
4.支援向量機(SVM)演算法(下)
阿新 • • 發佈:2018-11-06
1.SVM演算法的特點
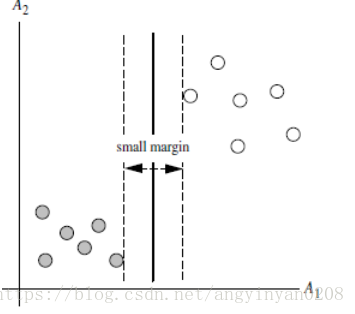

1.1 訓練好的模型的演算法複雜度是由支援向量的個數決定的,而不是由資料的維度決定的。 所有SVM不太容易產生overfitting
1.2 SVM訓練出來的模型完全依賴於支援向量(Support Vectors),即使訓練集裡面所有非支援向量的點都被去除,重複訓練過程,結果仍然會得到完全一樣的模型。
1.3 一個SVM如果訓練得出的支援向量個數比較小,SVM訓練出的模型比較容易被泛化。
2.對於線性不可分的情況(linearly inseparable case)
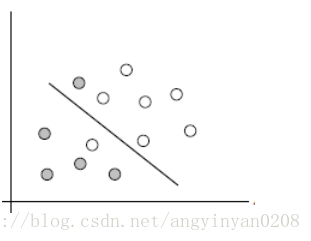
前面也提到如果軟間隔支援向量機允許某些樣本點不滿足,但是當有大量的樣本點不滿足時,則不能使用這個方法了。
2.1兩個步驟來解決:
-
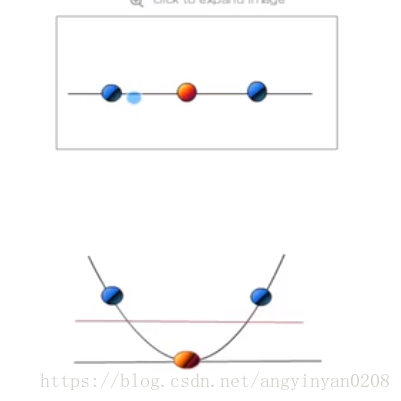
利用一個非線性的對映把原資料集中的向量點轉化到一個更高維度的空間中
-
在這個高維度的空間中找一個線性的超平面來根據線性可分的情況處理
可以觀看這個視訊連線:https://www.youtube.com/watch?v=3liCbRZPrZA
2.2如何利用非線性對映把原始資料轉化
2.2.1舉個簡單的小例子:

2.2.2思考兩個問題:
2.2.2.1如何選擇合理的非線性轉化把資料轉到高維中?
2.2.2.2如何解決計算機內積時演算法複雜度非常高的問題?
2.2.3使用核方法(Kernel trick)
3.核方法(kernel trick)
3.1動機

3.2以下核函式和非線性對映函式的內積等同
常用的核函式:

如何選擇使用哪個kernel?
根據先驗知識,比如影象分類,通常使用RBF,文字不使用RBF
嘗試不同的kernel,根據結果準確度而定。
3.3核函式的簡單小例子

4.SVM擴充套件可解決多個類別分類問題
對於每個類,有一個當前類和其他類的二類分類器(one-vs-rest)