
機器學習 - 無監督學習-多元高斯模型
(一)異常檢測---基於高斯(正態)分佈
m個訓練樣本,每個樣本有n個features
即m個樣本的每個屬性集都呈現高斯分佈,因此有以下計算:

例子如下:

(二)評價異常檢測系統
將所有資料按照60%,20%,20%的比例分成三部分,分別為training set、cross validation set和test set.

例子如下:

評價既然採用召回率、準確率和F1值,同時,可以基於CV選擇一個合適的異常引數

(三)異常檢測和監督學習的區別
(1) 異常檢測演算法具有少量的異常樣本和大量的正常樣本,而監督學習演算法有大量的positive和negative樣本。
(2) 異常檢測有很多的異常型別,一般的演算法很難通過少量的異常樣本學習到多有的異常型別,而監督學習演算法有足量的正樣本和負樣本,能夠讓演算法學習到各個樣本的特徵。
(3) 異常檢測中未來還可能出現許多新型別的異常。
(4) 異常檢測演算法用於詐騙識別,工業零件問題檢測等,監督學習演算法用於垃圾郵件的分類,天氣預報和癌症檢測等


(四)異常檢測的引數選取
問題1:樣本資料的某些屬性可能不呈現高斯分佈
解決方案:通過數學變換(log,開根號,平方等)使之呈現高斯分佈。
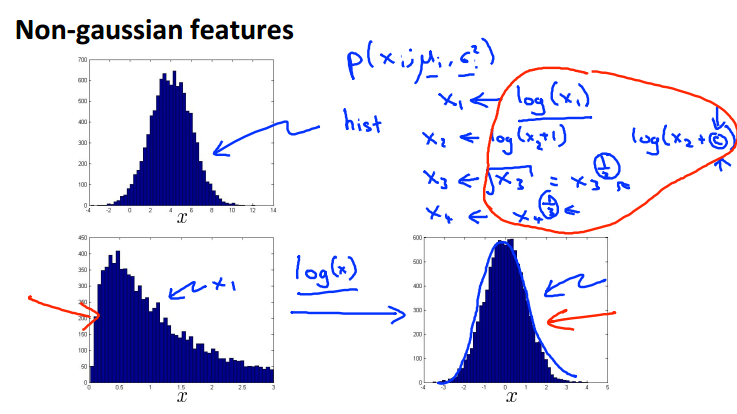
問題2:如何選取有用的features
方法:觀察已有的屬性分佈,畫出高斯分佈圖形,觀察到有些異常樣本被正常樣本包圍,思考原因,這時,可以試著新增一個新的feature,這個新的feature能夠將異常樣本從正常樣本中區分開。對每個不能被區分的樣本進行同樣的思考,這樣就有了能夠將的所有異常樣本區分來的features.

一個例子,如當x1,x2,x,x4不能將異常的computers從一個data center中區分開時,可以試圖新增x5,x6屬性,使之區分開。新新增的屬性可以是已有屬性的數學組合。

(五)多元高斯分佈
將所有的features為軸定義為一個n為空間的高斯分佈,其中均值是一個1*n的矩陣,標差是一個n*n的矩陣。

一些例子如下:
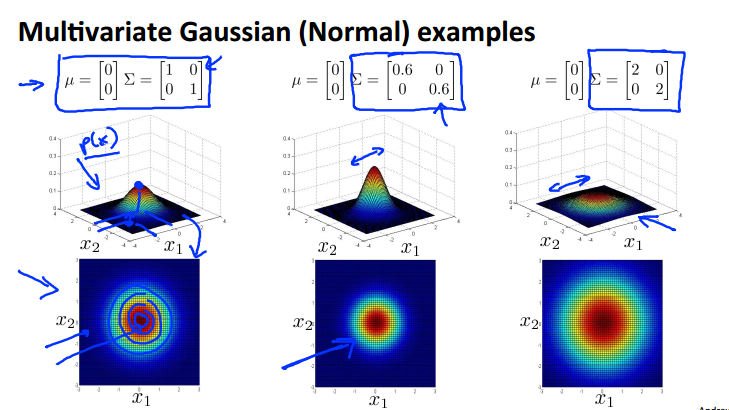



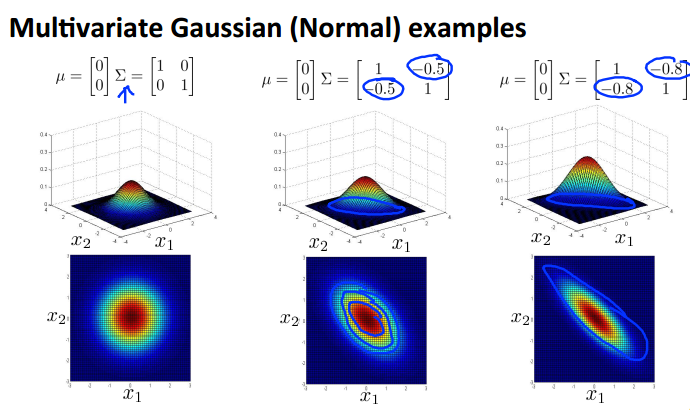
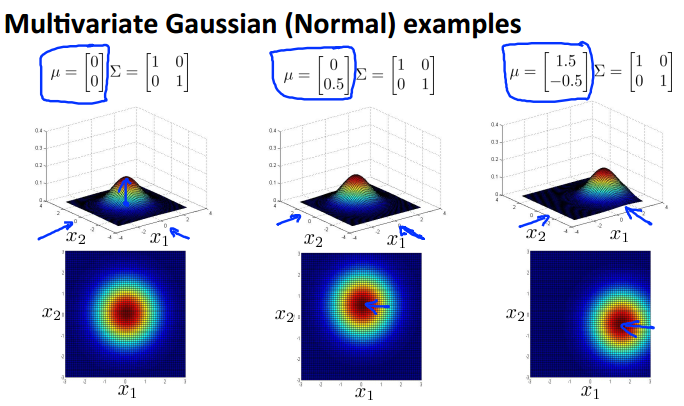
(六)使用多元高斯分佈的異常檢測
1、均值和方差的選取:


2、多遠高斯分佈的異常檢測模型和一般高斯分佈的異常模型的使用區別

版權宣告:本文為博主原創文章,未經博主允許不得轉載。 https://blog.csdn.net/u011470552/article/details/54863529