
elasticsearch篇之正/倒排索引與分詞
正/倒排索引
類似於書的目錄,目錄能夠方便的定位哪一章節或哪一小節的頁碼,但是無法定位某一關鍵字的位置。有一些書的最後有索引頁,它的功能就是幫助定位某些關鍵字出現的位置。
目錄頁對應正排索引
索引頁對應倒排索引
正排索引和倒排索引
對於搜尋引擎來講:
正排索引是文件 Id 到文件內容、單詞的關聯關係。也就是說可以通過 Id獲取到文件的內容。
倒排索引是單詞到文件 Id 的關聯關係。也就是說了一通過單詞搜尋到文件 Id。
倒排索引的查詢流程是:首先根據關鍵字搜尋到對應的文件 Id,然後根據正排索引查詢文件 Id 的完整內容,最後返回給使用者想要的結果。
倒排索引的組成
倒排索引是搜尋引擎的核心,主要包含兩個部分:
- 單詞詞典(Trem Dictionary):記錄的是所有的文件分詞後的結果
- 倒排列表(Posting List):記錄了單詞對應文件的集合,由倒排索引項(Posting)組成。
單詞字典的實現一般採用B+Tree的方式,來保證高效
倒排索引項(Posting)主要包含如下的資訊:
1、文件ID,用於獲取原始文件的資訊
2、單詞頻率(TF,Term Frequency),記錄該單詞在該文件中出現的次數,用於後續相關性算分。
3、位置(Position),記錄單詞在文件中的分詞位置(多個),用於做詞語搜尋。
4、偏移(Offset),記錄單詞在文件的開始和結束位置,用於高亮顯示。
es儲存的是一個json的內容,其中包含很多欄位,每個欄位都會有自己的倒排索引。
分詞
分詞和分詞器
分詞是指將文字轉換成一系列的單詞的過程,也可以叫做文字分析,在es中稱為Analysis。
例如文字“elasticsearch是最流行的搜尋引擎”,經過分詞後變成“elasticsearch”,“流行”,“搜尋引擎”
分詞器(Analyzer)是es中專門用於分詞的元件,它的組成如下:
| 組成 | 功能 |
|---|---|
| Character Filter | 針對原始文字進行處理,比如去除html標記符。 |
| Tokenuzer | 將原始文字按照一定規則切分為單詞。 |
| Token Filters | 針對tokenizer處理的單詞進行再加工,比如轉為小寫、刪除或新增等。 |
分詞器組成的呼叫是有順序的:
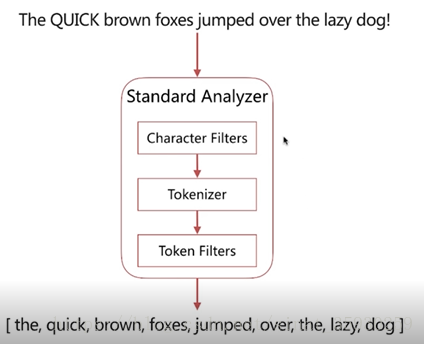
Analyze API
es提供了一個測試分詞的api介面,方便驗證分詞效果,endpoint是_analyze
這個api具有以下特點:
