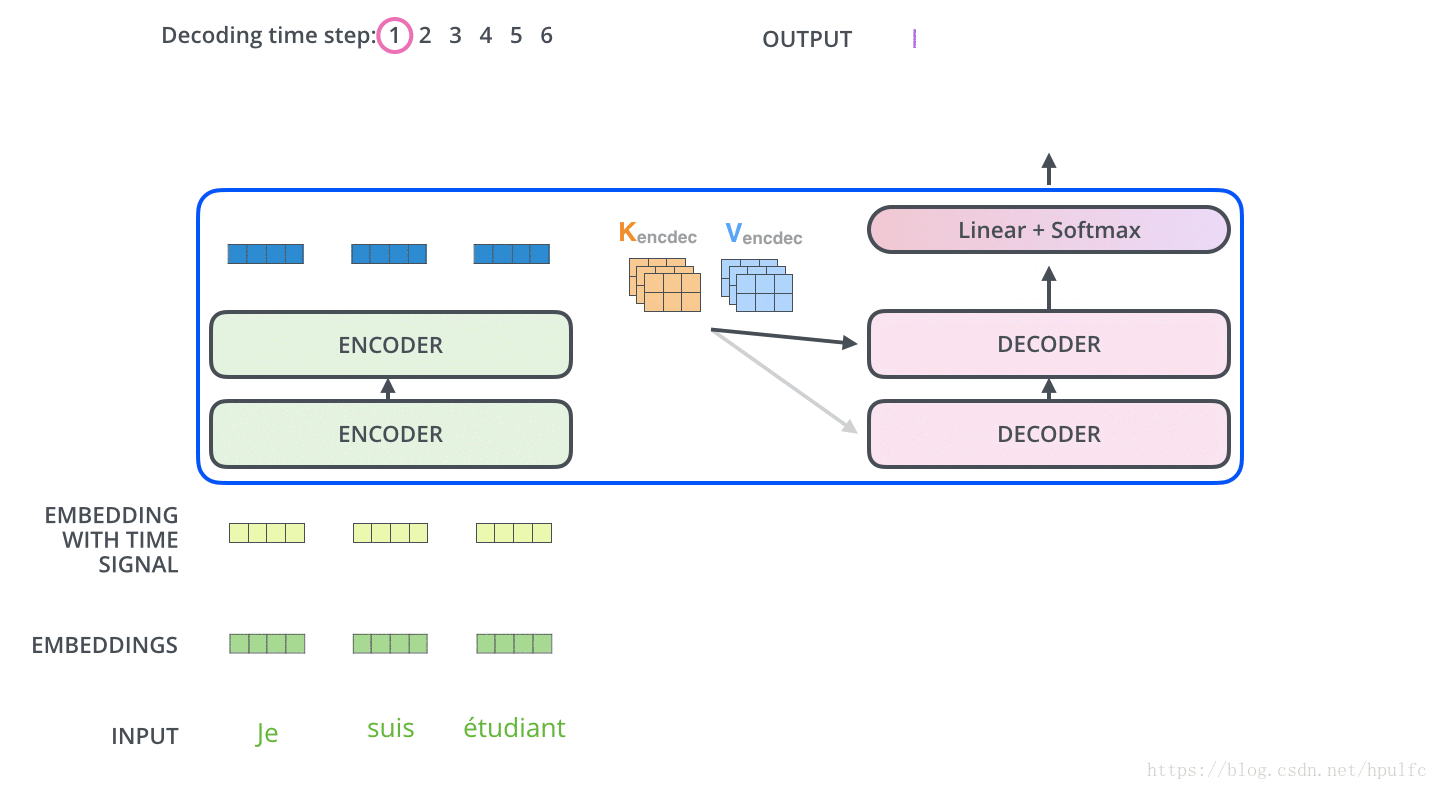
好像是圖片太大,這裡上傳不到csdn伺服器,這裡直接放一個圖片連結
https://jalammar.github.io/images/t/transformer_decoding_2.gif

下面是小尺寸的圖,防止外鏈失效
