
如何建立資料分析的思維框架
本文是《如何七週成為資料分析師》的第八篇教程,如果想要了解寫作初衷,可以先行閱讀七週指南。溫馨提示:如果您已經熟悉資料分析思維,大可不必再看這篇文章,或只挑選部分。
曾經有人問過我,什麼是資料分析思維?如果分析思維是一種結構化的體現,那麼資料分析思維在它的基礎上再加一個準則:
不是我覺得,而是資料證明
這是一道分水嶺,“我覺得”是一種直覺化經驗化的思維,工作不可能處處依賴自己的直覺,公司發展更不可能依賴於此。資料證明則是資料分析的最直接體現,它依託於資料導向型的思維,而不是技巧,前者是指導,後者只是應用。
作為個人,應該如何建立資料分析思維呢?
建立你的指標體系
在我們談論指標之前,先將時間倒推幾十年,現代管理學之父彼得·德魯克說過一句很經典的話:
如果你不能衡量它,那麼你就不能有效增長它。
所謂衡量,就是需要統一標準來定義和評價業務。這個標準就是指標。假設隔壁老王開了一家水果鋪子,你問他每天生意怎麼樣,他可以回答賣的不錯,很好,最近不景氣。這些都是很虛的詞,因為他認為賣的不錯也許是賣了50個,而你認為的賣的不錯,是賣了100。
這就是“我覺得”造成的認知陷阱。將案例放到公司時,會遇到更多的問題:若有一位運營和你說,產品表現不錯,因為每天都有很多人評價和稱讚,還給你看了幾個截圖。而另外一位運營說,產品有些問題,推的活動商品賣的不好,你應該相信誰呢?
其實誰都很難相信,這些眾口異詞的判斷都是因為缺乏資料分析思維造成的。
老王想要描述生意,他應該使用銷量,這就是他的指標,網際網路想要描述產品,也應該使用活躍率、使用率、轉化率等指標。
如果你不能用指標描述業務,那麼你就不能有效增長它。
瞭解和使用指標是資料分析思維的第一步,接下來你需要建立指標體系,孤立的指標發揮不出資料的價值。和分析思維一樣,指標也能結構化,也應該用結構化。
我們看一下網際網路的產品,一個使用者從開始使用到離開,都會經歷這些環節步驟。電商APP還是內容平臺,都是雷同的。想一想,你會需要用到哪些指標?
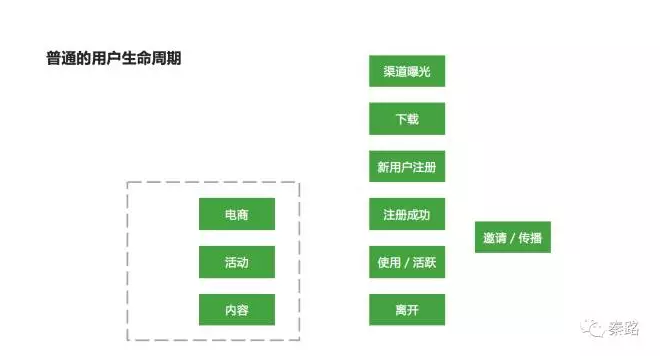
而下面這張圖,解釋了什麼是指標化,這就是有無資料分析思維的差異,也是典型的資料化運營,有空可以再深入講這塊。

指標體系沒有放之四海而皆準的模板,不同業務形態有不同的指標體系。移動APP和網站不一樣,SaaS和電子商務不一樣,低頻消費和高頻消費不一樣。好比一款婚慶相關的APP,不需要考慮復購率指標;網際網路金融,必須要風控指標;電子商務,賣家和買家的指標各不一樣。
這些需要不同行業經驗和業務知識去學習掌握,那有沒有通用的技巧和注意事項呢?
好指標與壞指標
不是所有的指標都是好的。這是初出茅廬者常犯的錯誤。我們繼續回到老王的水果鋪子,來思考一下,銷量這個指標究竟是不是好的?
