
搜尋引擎之正排與倒排索引
阿新 • • 發佈:2018-11-07
正排索引(正向索引)
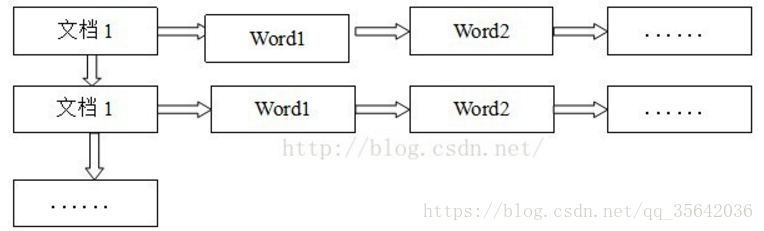
正排表是以文件的ID為關鍵字,表中記錄文件中每個字的位置資訊,查詢時掃描表中每個文件中字的資訊直到找出所有包含查詢關鍵字的文件。
正排表結構如圖1所示,這種組織方法在建立索引的時候結構比較簡單,建立比較方便且易於維護;因為索引是基於文件建立的,若是有新的文件加入,直接為該文件建立一個新的索引塊,掛接在原來索引檔案的後面。若是有文件刪除,則直接找到該文件號文件對應的索引資訊,將其直接刪除。但是在查詢的時候需對所有的文件進行掃描以確保沒有遺漏,這樣就使得檢索時間大大延長,檢索效率低下。
儘管正排表的工作原理非常的簡單,但是由於其檢索效率太低,除非在特定情況下,否則實用性價值不大。
倒排索引(反向索引)
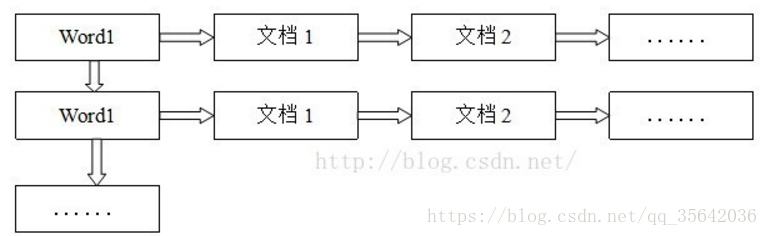
倒排表以字或詞為關鍵字進行索引,表中關鍵字所對應的記錄表項記錄了出現這個字或詞的所有文件,一個表項就是一個字表段,它記錄該文件的ID和字元在該文件中出現的位置情況。
由於每個字或詞對應的文件數量在動態變化,所以倒排表的建立和維護都較為複雜,但是在查詢的時候由於可以一次得到查詢關鍵字所對應的所有文件,所以效率高於正排表。在全文檢索中,檢索的快速響應是一個最為關鍵的效能,而索引建立由於在後臺進行,儘管效率相對低一些,但不會影響整個搜尋引擎的效率。
倒排表的結構圖如圖:
其中詞典結構尤為重要,有很多種詞典結構,各有各的優缺點,最簡單如排序陣列,通過二分查詢來檢索資料,更快的有雜湊表,磁碟查詢有B樹、B+樹,但一個能支援TB級資料的倒排索引結構需要在時間和空間上有個平衡,下圖列了一些常見詞典的優缺點:

其中可用的有:B+樹、跳躍表、FST
正排索引是從文件到關鍵字的對映(已知文件求關鍵字),倒排索引是從關鍵字到文件的對映(已知關鍵字求文件)。
參考連結: