
深度學習目標檢測系列:faster RCNN實現|附python原始碼
目標檢測一直是計算機視覺中比較熱門的研究領域,有一些常用且成熟的演算法得到業內公認水平,比如RCNN系列演算法、SSD以及YOLO等。如果你是從事這一行業的話,你會使用哪種演算法進行目標檢測任務呢?在我尋求在最短的時間內構建最精確的模型時,我嘗試了其中的R-CNN系列演算法,如果讀者們對這方面的演算法還不太瞭解的話,建議閱讀《目標檢測演算法圖解:一文看懂RCNN系列演算法》。在掌握基本原理後,下面進入實戰部分。
本文將使用一個非常酷且有用的資料集來實現faster R-CNN,這些資料集具有潛在的真實應用場景。
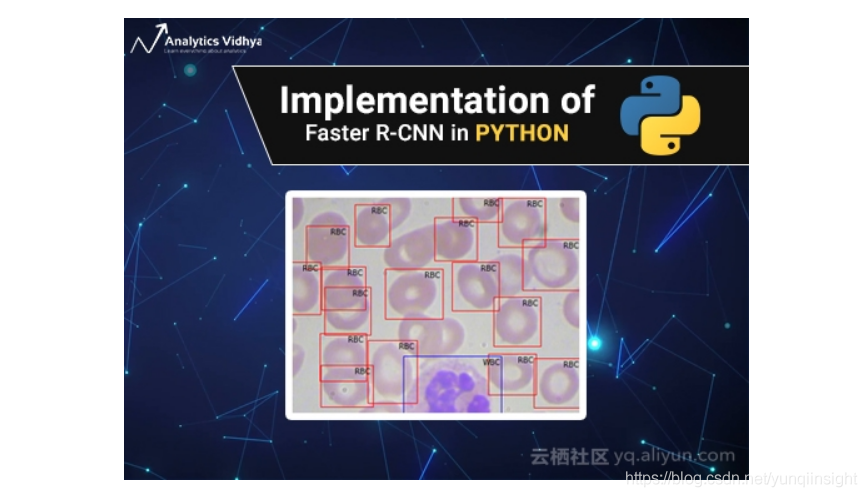
問題陳述
資料來源於醫療相關資料集,目的是解決血細胞檢測問題。任務是通過顯微影象讀數來檢測每張影象中的所有紅細胞(RBC)、白細胞(WBC)以及血小板。最終預測效果應如下所示:
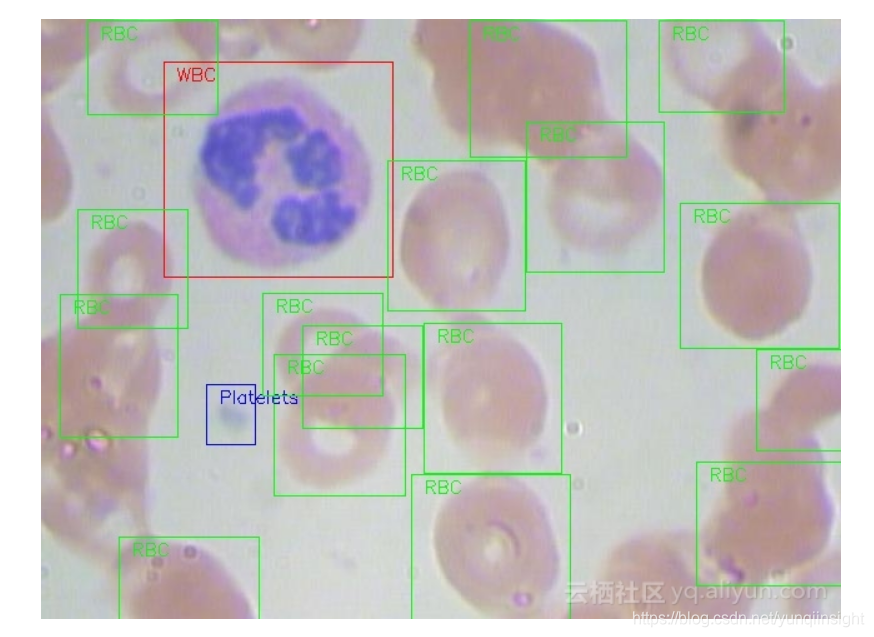
選擇該資料集的原因是我們血液中RBC、WBC和血小板的密度提供了大量關於免疫系統和血紅蛋白的資訊,這些資訊可以幫助我們初步地識別一個人是否健康,如果在其血液中發現了任何差異,我們就可以迅速採取行動來進行下一步的診斷。
通過顯微鏡手動檢視樣品是一個繁瑣的過程,這也是深度學習模式能夠發揮重要作用的地方,一些演算法可以從顯微影象中分類和檢測血細胞,並且達到很高的精確度。
本文采用的血細胞檢測資料集可以從這裡下載,本文稍微修改了一些資料:
- 邊界框已從給定的.xml格式轉換為.csv格式;
- 隨機劃分資料集,得到訓練集和測試集;
這裡使用流行的Keras框架構建本文模型。
系統設定
在真正進入模型構建階段之前,需要確保系統已安裝正確的庫和相應的框架。執行此專案需要以下庫:
- pandas
- matplotlib
- tensorflow
- keras – 2.0.3
- numpy
- opencv-python
- sklearn
- h5py
對於已經安裝了Anaconda和Jupyter的電腦而言,上述這些庫大多數已經安裝好了。建議從
pip install -r requirement.txt系統設定好後,下一步是進行資料處理。
資料探索
首先探索所擁有的資料總是一個好開始(坦率地說,這是一個強制性的步驟)。對資料熟悉有助於挖掘隱藏的模式,還可以獲得對整體的洞察力。本文從整個資料集中建立了三個檔案,分別是:
train_images:用於訓練模型的影象,包含每個影象的類別和實際邊界框;test_images:用於模型預測的影象,該集合缺少對應的標籤;train.csv:包含每個影象的名稱、類別和邊界框座標。一張影象可以有多行資料,因為單張影象可能包含多個物件;
讀取.csv檔案並打印出前幾行:
# importing required libraries
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
from matplotlib import patches
# read the csv file using read_csv function of pandas
train = pd.read_csv(‘train.csv’)
train.head()
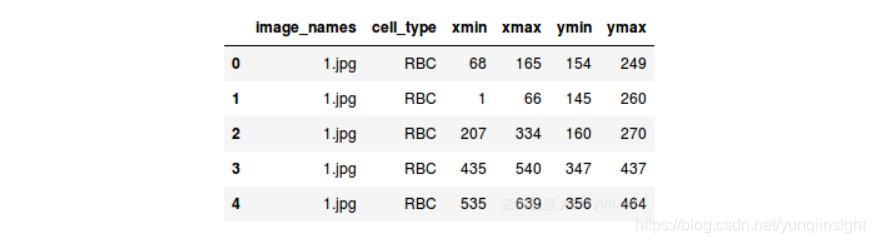
訓練檔案中總共有6列,其中每列代表的內容如下:
image_names:影象的名稱;cell_type:表示單元的型別;xmin:影象左下角的x座標;xmax:影象右上角的x座標;ymin:影象左下角的y座標;ymax:影象右上角的y座標;
下面打印出一張圖片來展示正在處理的影象:
# reading single image using imread function of matplotlib
image = plt.imread('images/1.jpg')
plt.imshow(image)
上圖就是血細胞影象的樣子,其中,藍色部分代表WBC,略帶紅色的部分代表RBC。下面看看整個訓練集中總共有多少張影象和不同型別的數量。
# Number of classes
train['cell_type'].value_counts()結果顯示訓練集有254張影象。
# Number of classes
train['cell_type'].value_counts()結果顯示有三種不同型別的細胞,即RBC,WBC和血小板。最後,看一下檢測到的物件的影象是怎樣的:
fig = plt.figure()
#add axes to the image
ax = fig.add_axes([0,0,1,1])
# read and plot the image
image = plt.imread('images/1.jpg')
plt.imshow(image)
# iterating over the image for different objects
for _,row in train[train.image_names == "1.jpg"].iterrows():
xmin = row.xmin
xmax = row.xmax
ymin = row.ymin
ymax = row.ymax
width = xmax - xmin
height = ymax - ymin
# assign different color to different classes of objects
if row.cell_type == 'RBC':
edgecolor = 'r'
ax.annotate('RBC', xy=(xmax-40,ymin+20))
elif row.cell_type == 'WBC':
edgecolor = 'b'
ax.annotate('WBC', xy=(xmax-40,ymin+20))
elif row.cell_type == 'Platelets':
edgecolor = 'g'
ax.annotate('Platelets', xy=(xmax-40,ymin+20))
# add bounding boxes to the image
rect = patches.Rectangle((xmin,ymin), width, height, edgecolor = edgecolor, facecolor = 'none')
ax.add_patch(rect)
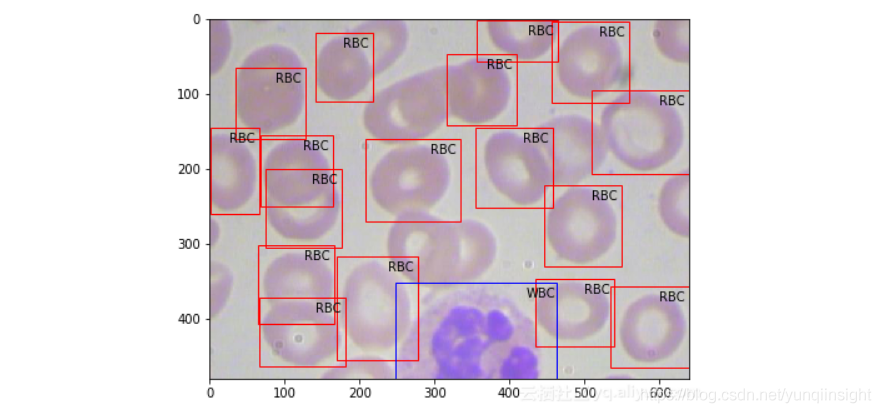
上圖就是訓練樣本示例,從中可以看到,細胞有不同的類及其相應的邊界框。下面進行模型訓練,本文使用keras_frcnn庫來訓練搭建的模型以及對測試影象進行預測。
faster R-CNN實現
為了實現 faster R-CNN演算法,本文遵循此Github儲存庫中提到的步驟。因此,首先請確保克隆好此儲存庫。開啟一個新的終端視窗並鍵入以下內容以執行此操作:
git clone https://github.com/kbardool/keras-frcnn.git 並將train_images和test_images資料夾以及train.csv檔案移動到該儲存庫目錄下。為了在新資料集上訓練模型,輸入的格式應為:
filepath,x1,y1,x2,y2,class_name其中:
- filepath是訓練影象的路徑;
- x1是邊界框的xmin座標;
- y1是邊界框的ymin座標;
- x2是邊界框的xmax座標;
- y2是邊界框的ymax座標;
- class_name是該邊界框中類的名稱;
這裡需要將.csv格式轉換為.txt檔案,該檔案具有與上述相同的格式。建立一個新的資料幀,按照格式將所有值填入該資料幀,然後將其另存為.txt檔案。
data = pd.DataFrame()
data['format'] = train['image_names']
# as the images are in train_images folder, add train_images before the image name
for i in range(data.shape[0]):
data['format'][i] = 'train_images/' + data['format'][i]
# add xmin, ymin, xmax, ymax and class as per the format required
for i in range(data.shape[0]):
data['format'][i] = data['format'][i] + ',' + str(train['xmin'][i]) + ',' + str(train['ymin'][i]) + ',' + str(train['xmax'][i]) + ',' + str(train['ymax'][i]) + ',' + train['cell_type'][i]
data.to_csv('annotate.txt', header=None, index=None, sep=' ') 下一步進行模型訓練,使用train_frcnn.py檔案來訓練模型。
cd keras-frcnn
python train_frcnn.py -o simple -p annotate.txt 由於資料集較大,需要一段時間來訓練模型。如果條件滿足的話,可以使用GPU來加快訓練過程。同樣也可以嘗試減少num_epochs引數來加快訓練過程。
模型每訓練好一次(有改進時),該特定時刻的權重將儲存在與“model_frcnn.hdf5”相同的目錄中。當對測試集進行預測時,將使用到這些權重。
根據機器的配置,可能需要花費大量時間來訓練模型並獲得權重。建議使用本文訓練大約500個時期的權重作為初始化。可以從這裡下載這些權重,並設定好相應的路徑。
因此,當模型訓練好並儲存好權重後,下面進行預測。Keras_frcnn對新影象進行預測並將其儲存在新資料夾中,這裡只需在test_frcnn.py檔案中進行兩處更改即可儲存影象:
-
從該檔案的最後一行刪除註釋:
- cv2.imwrite('./ results_imgs / {}。png'.format(idx),img);
-
在此檔案的倒數第二行和第三行添加註釋:
- #cv2.imshow('img',img) ;
- #cv2.waitKey(0);
使用下面的程式碼進行影象預測:
python test_frcnn.py -p test_images最後,檢測到物件的影象將儲存在“results_imgs”資料夾中。以下是本文實現faster R-CNN後預測幾個樣本獲得的結果:
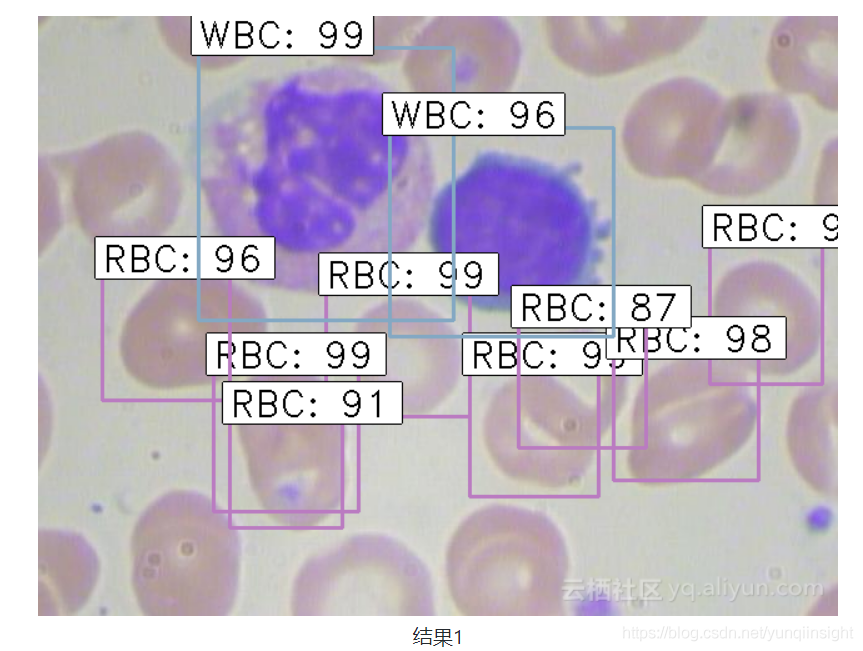

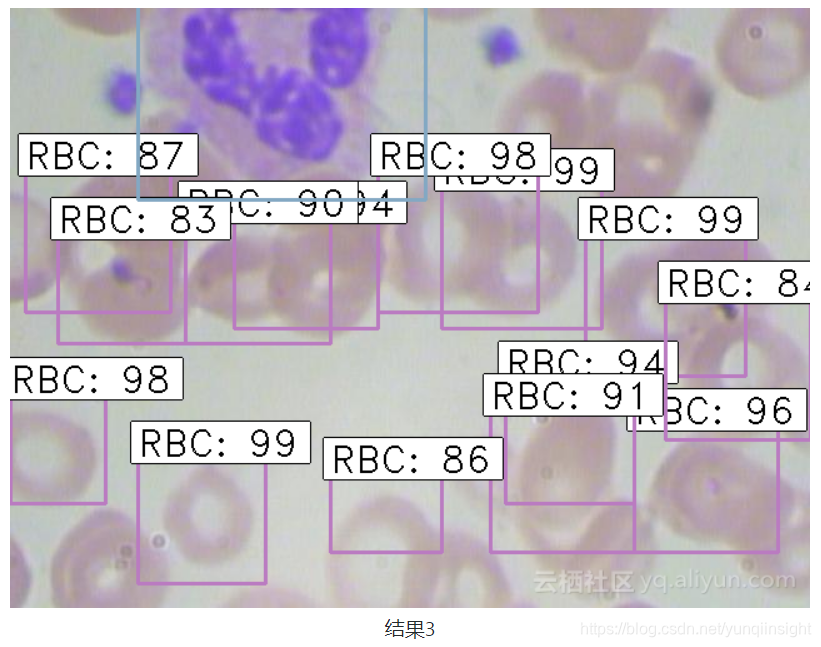
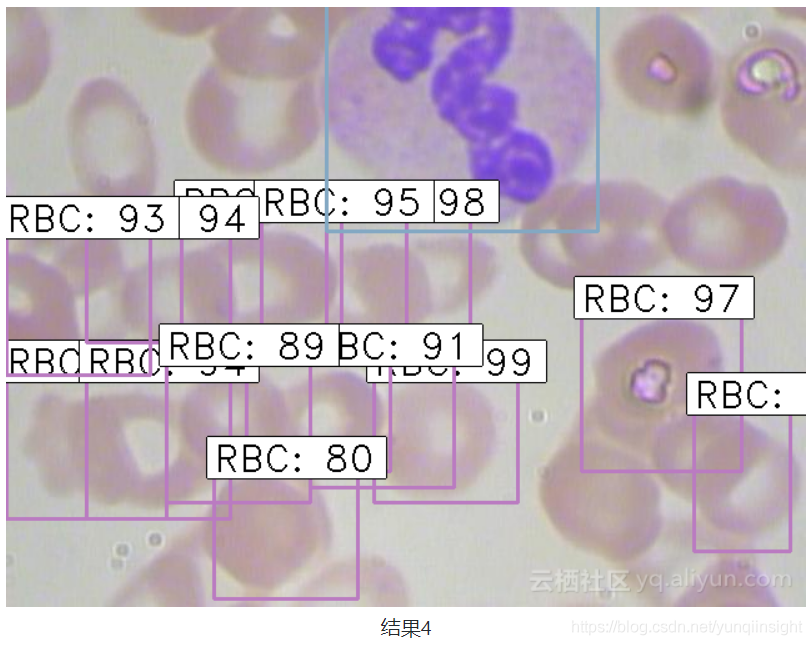
總結
R-CNN演算法確實是用於物件檢測任務的變革者,改變了傳統的做法,並開創了深度學習演算法。近年來,計算機視覺應用的數量突然出現飆升,而R-CNN系列演算法仍然是其中大多數應用的核心。
Keras_frcnn也被證明是一個很好的物件檢測工具庫,在本系列的下一篇文章中,將專注於更先進的技術,如YOLO,SSD等。
原文連結
本文為雲棲社群原創內容,未經允許不得轉載。