
Apache Flink-資料流之上的有狀態的計算
官網給出的Flink應用場景圖:
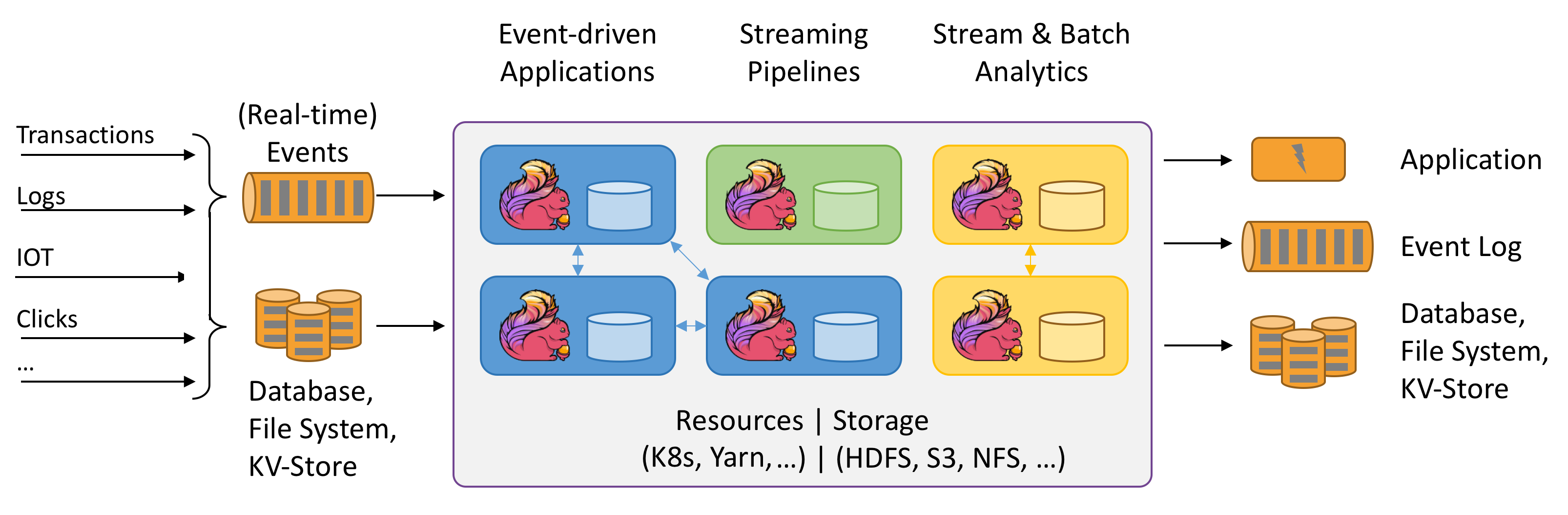
1.狀態計算。
2.從上圖看出的應用場景有?
-----事件驅動式的流處理
-----ETL管道
-----資料分析
3.一般性架構

從架構上來說與一般的流式架構沒有太大的不同,任務排程和資源管理可以放在我們熟悉的yarn上進行,flink的特點如下:
所有流式應用場景:事件驅動應用程式,流和批處理分析,資料管道和ETL
正確性保證:"正好一次"狀態的一致性,事件-時間處理,複雜的延遲資料處理
多層級的API支援:流式和批處理上的SQL,資料流API和資料集API,處理函式(時間和狀態)
操作重點:靈活部署,高可用性設定,儲存點
擴充套件到任何使用者場景:橫向擴充套件的架構,支援超大狀態的計算,增量的檢查點
優秀的效能:低延遲,高吞吐量,記憶體計算
相關推薦
Apache Flink-資料流之上的有狀態的計算
官網給出的Flink應用場景圖: 1.狀態計算。 2.從上圖看出的應用場景有? -----事件驅動式的流處理 -----ETL管道 -----資料分析 3.一般性架構 從架構上來說與一般的流式架構沒有太大的不同,任務排程和資源管理可以放在我們熟悉的yarn上進
(三):Flink資料流程式設計模型
前言 仍然是學概念,以下大部分是對官方doc的翻譯,但是也會有些個人的理解(主要是對比Spark),以及查詢的一些解決自己的一些疑惑相關資料。 從Flink 的資料流程式設計模型和分散式執行環境的基本概念開始學習會對您瞭解其他部分的文件有幫助,包括安裝以及程式設
Apache Flink:流處理中Window的概念
Apache Flink–DataStream–Window 什麼是Window?有哪些用途? 下面我們結合一個現實的例子來說明。 我們先提出一個問題:統計經過某紅綠燈的汽車數量之和? 假設在一個紅綠燈處,我們每隔15秒統計一次通過此紅綠燈的汽車數量,如下圖: 可
使用iptables CONNMARK target和conntrack 模組記錄資料流的轉發狀態
1、每個資料流在linux 核心中由一個struct sk_buff結構來表示,這個sk_buff結構有一個32位無符號整型的mark成員,用來儲存該skb的mark標記值,在netfilter框架中可以動態修改該mark值。 2、每條在linux核心中成功轉發的資料流都會
即將發版!Apache Flink 1.9 版本有哪些新特性?
2019阿里雲峰會·上海開發者大會於7月24日盛大開幕,本次峰會與未來世界的開發者們分享開源大資料、IT基礎設施雲化、資料庫、雲原
雲星資料---Apache Flink實戰系列(精品版)】:Flink流處理API詳解與程式設計實戰002-Flink基於流的wordcount示例002
三、基於socket的wordcount 1.傳送資料 1.傳送資料命令 nc -lk 9999 2.傳送資料內容 good good study day day
【雲星資料---Apache Flink實戰系列(精品版)】:Apache Flink實戰基礎002--flink特性:流處理特性介紹
第二部分:flink的特性 一、流處理特性 1.高吞吐,低延時 有圖有真相,有比較有差距。且看下圖: 1.flink的吞吐量大 2.flink的延時低 3.flink的配置少
從 Spark Streaming 到 Apache Flink : 實時資料流在愛奇藝的演進
作者:陳越晨 整理:劉河 本文將為大家介紹Apache Flink在愛奇藝的生產與實踐過程。你可以藉此瞭解到愛奇藝引入A
超越Storm,SparkStreaming——Flink如何實現有狀態的計算
流式計算分為無狀態和有狀態兩種情況。無狀態計算觀察每個獨立的事件,Storm就是無狀態的計算框架,每一條訊息來了以後和前後都沒有
Apache Flink 如何正確處理實時計算場景中的亂序資料
## 一、流式計算的未來 在谷歌發表了 GFS、BigTable、Google MapReduce 三篇論文後,大資料技術真正有了第一次飛躍,Hadoop 生態系統逐漸發展起來。 Hadoop 在處理大批量資料時表現非常好,主要有以下特點: 1、計算開始之前,資料必須提前準備好,然後才可以開始計算; 2
flink 有狀態udf 引起血案一
場景 近期在做一個畫像的任務,sql實現的,當中有一個udf,會做非常多事情,包含將從redis讀出歷史值加權,並將中間結果和加權後的結果更新到redis。 大家都知道,flink 是能夠支援事件處理的。也就是能夠沒有時間的概念,那麼在聚合,jo
[Flink基礎]--Apache Flink中的廣播狀態實用指南
感謝英文原文作者:https://data-artisans.com/blog/a-practical-guide-to-broadcast-state-in-apache-flink Apache Flink中的廣播狀態實用指南 從版本1.5.0開始,Apache FlinkⓇ具
雙11之後首秀:阿里雲實時計算究竟對Apache Flink做了哪些‘改造’?
關於實時計算 實時計算LOGO 實時計算(Alibaba Cloud Realtime Compute,原阿里雲流計算)是一套基於Apache Flink™️構建的一站式、高效能實時大資料處理平臺,廣泛適用於流式資料處理、離線資料處理、DataLake計算等多種場景。實時計算主要應用於實時網際網路資料
Flink說明文件介紹---資料流程式設計模型
文章內容是通過相應的連結地址翻譯過來的 抽象等級 程式和資料流 並行資料流 視窗 時間 有狀態的操作 針對檢查點的容錯 批處理流 下一步 Flink提供不同級別的抽象來開發流/批處理應用程式。 接下來我們針對上面的每一個部分進行分析。 1、抽象等
面向物件開發方法與面向資料流的結構化開發方法有什麼不同?
(1)結構化開發方法是使用最廣泛、歷史最長的過程化開發方法。結構化開發方法產生過程的抽象,這些抽象把軟體視為 處理流,定義構成一系列步驟的演算法,每一步驟都是帶有預定義輸入和特定輸出的一個過程,把這些步驟串聯在一起可產生合理 的穩定的貫通於整個程式的控制流。這將最終導致一個很簡單的具有靜
Apache Flink流處理(一)
Apache Flink是一個分散式流處理器,它使用直接且富有表現力的API來實現有狀態的流處理應用程式。它以容錯的方式高效地大規模執行此類應用程式。Flink於2014年4月加入Apache軟體基金會作為孵化專案,並於2015年1月成為頂級專案。從一開始,Flink就有一個非常活躍且不斷增
高階語言內的單指令多資料流計算(SIMD)
tag:單指令多資料流計算,SIMD 摘要: 很多年來,x86體系的CPU增加的新指令集大多都是SIMD指令(和相應的暫存器); 然而很容易忽視的是,我們在高階語言內也能進行很多SIMD類計算! 正文: &n
Apache Flink流處理(二)
到目前為止,您已經瞭解了流處理如何解決傳統批處理的侷限性,以及它如何支援新的應用程式和體系結構。您已經熟悉了開源的流處理空間的演變,並對Flink流應用程式有了簡單的瞭解。在這一章,你將進入流世界中,並得到本書本書剩下部分所必要的基礎知識。 這一章仍然與Flink無關。它的目標是介紹流處
Apache Flink 各類關鍵資料格式讀取/SQL支援
目前事件歸併分為兩種,一種為實時的歸併,即基於Kafka內的資料進行歸併和事件生成;一種是週期性的歸併,即基於Hive中的資料進行資料的歸併和事件生成。 基於SQL歸併時Spark Streaming支援的輸入/輸出資料如下: 資料型別 Fl
Flink 原理與實現:資料流上的型別和操作
轉載來源:http://wuchong.me/blog/2016/05/20/flink-internals-streams-and-operations-on-streams/ Flink 為流處理和批處理分別提供了 DataStream API 和 DataSet API。正是這種高層的抽象