支援向量機(SVM)和python實現(三)
阿新 • • 發佈:2018-12-08
6. python實現
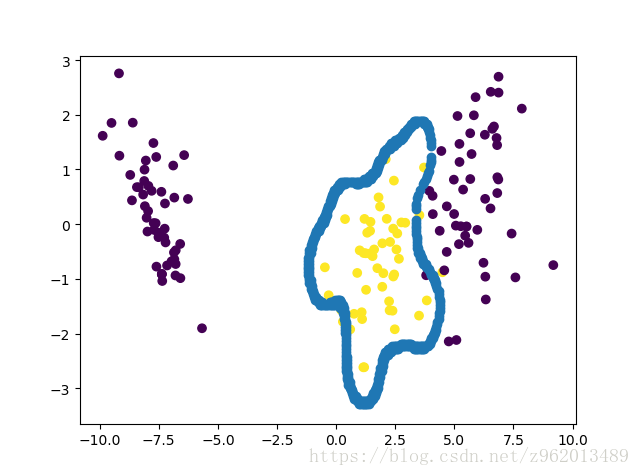
根據前面的一步步推導獲得的結果,我們就可以使用python來實現SVM了 這裡我們使用iris資料集進行驗證,由於該資料集有4維,不容易在二維平面上表示,我們先使用LDA對其進行降維,又因為該資料集有3類樣本,我們編寫的SVM是二分類的,所以我們將獲取的第二個樣本的label設為1,其他兩類樣本的label設為-1
# -*- coding: gbk -*-
import numpy as np
import matplotlib.pyplot as plt
import math
from sklearn.datasets import load_iris
from