- 可以直接指定analyzer進行測試
- 可以直接指定索引中的欄位進行測試
- 可以自定義分詞器進行測試
直接指定analyzer進行測試
請求舉例:
POST _analyze
{
"analyzer": "standard",
"text": "hello world"
}analyzer表示指定的分詞器,這裡使用es自帶的分詞器standard,text用來指定待分詞的文字
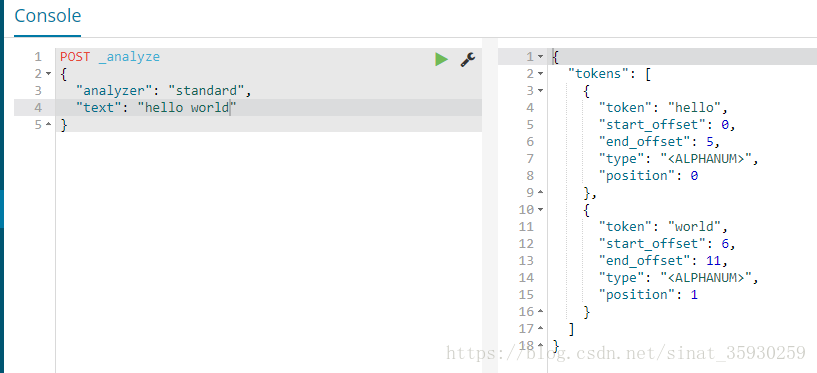
從結果中可以看到,分詞器將文字分成了hello 和 world兩個單詞
指定索引中的欄位進行測試
應用場景:當建立好索引後發現某一欄位的查詢和預期不一樣,就可以對這個欄位進行分詞測試。
請求舉例:
POST text_index/_analyze
{
"field": "username",
"text": "hello world"
}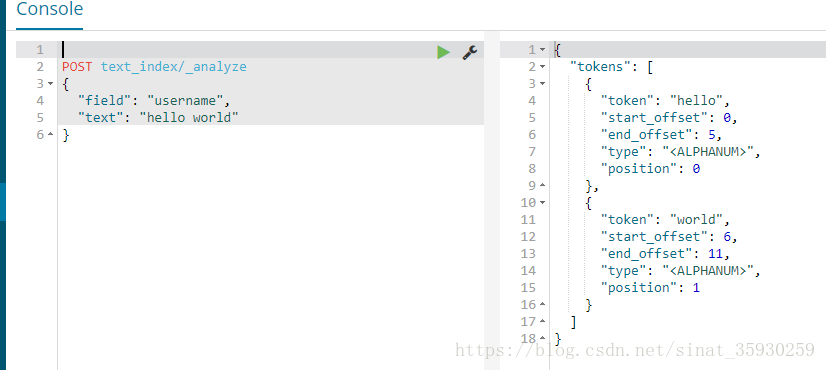
當沒有指定分詞器的時候預設使用standard
自定義分詞器進行測試
請求舉例l:
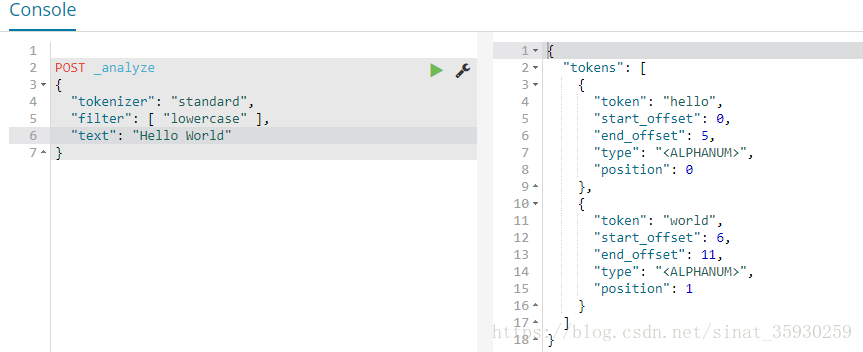
POST _analyze
{
"tokenizer": "standard",
"filter": [ "lowercase" ],
"text": "Hello World"
}根據分詞的流程,首先通過tokenizer指定的分詞方法standard進行分詞,然後會經過filter將大寫轉化為小寫。
預定義的分詞器
es自帶有以下的預定義分詞器,可以直接使用:
standard
預設分詞器,具有按詞切分、支援多語言、小寫處理的特點。
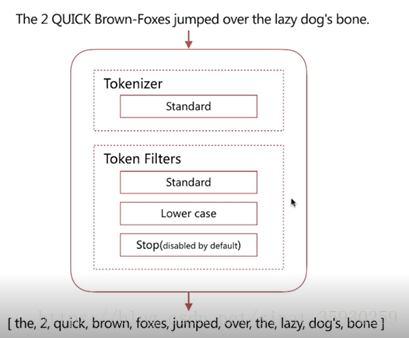
可以看到,standerd將stop word預設關閉了,也就是這些詞還是會在分詞後保留。stop word就是例如and、the、or這種詞,可以通過配置將它開啟。其實搜尋引擎應該將這些stop word過濾掉,這樣可以減少壓力的同時保證搜尋的準確性。
simple
具有特性是:按照非字母切分、小寫處理。
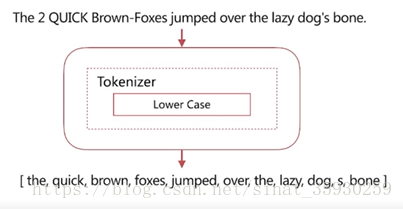
可以看到它將非字母的字元切掉了,例如橫線、標點、數字都被幹掉了。
whitespace
具有的特性是:按照空格切分。
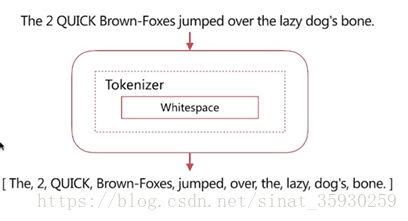
可以看到它按照空格切分,並且沒有進行小寫轉化。
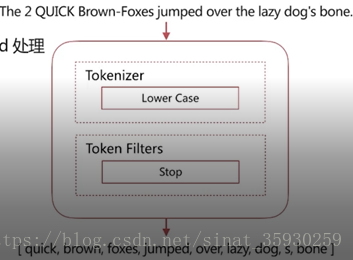
stop
具有的特性是:將stop word切掉
keyword
具有的特性是:不分詞,直接將輸入作為一個單詞輸出
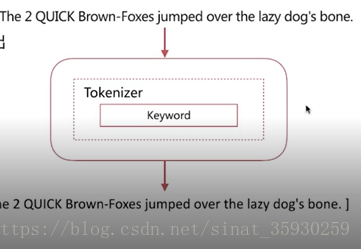
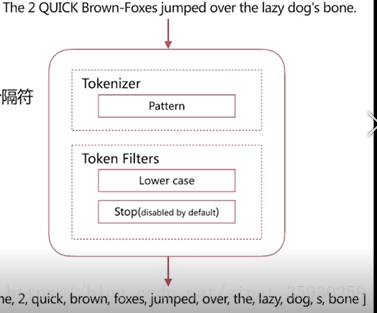
pattern
具有的特性是:通過正則表示式自定義分隔符,預設是\W+,即非字詞的符號作為分隔符,小寫轉化
language
具有的特性是:提供了30+常見語言的分詞器。
中文分詞
中文分詞是指講一個漢字序列切分成一個一個獨立的詞。在英文中,單詞間以空格作為自然分界符,韓語中詞沒有一個形式上的分界符。
而且根據上下文的不同,分析結果迥異。
中文分詞常見的分詞器
IK
可以實現中英文單詞的分詞,支援ik_smart、ik_maxword等模式;可以自定義詞庫,支援熱更新分詞詞典。jieba
python中最流行的分詞系統,支援分詞和詞性標註;支援繁體分詞、自定義詞典、並行分詞。
基於自然語言的分詞系統:
這種分詞系統可以通過建立一個模型,然後該模型經過訓練可以通過根據上下文進行合理的分詞,常見的有:
- Hanlp:有一系列模型預演算法組成的Java工具包,目標是普及自然語言處理在生產環境中的應用
- THULAC:清華大學推出,具有中文分詞和詞性標註的功能。
自定義分詞
當自帶的分詞無法滿足需求的時候,就需要自定義分詞。
自定義分詞就是通過Character Filters、Tokenizer和Token Filter實現。
Character Filters
在Tokenizer之前對原始文字進行處理,比如增加、刪除或替換的字元等。
es自帶的如下:
- html_strip:去除html標籤和轉換html字型
- Mapping:進行字串替換
- Pattern Replace:進行正則匹配替換
由於它是第一步,所以它的結果會影響Tokenizer和Token Filter解析的position和offset的結果
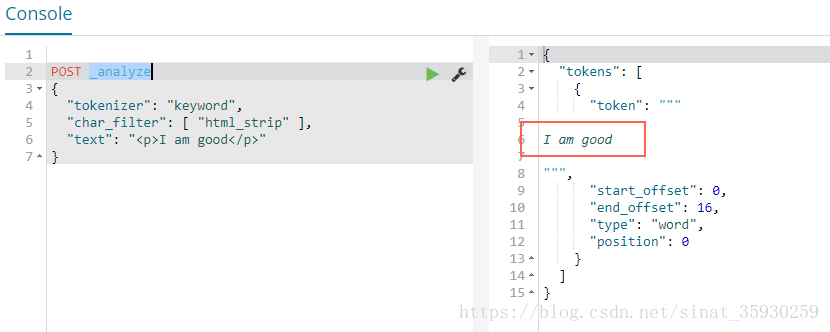
示例:
POST _analyze
{
"tokenizer": "keyword",
"char_filter": [ "html_strip" ],
"text": "<p>I am good</p>"
}這裡為了看出Character Filters的結果所以制定分詞器為keyword,這樣就不會分詞了。
Tokenizer
作用是將原始文字按照一定的規則切分稱為單詞。
es自帶的Tokenizer如下:
- standard:按照單詞切割
- letter:按照非字元切割
- whitespace:按照空格切割
- UAX URL Eamil 按照standard切割,但不會分割郵箱和url
- NGram和Edge NGram:連詞分割(例如搜尋時根據輸入提示相關內容)
- path_hierarchy:按照檔案路徑進行分割
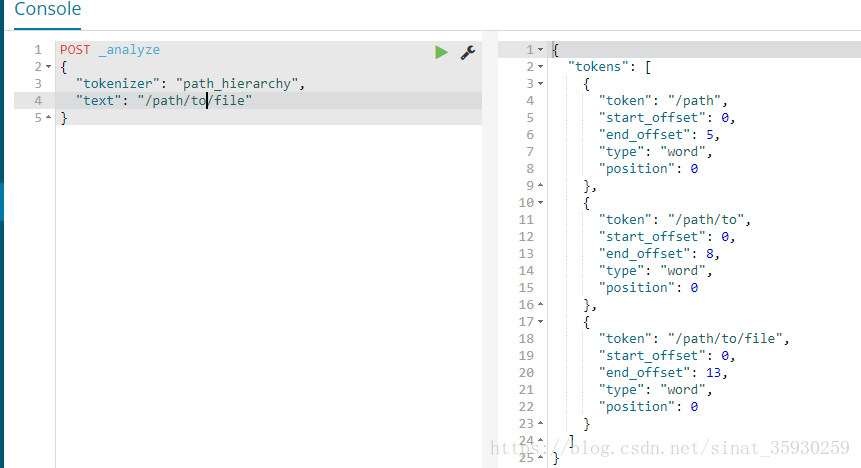
示例:
1、按照路徑分割
POST _analyze
{
"tokenizer": "path_hierarchy",
"text": "/path/to/file"
}
Token Filter
Token Filter 作用是對於 Tokenizer 輸出的單詞(term)進行增加、刪除、修改等操作
es自帶的 Token Filter 如下:
- lowercase:將所有term轉化為小寫
- stop:刪除stop word
- NGram和Edge NGram:連詞分割
- Synonym:新增近義詞的term
filter可以有多個並按照指定的順序執行
示例:
POST _analyze
{
"text": "a Hello World",
"tokenizer": "standard",
"filter": [
"stop",
"lowercase",
{
"type": "ngram",
"min_gram": 4,
"max_gram": 4
}
]
}這裡使用了 standard 的 tokenizer 對文字進行分割,然後 filter 指定使用 stop,lowercase,ngram。這裡是指定每4位切割一次。min_gram 和 max_gram分別指定最小和最大的切割位數。
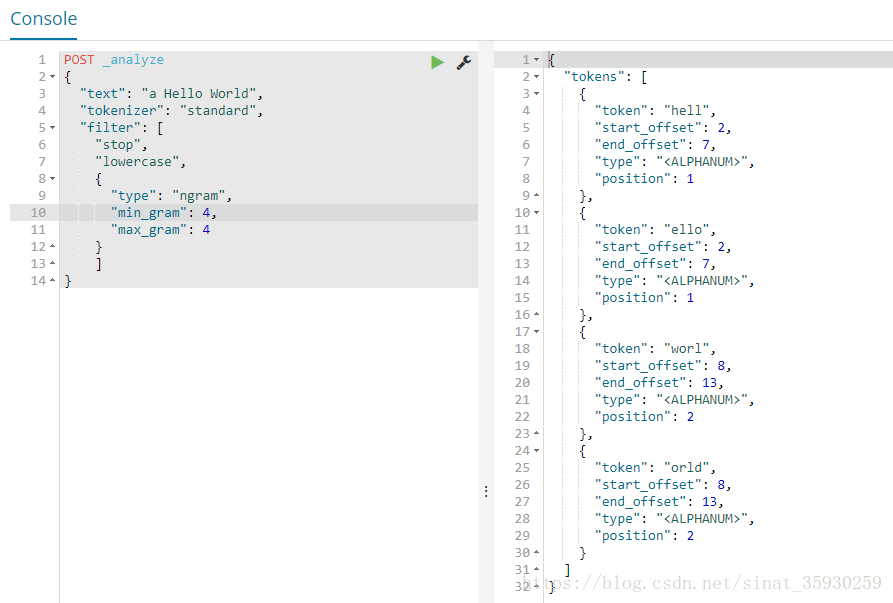
這個作用是:比如當我輸入hell的時候九合一將hello整個單詞給出,當然還可以切分的更小。
自定義分詞的API
自定義分詞需要在索引的配置中設定。
假設現在自定義一個分詞器,character filter使用html strip,tokenizer使用standard,token filter使用lowarcase和ascii folding,那麼它的定義如下:
PUT test_index
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer":{
"type": "custom",
"tokenizer": "standard",
"char_filter": "html_strip",
"filter": [
"lowercase",
"asciifolding"
]
}
}
}
}
}測試自定義分詞器的效果:
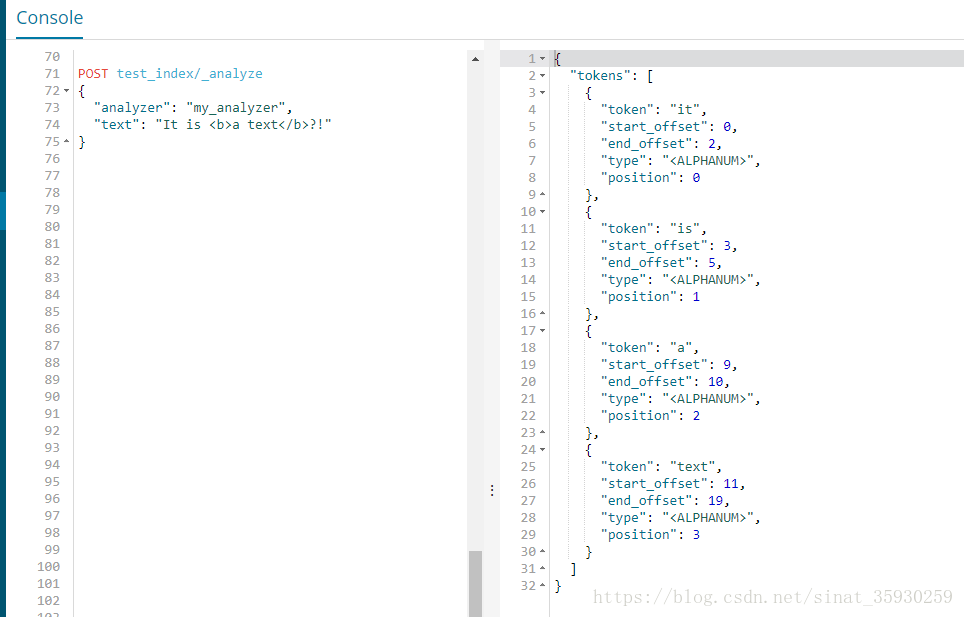
POST test_index/_analyze
{
"analyzer": "my_analyzer",
"text": "It is <b>a text</b>?!"
}
下面是一個比較負載的自定義分詞器:
character filter使用自定義的mapping:custom mapping, tokenizer使用custom pattern,token filter使用lowercase和custom stop。
PUT test_index2
{
"settings": {
"analysis": {
"analyzer": {
"my_az": {
"type": "custom",
"char_filter": "emoticons",
"tokenizer": "punctuation",
"filter": [
"lowercase",
"english_stop"
]
}
},
"tokenizer": {
"punctuation": {
"type": "pattern",
"pattern": "[.,!?]"
}
},
"char_filter": {
"emoticons": {
"type": "mapping",
"mappings": [
":) => _happy_",
":( => _sad_"
]
}
},
"filter": {
"english_stop": {
"type": "stop",
"stopwords": "_english_"
}
}
}
}
}測試自定義分詞器:
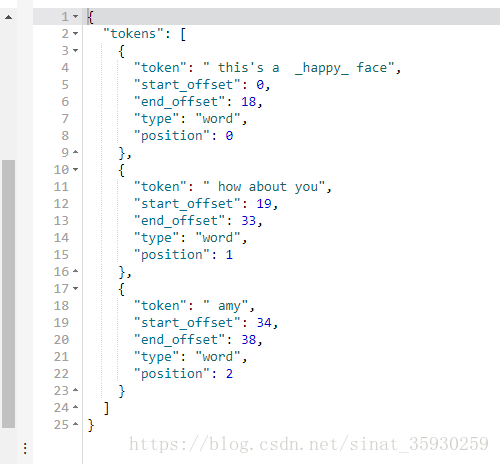
POST test_index2/_analyze
{
"analyzer": "my_az",
"text": " This's a :) face, how about you? Amy"
}
這樣就達到了自定義分詞效果的目的。
分詞使用說明
分詞一般會在以下的情況下使用:
- 建立或更新文件的時候,會對相應的文件進行分詞處理。
- 查詢時,會對查詢語句進行分詞
明確欄位是否需要分詞,不需要分詞的欄位就將 type 設定為 keyword,可以節省空間和提高寫效能。
善用 _analyze API 檢視文件具體分詞結果