Apache Flink-什麼是Apache Flink?
Apache Flink是一個用於在有界和無界資料之上進行狀態計算的分散式處理引擎和框架。其被設計出可以執行在所有常見的叢集環境中,在任何規模之上進行記憶體計算。
下面,讓我瞭解一下Flink架構的一些重要特性。
處理有界和無界資料
任何型別資料的都可以看成像事件流一樣產生,信用卡交易資料,感測器測量資料,機器日誌以及網站上使用者互動資料和手機應用資料,所有這些資料都可以當成流一樣產生。
資料可以被當成有界流和無界流處理。
1.無界的流,有一個開始但是沒有定義結束,一旦生成資料就不會終止。無界流必須要持續處理,也就是事件被攝取後必須立即處理。不可能等到所有的資料到達再處理因為輸入沒有邊界而且在任何時間內都不可能全部到達。處理無邊界資料通常情況下需要事件以指定的順序攝入,例如,以事件發生時作為順序,使得能夠保證結果的完整性。
2.有邊界的流,有一個確定的開始和結束,在進行任何計算前,邊界流資料可以對攝入的所有資料進行處理。處理邊界流資料不必保證攝入資料的有序性因為邊界流資料可以被儲存。對邊界流資料的處理通常也稱之為批處理。
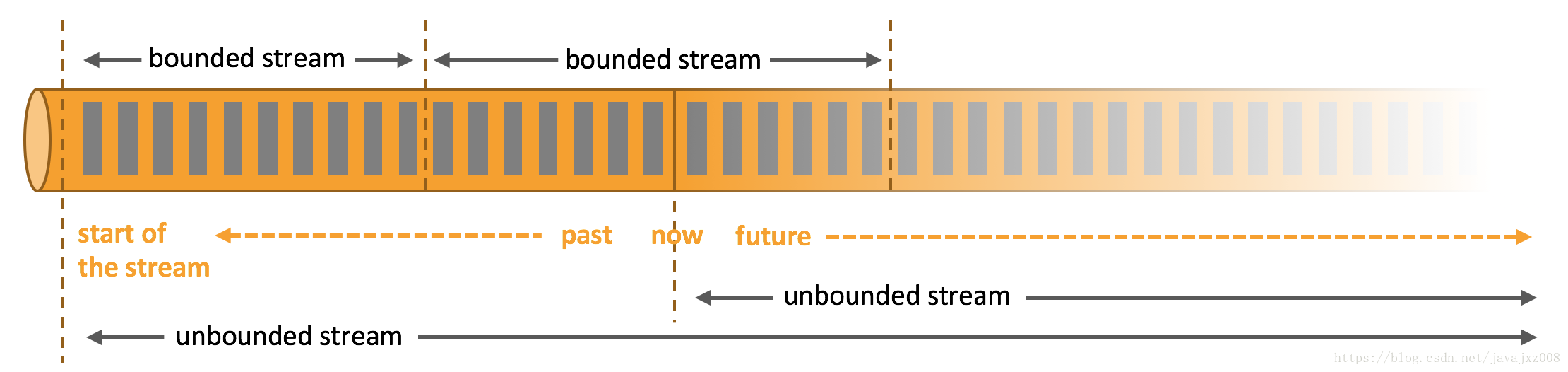
Apache Flink擅長處理邊界和無邊界資料集。 對時間和狀態的精確空控制使得Flink可以執行無邊界流上的各種應用程式,邊界流內部被設計成為固定大小的資料集通過演算法和資料結構處理,表現處了極佳的效能。
為方便自己使用可以瀏覽已經構建在Flink上的使用者案例。
隨處部署應用
Apache Flink是一個分散式系統,它需要計算資源以執行應用程式,Flink可以和所有通用的叢集資源管理器如
Flink被設計成在之前列出的資源管理器上工作的很好,這得益於"資源管理器指定"的部署模式,它允許Flink和每個資源管理器以其習慣的方式進行互動。
當部署一個Flink應用程式,Flink可以根據應用配置的並行度自動識別出所需要的資源並從resource manger請求資源,為了防止失敗,Flink通過請求新的資源來替換失敗的container,對應用程式的提交及控制的所有資訊互動都是通過REST呼叫完成,使得Flink可以簡便和各種環境整合。
任意規模執行應用程式
Flink被設計成在任何規模上執行有狀態的流式應用程式,應用程式可以有上千個並行任務,他們被分佈在叢集中併發執行。因此,一個應用程式可以使用無限制的CPU,主存,磁碟和網路IO。此外,Flink易於維護超大應用狀態。其非同步和增量檢查點演算法保證處理低延遲時的最小影響也保證"正好一次"狀態的一致性。
使用者報告了令人印象深刻的數字基於他們的生產環境執行的Flink應用程式,例如:
- 應用每天處理數萬億的事件,
- 應用維護數以TB的狀態
- 應用執行在上千個核之上
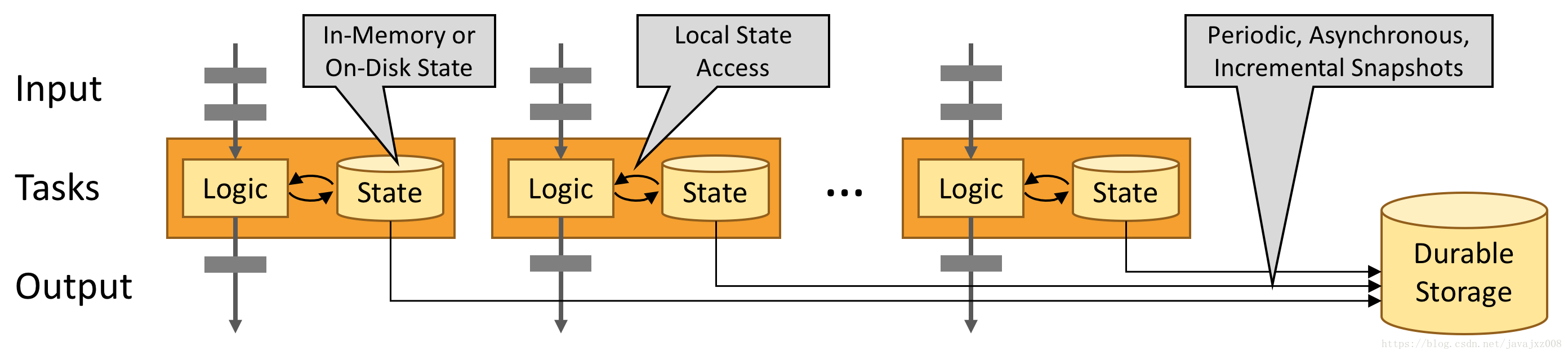
發揮記憶體優勢
狀態化的Flink應用程式被優化成本地狀態訪問。任務狀態總是維護在記憶體中或者狀態大小超出了可用的記憶體,在有效的訪問的磁碟資料結構中。因此,任務通過訪問本地資料執行所有的計算,通常在記憶體中,表現出非常低的處理延遲。Flink保證"正好一次"狀態一致性通過週期性非同步的檢出本地狀態到持久化儲存以防止失敗。