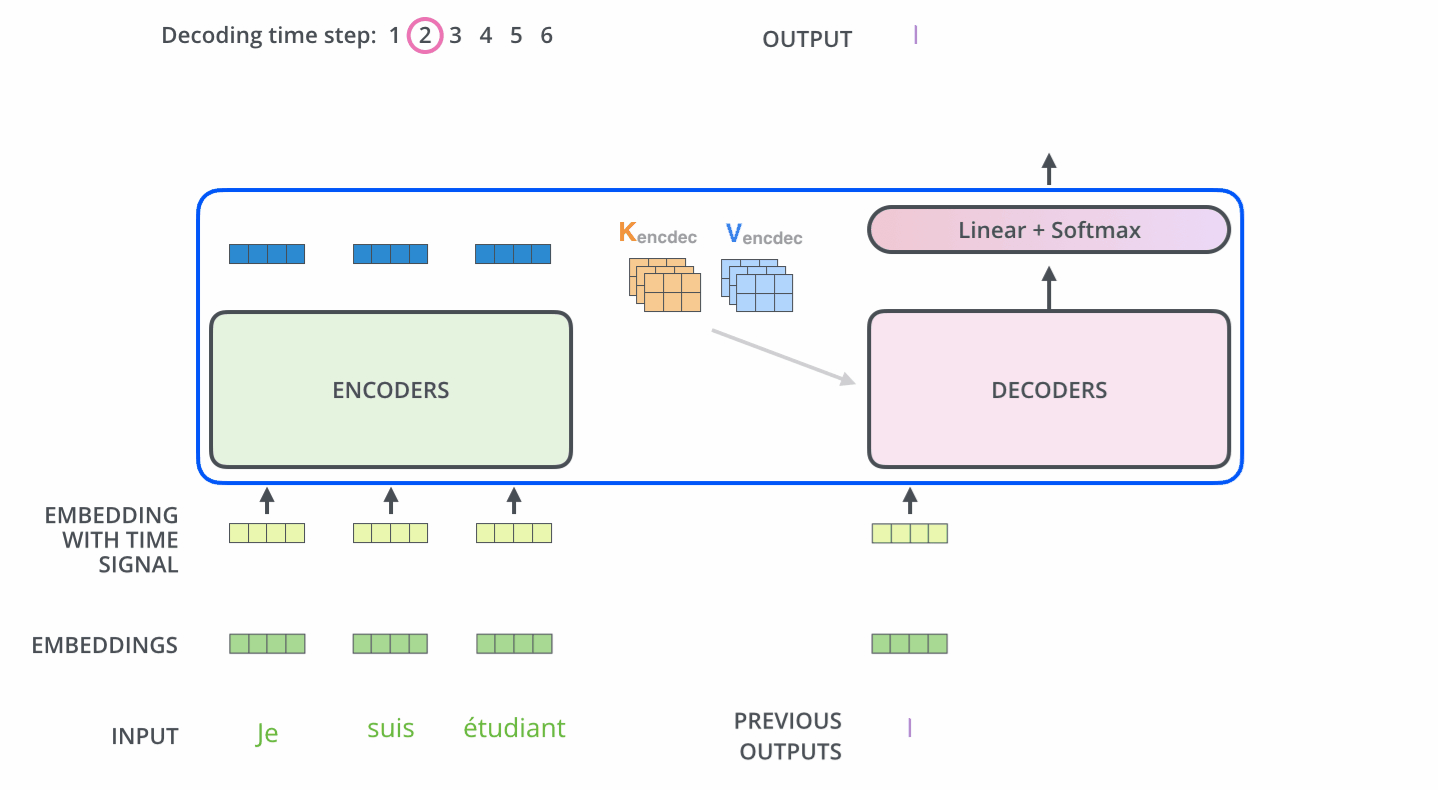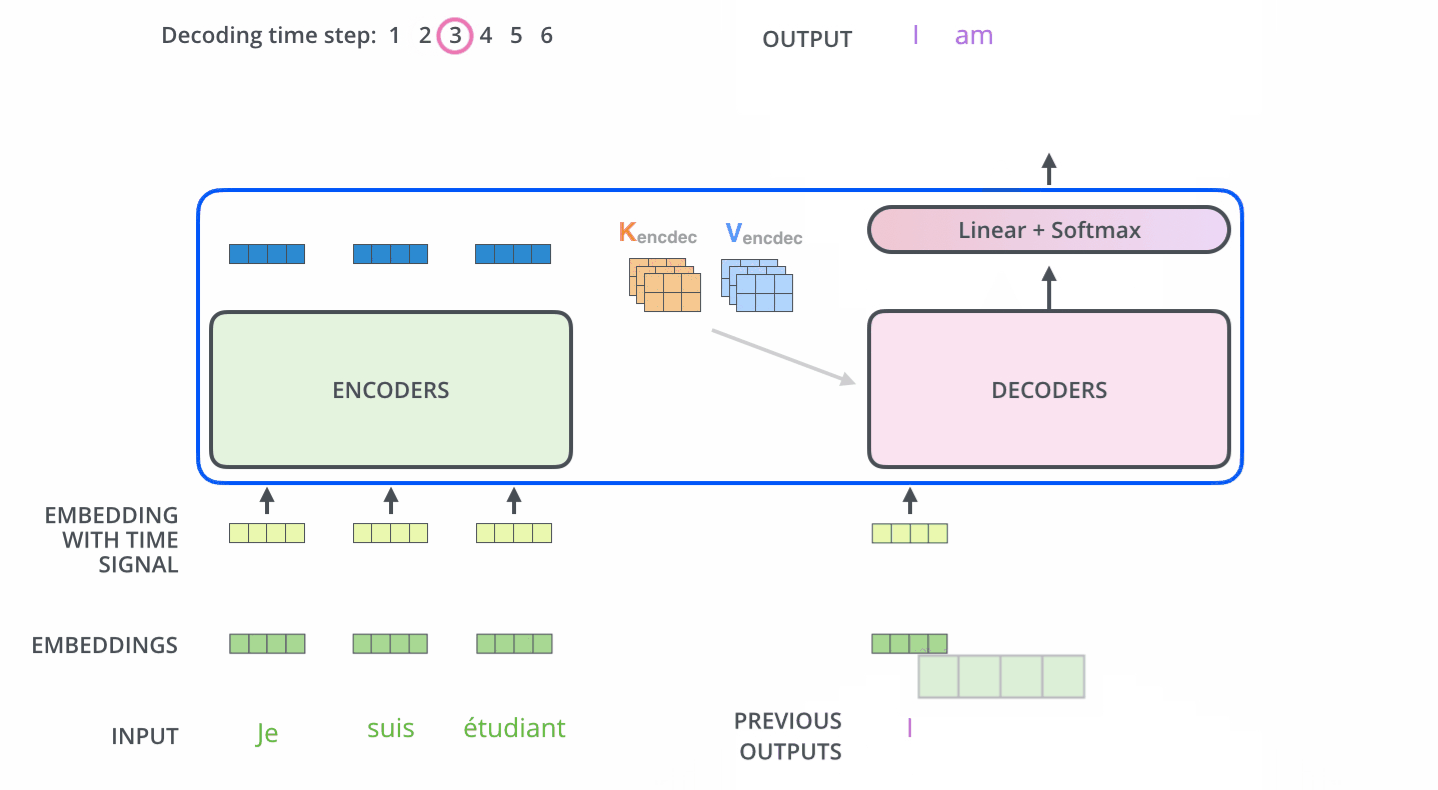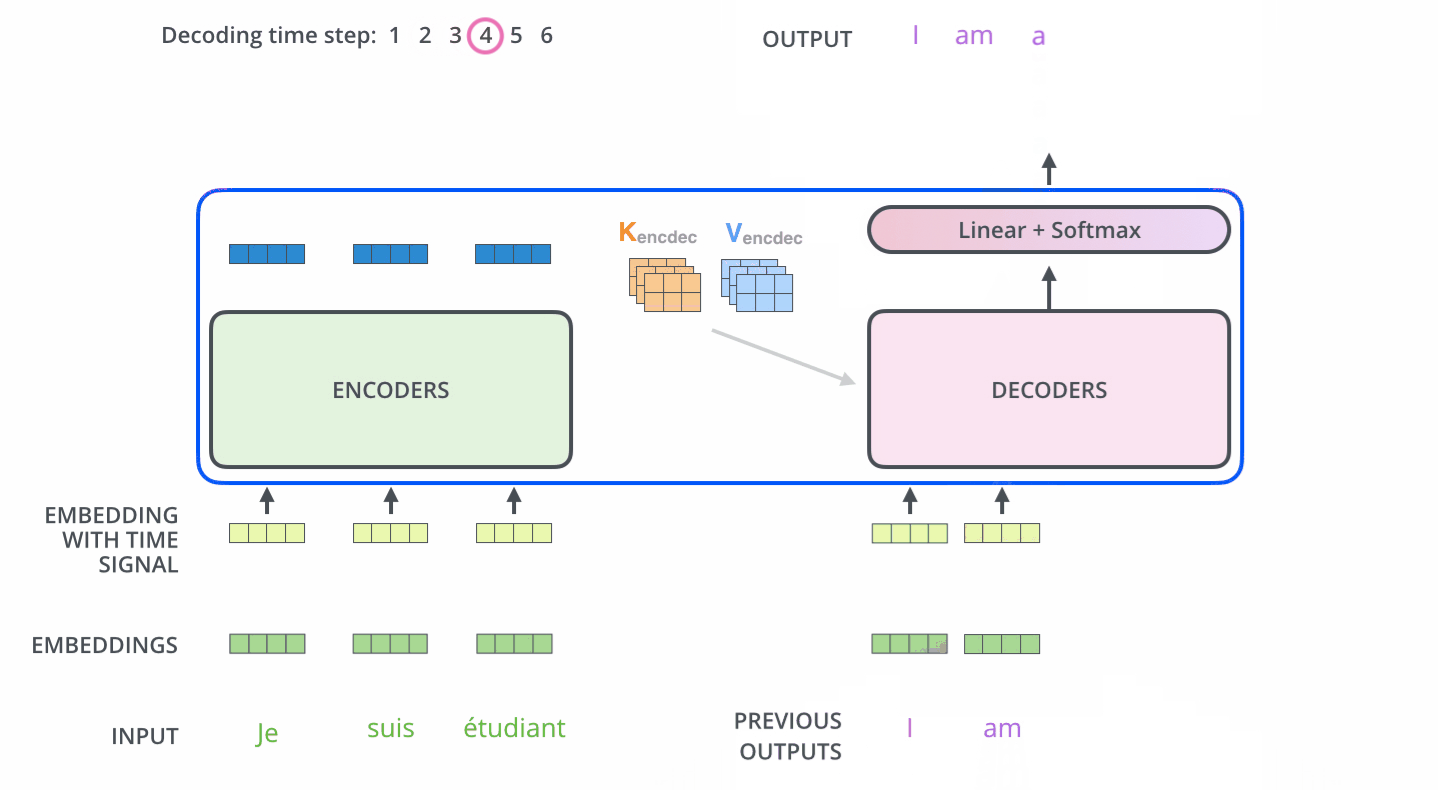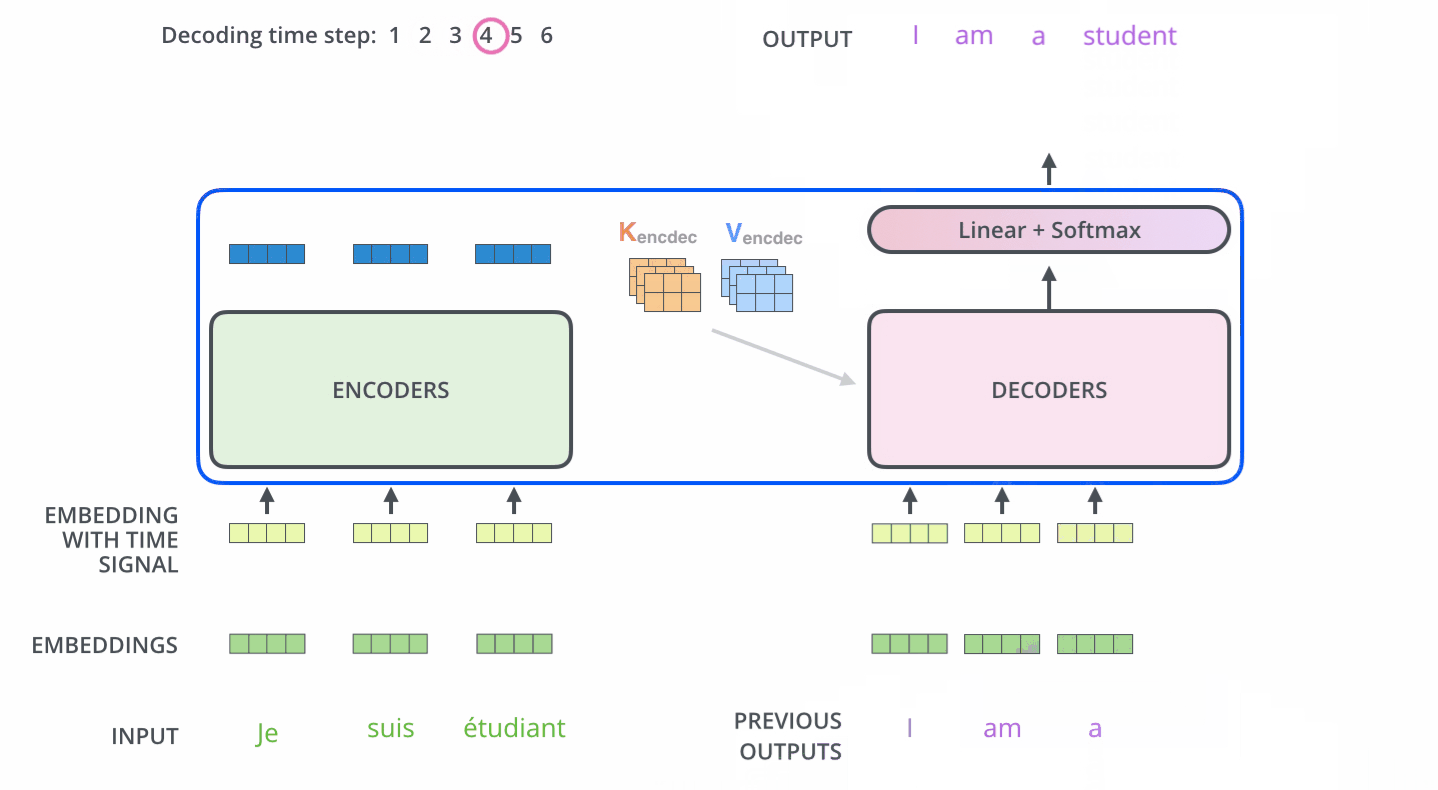
注意:The “Encoder-Decoder Attention” layer