
Apache Flink-使用者場景
Apache Flink在需要執行各種型別的應用程式方面是個不錯的選擇,因為其具有豐富的特徵集。Flink的特徵包含了處理流和批處理,複雜的狀態管理,事件時間處理語義和對狀態的"正好一次"一致性保證。而且,Flink可以部署在不同的資源管理器之上,如YARN,Apache Mesos,和k8s,但是也可以在裸機上單獨的叢集上執行。當配置高可用後,Flink就不存在單點故障。Flink已經被證明可以規模化到上千核和TB級的應用狀態,擁有高吞吐量和低延遲,並強力支撐當前世界最高要求的流處理應用。
下面,我們探索由Flink技術支撐的最常用的應用程式並且給出真實的例項。
事件驅動應用程式
資料分析應用程式
資料管道應用程式
事件驅動應用程式
什麼是事件驅動應用程式?
一個事件驅動式的應用程式是一個從一個或多個事件流攝入事件並觸發計算,狀態更新,和外部動作。
事件驅動應用程式是對傳統設計的計算和資料儲存分層分離的革命,在這樣的架構中,應用程式從遠端事務資料庫讀取資料或進行持久化。
相反,事件驅動應用程式基於狀態流處理應用。在這樣的設計中,資料和計算本地協作,資料本地訪問(記憶體和磁碟)。通過週期寫檢查點到遠端持久化儲存已達到容錯。下面的圖片描述了傳統的架構和事件驅動架構的區別。

事件驅動應用程式的優勢在哪裡?
和查詢遠端資料庫不同,事件驅動應用程式訪問其本地的資料因此效能優越,包括吞吐量和延遲。可以非同步和增量的週期性的把檢查點持久化到遠端儲存。因此檢出檢查點的動作對常規的計算影響很小。然而,事件驅動應用程式設計提供更多好處而不僅僅是本地資料訪問。在分層的架構中,多個應用程式共享相同的資料庫是常見的。因此,資料庫中的任何改變,例如資料佈局的改變會導致應用程式更新或服務擴充套件都需要重新協調。而每個事件驅動應用程式只負責自己的資料,資料表示和應用程式的更改需要較少的協調成本。
Flink如何支援事件驅動應用程式?
事件驅動應用程式的限制是由流處理器如何處理時間和狀態決定的,Flink許多優秀的功能都是圍繞這些概念展開的。Flink提供了豐富的狀態體可以管理超大資料量(達到幾TB)並保證"正好一次"一致性。而且,Flink支援事件時間,高度自定義的視窗邏輯,和ProcessFunction提供的精細的時間控制,用以實現高階的業務邏輯。而且,Flink為複雜的事件處理中偵測資料流中的模型提供了庫。
事件驅動應用程式的典型應用有哪些?
欺詐偵測
異常偵測
基於規則的報警
業務處理監控
web應用程式(社交網路)
資料分析應用程式
什麼是資料分析應用程式?
資料分析型的job從原始資料獲取資訊。傳統上,分析工作以批量查詢的分析進行或者基於事件記錄的有界資料集上的應用。為了把最新的資料合併到分析的結果中,不得不增加到已經分析的資料集之上並且重新查詢或者重跑應用,結果寫入儲存系統或生成報告。
在有一個複雜的流處理引擎後,資料分析也可以以實時的方式執行。不同於讀取有限的資料集,流查詢或應用攝入實時事件流,在事件被消費時持續生成和更新結果。結果要麼寫入外部儲存要麼作為內部狀態維護,外部應用可以從外部資料庫讀取最新結果或直接查詢應用的內部狀態。
Apache Flink支援流和批處理分析應用程式,如下所示:
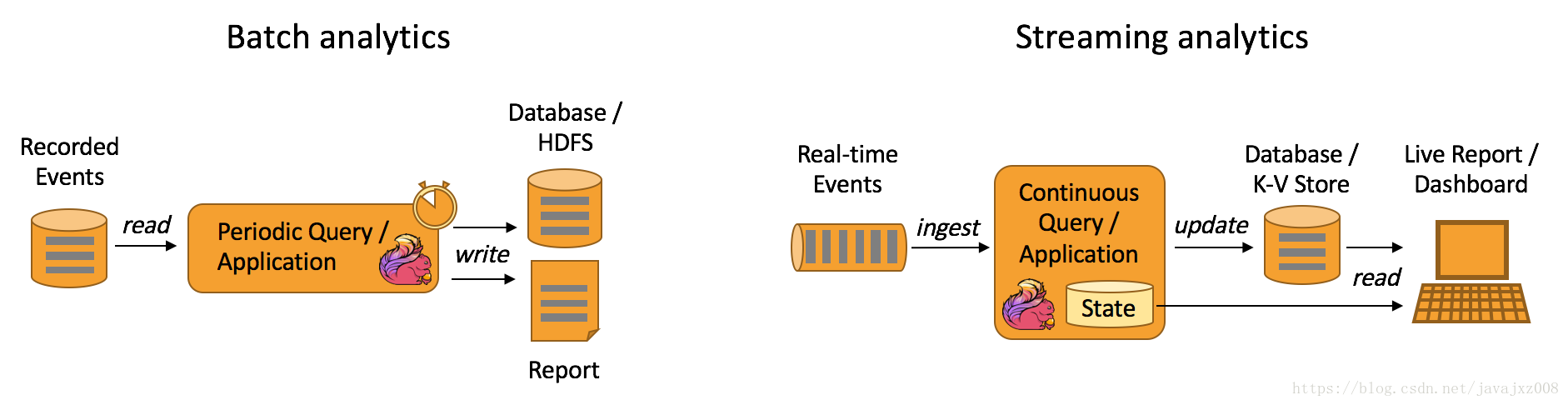
流分析應用程式的優勢在哪裡?
持續流分析和批量分析相比的優勢在於不只是侷限於更低的延遲,還在於流處理不需要週期性的匯入和查詢。和批量查詢相反,流處理不需要處理因週期性匯入和輸入資料的人工邊界。另一個方面是更簡單的應用架構。一個批處理管道由不同的獨立元件構成以週期性的規劃資料攝入和查詢執行。可靠的操作如管道是非常重要的,因為一個元件的失敗影響管道接下來的步驟。相反,流分析應用程式執行在複雜精細的流處理器上如flink從資料攝入到結果持續計算集成了所有步驟。因此,它可以依賴引擎的失敗恢復機制。
Flink如何支援資料分析應用程式?
Flink為批量分析和持續流處理提供了很好的支援。特別地,它提供ANSI相容SQL介面以統一的語義進行批處理和流查詢。SQL查詢計算相同結果,不管它們是執行在靜態資料上還是實時事件流上。對使用者自定義函式的豐富的支援保證自定義的程式碼可以在SQL查詢上執行。如果需要更多的自定義邏輯,Flink的 DataStream API 或DataSet API提供很多低級別的控制。更多地,Flink的 gelly庫提供演算法和為在批量資料集上進行大規模和高效能圖分析構建塊。
資料分析應用程式的典型應用有哪些?
電話網路的質量監控
產品更新分析&手機應用的實驗評估
消費資料實時分析
大規模圖分析
資料管道應用程式
資料管道應用程式
什麼是資料管道應用程式?
提取-轉換-載入(ETL)是在儲存系統之間轉換和移動資料通常的步驟,通常ETL任務週期性觸發以把資料從事務資料庫拷貝到資料分析資料庫或資料倉庫中。資料管道服務和ETL任務目的一樣。對資料轉換和豐富並可以從一個儲存系統轉移到另一個。然而,它是以一種持續的流模式操作而不是週期性觸發。因此能夠持續的
從源頭讀取記錄產生資料並且以低延遲移動到目的地。例如,一個數據管道應用程式可以監控一個檔案系統目錄,一有新檔案就把資料寫入到事件日誌。另一個例子是應用程式可能會將事件流變成資料庫,或者增量地構建和優化搜尋索引。
下圖描述了週期性ETL作業和連續資料管道之間的區別。
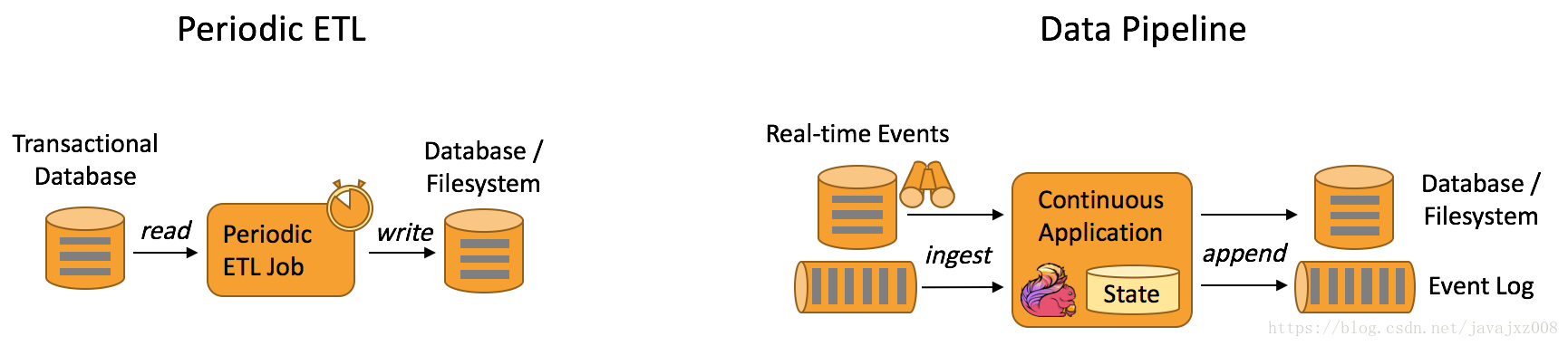
資料管道的優質在哪裡?
連續的資料管道在週期性ETL作業上的明顯優勢是將資料移動到其目的地的延遲。此外,資料管道更加通用,可以用於更多的用例,因為它們能夠持續地消耗和釋放資料。
Flink如何支援資料管道?
Flink的SQL介面(或表API)及其對使用者定義函式的支援可以解決許多常見的資料轉換或充實任務。使用更通用的DataStream API可以實現具有更高階需求的資料管道。Flink為各種儲存系統(如Kafka、Kinesis、Elasticsearch和JDBC資料庫系統)提供了豐富的聯結器。它還為檔案系統提供了連續的原始碼,這些檔案系統可以監視目錄和接收器,並以一種充滿時間的方式編寫檔案。
資料管道有哪些典型應用?
電商中的實時搜尋索引構建
電商中的持續ETL