最近物價上漲,老王順應調高了水果價格,又不敢漲的提高,雖然水果銷量沒有大變化,但老王發現一個月下來沒賺多少,私房錢都不夠存。
老王這個月的各類水果銷量有2000,但最後還是虧本了,仔細研究後發現,雖然銷量高,但是水果庫存也高,每個月都有幾百單位的水果滯銷最後過期虧本。
這兩個例子都能說明只看銷量是一件多不靠譜的事情。銷量是一個衡量指標,但不是好指標。老王這種個體經營戶,應該以水果鋪子的利潤為核心要素。
好指標應該是核心驅動指標。雖然指標很重要,但是有些指標需要更重要。就像銷量和利潤,使用者數和活躍使用者數,後者都比前者重要。
核心指標不只是寫在週報的數字,而是整個運營團隊、產品團隊乃至研發團隊都統一努力的目標。
核心驅動指標和公司發展關聯,是公司在一個階段內的重點方向。記住是一個階段,不同時期的核心驅動指標不一樣。不同業務的核心驅動指標也不一樣。
網際網路公司常見的核心指標是使用者數和活躍率,使用者數代表市場的體量和佔有,活躍率代表產品的健康度,但這是發展階段的核心指標。在產品1.0期間,我們應把注意力放到打磨產品上,在大推廣前提高產品質量,這時留存率是一個核心指標。而在有一定使用者基數的產品後期,商業化比活躍重要,我們會關注錢相關的指標,比如廣告點選率、利潤率等。
核心驅動指標一般是公司整體的目標,若從個人的崗位職責看,也可以找到自己的核心指標。比如內容運營可以關注閱讀數和閱讀時長。
核心驅動指標一定能給公司和個人帶來最大優勢和利益,記得二八法則麼?20%的指標一定能帶來80%的效果,這20%的指標就是核心。
另外一方面,好的指標還有一個特性,它應該是比率或者比例。
拿活躍使用者數說明就懂了,我們活躍使用者有10萬,這能說明什麼呢?這說明不了什麼。如果產品本身有千萬級別的註冊使用者,那麼10萬用戶說明非常不健康,產品在衰退期。如果產品只擁有四五十萬使用者,那麼說明產品的粘性很高。
正因為單純的活躍使用者數沒有多大意義,所以運營和產品會更關注活躍率。這個指標就是一個比率,將活躍使用者數除以總使用者數所得。所以在設立指標時,我們都儘量想它能不能是比率。
壞指標有哪些呢?
其一是虛榮指標,它沒有任何的實際意義。
產品在應用商店有幾十萬的曝光量,有意義嗎?沒有,我需要的是實際下載。下載了意義大嗎?也不大,我希望使用者註冊成功。曝光量和下載量都是虛榮指標,只是虛榮程度不一樣。
新媒體都追求微信公眾號閱讀數,如果靠閱讀數做廣告,那麼閱讀數有意義,如果靠圖文賣商品,那麼更應該關注轉化率和商品銷量,畢竟一個誇張的標題就能帶來很高的閱讀量,此時的閱讀量是虛榮指標。可惜很多老闆還是孜孜不倦的追求10W+,哪怕刷量。
虛榮指標是沒有意義的指標,往往它會很好看,能夠粉飾運營和產品的工作績效,但我們要避免使用。
第二個壞指標是後驗性指標,它往往只能反應已經發生的事情。
比如我有一個流失使用者的定義:三個月沒有開啟APP就算做流失。那麼運營每天統計的流失使用者數,都是很久沒有開啟過的,以時效性看,已經發生很久了,也很難通過措施挽回。我知道曾經因為某個不好的運營手段傷害了使用者,可是還有用嗎?
活動運營的ROI(投資回報率)也是後驗性指標,一個活動付出成本後才能知道其收益。可是成本已經支出,活動的好與壞也註定了。活動週期長,還能有調整餘地。活動短期的話,這指標只能用作覆盤,但不能驅動業務。
第三個壞指標是複雜性指標,它將資料分析陷於一堆指標造成的陷阱中。
指標能細分和拆解,比如活躍率可以細分成日活躍率、周活躍率、月活躍率、老使用者活躍率等。資料分析應該根據具體的情況選擇指標,如果是天氣類工具,可以選擇日活躍率,如果是社交APP,可以選擇周活躍率,更低頻的產品則是月活躍率。
每個產品都有適合它的幾個指標,不要一股腦的裝一堆指標上去,當你準備了二三十個指標用於分析,會發現無從下手。
指標結構
既然指標太多太複雜不好,那麼應該如何正確的選擇指標呢?
和分析思維的金字塔結構一樣,指標也有固有結構,呈現樹狀。指標結構的構建核心是以業務流程為思路,以結構為導向。
假設你是內容運營,需要對現有的業務做一個分析,提高內容相關資料,你會怎麼做呢?
我們把金字塔思維轉換一下,就成了資料分析方法了。
從內容運營的流程開始,它是:內容收集—內容編輯釋出—使用者瀏覽—使用者點選—使用者閱讀—使用者評論或轉發—繼續下一篇瀏覽。
這是一個標準的流程,每個流程都有指標可以建立。內容收集可以建立熱點指數,看哪一篇內容比較火。使用者瀏覽使用者點選則是標準的PV和UV統計,使用者閱讀是閱讀時長。
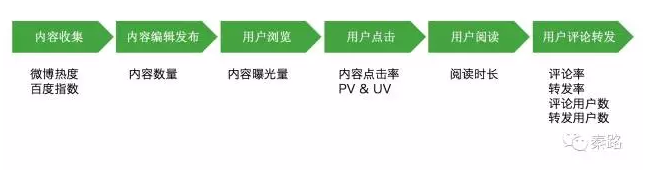
從流程的角度搭建指標框架,可以全面的囊括使用者相關資料,無有遺漏。
這套框架列舉的指標,依舊要遵循指標原則:需要有核心驅動指標。移除虛榮指標,適當的進行刪減,不要為新增指標而新增指標。
維度分析法
當你有了指標,可以著手進行分析,資料分析大體可以分三類,第一類是利用維度分析資料,第二類是使用統計學知識如資料分佈假設檢驗,最後一類是使用機器學習。我們先了解一下維度分析法。
維度是描述物件的引數,在具體分析中,我們可以把它認為是分析事物的角度。銷量是一種角度、活躍率是一種角度,時間也是一種角度,所以它們都能算維度。
當我們有了維度後,就能夠通過不同的維度組合,形成資料模型。資料模型不是一個高深的概念,它就是一個數據立方體。

上圖就是三個維度組成的資料模型/資料立方體。分別是產品型別、時間、地區。我們既能獲得電子產品在上海地區的2010二季度的銷量,也能知道書籍在江蘇地區的2010一季度銷量。
資料模型將複雜的資料以結構化的形式有序的組織起來。我們之前談到的指標,都可以作為維度使用。下面是範例:
將使用者型別、活躍度、時間三個維度組合,觀察不同使用者群體在產品上的使用情況,是否A群體使用的時長更明顯?
將商品型別、訂單金額、地區三個維度組合,觀察不同地區的不同商品是否存在銷量差異?
資料模型可以從不同的角度和層面來觀察資料,這樣提高了分析的靈活性,滿足不同的分析需求、這個過程叫做OLAP(聯機分析處理)。當然它涉及到更復雜的資料建模和資料倉庫等,我們不用詳細知道。
資料模型還有幾種常見的技巧、叫做鑽取、上卷、切片。
選取就是將維度繼續細分。比如浙江省細分成杭州市、溫州市、寧波市等,2010年一季度變成1月、2月、3月。上卷則是鑽取的相反概念,將維度聚合,比如浙江、上海、江蘇聚合成浙江滬維度。切片是選中特定的維度,比如只選上海維度、或者只選2010年一季度維度。因為資料立方體是多維的,但我們觀察和比較資料只能在二維、即表格中進行。
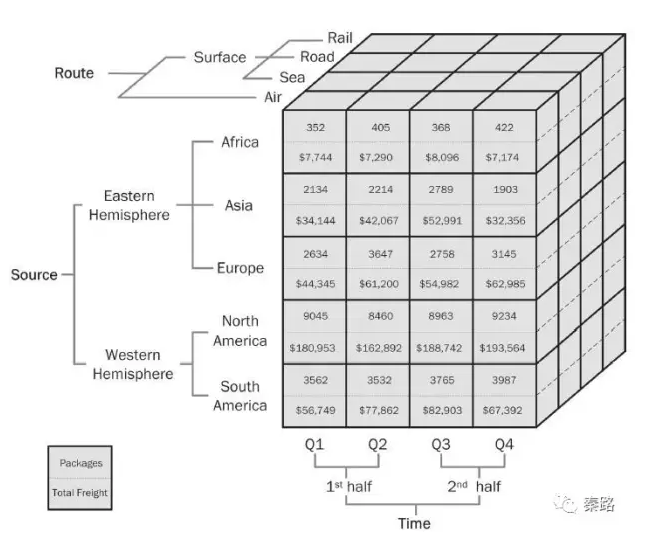
上圖的樹狀結構代表鑽取(source和time的細分),然後通過對Route的air切片獲得具體資料。
聰明的你可能已經想到,我們常用的資料透視表就是一種維度分析,將需要分析的維度放到行列組合進行求和、計數、平均值等計算。放一張曾經用到的案例圖片:用城市維度和工作年限維度,計算平均工資。
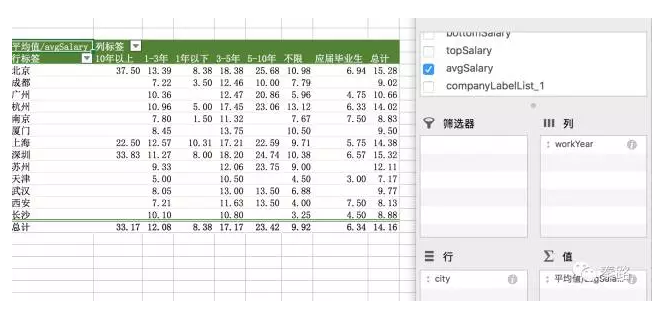
除了Excel、BI、R、Python都能用維度分析法。BI是相對最簡便的。
談到維度法,想要強調的是分析的核心思維之一:對比,不同維度的對比,這大概是對新人快速提高的最佳捷徑之一。比如過去和現在的時間趨勢對比,比如不同地區維度的對比,比如產品型別的區別對比,比如不同使用者的群體對比。單一的資料沒有分析意義,只有多個數據組合才能發揮出資料的最大價值。
我想要分析公司的利潤,利潤 = 銷售額 - 成本。那麼找出銷售額涉及的指標/維度,比如產品型別、地區、使用者群體等,通過不斷的組合和拆解,找出有問題或者表現良好的原因。成本也是同理。
這就是正確的資料分析思維。總結一下吧:我們通過業務建立和篩選出指標,將指標作為維度,利用維度進行分析。
很多人會問,指標和維度有什麼區別?
維度是說明和觀察事物的角度,指標是衡量資料的標準。維度是一個更大的範圍,不只是資料,比如時間維度和城市維度,我們就無法用指標表示,而指標(留存率、跳出率、瀏覽時間等)卻可以成為維度。通俗理解:維度>指標。
到這裡,大家已經有一個數據分析的思維框架了。之所以是框架,因為還缺少具體的技巧,比如如何驗證某一個維度是影響資料的關鍵,比如如何用機器學習提高業務,這些涉及到資料和統計學知識,以後再講解。
這裡我想強調,資料分析並不是一個結果,只是過程。還記得“如果你不能衡量它,那麼你就不能有效增長它”這句話嗎?資料分析的最終目的就是增長業務。如果資料分析需要績效指標,一定不會是分析的對錯,而是最終資料提升的結果。
資料分析是需要反饋的,當我分析出某項要素左右業務結果,那麼就去驗證它。告訴運營和產品人員,看看改進後的資料怎麼樣,一切以結果為準。如果結果並沒有改善,那麼就應該反思分析過程了。
這也是資料分析的要素,結果作導向。分析若只是當一份報告呈現上去,後續沒有任何跟進、改進的措施,那麼資料分析等與零。
業務指導資料,資料驅動業務。這才是不二法門。
——————
解答上篇文章的思考題,可能大家等急了。
你是淘寶的資料分析師,現在需要你預估雙十一的銷量,你不能獲得雙十一當天和之前的所有資料。只能獲得11月12日開始的資料,你應該如何預估?
因為是開放題,所以沒有固定答案。
大家的回答分為兩類:
一類是通過後續雙十一的銷量,判斷16年,缺點是需要等一年,優點是簡單到不像話。
二類是通過11月12日之後的銷量資料,往前預估,期間會考慮一些權重。缺點是雙十一屬於波峰,預估難道大,優點是可操作性好。
因為題目主要看的是分析思維,目的是找出可能的思路,所以有沒有其他的方法呢?
我們嘗試把思維放開,因為銷量能反應商品,有沒有其他維度?我們可能會想到:退換貨率、和商品評價率。因為雙十一的商品只能在12日後退換貨和收貨後評價,我們就能根據這兩個指標平日的平均比率,以及雙十一商品的後續退換和評價總數,預估賣出總量。退換貨率肯定會虛高一些(畢竟雙十一退貨不少),那麼商品評價率更準確。
還有其他方法麼?當然有,比如會有不少人用螞蟻花唄支付雙十一,那麼後續還款的比率能不能預估?
如果再將思路放開呢?雖然我不知道淘寶當天的資料,但是可以尋求外部資料,比如京東,京東的雙十一銷量是多少,是平時的多少倍,那麼就用這個倍數去預估淘寶的。
整體的分析結構就分為:
外部資料:
京東等其他平臺雙十一銷量
內部資料:
商品資料:商品評價率、退換貨率、商品銷量
支付資料:螞蟻花唄支付比率等