works just like multiheaded self-attention, except it creates its Queries matrix from the layer below it, and takes the Keys and Values matrix from the output of the encoder stack.
接下來就是比較關鍵的步驟了,怎麼把 decoder 出來的內容,轉換成人類可讀的詞語。
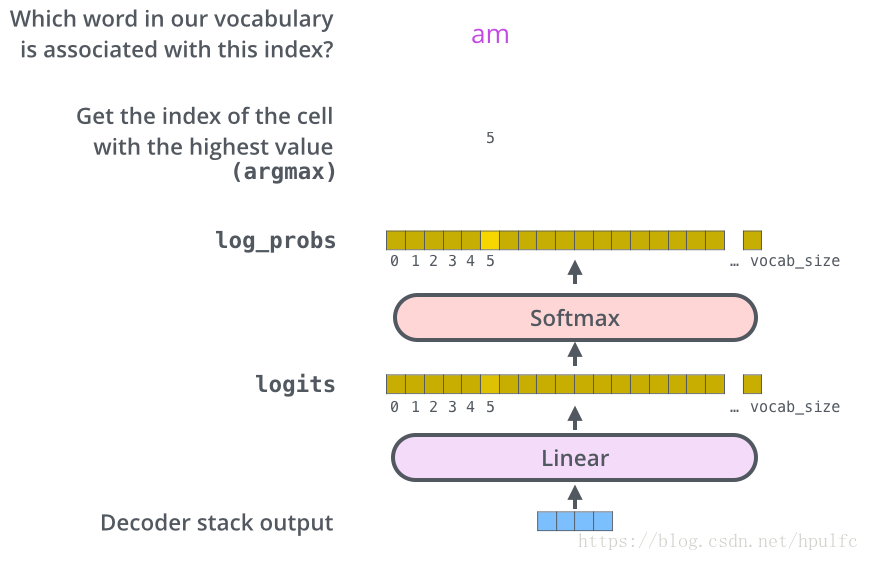
線性迴歸和柔性最大值迴歸層。(翻譯成對應的詞)
作用是什麼呢,線性層就是一個全連線層,將decoder出來的向量 對映到 一個詞表大小的邏輯向量這裡的每一個值都表示這個單詞的分數。 接下來就是 softmax 層了,這個是將這個分數轉換成概率,也就是詞的概率,然後呢從這些單元中選擇最大概率的,並且找到對應的詞,這也就是解碼出了輸出的詞。
如下圖13
上面就是transformer的一些關鍵的地方了,有些地方只是說了怎麼做的,具體做法的原因有些還不太清楚,歡迎有想法的同學一起討論!vx : hpulfc
說的不夠詳細?沒關係,原連結: