
spark複習筆記(2)
之前工作的時候經常用,隔了段時間,現在學校要用學的東西也忘了,翻翻書謝謝部落格吧。
1.什麼是spark?
Spark是一種快速、通用、可擴充套件的大資料分析引擎,2009年誕生於加州大學伯克利分校AMPLab,2010年開源,2013年6月成為Apache孵化專案,2014年2月成為Apache頂級專案。目前,Spark生態系統已經發展成為一個包含多個子專案的集合,其中包含SparkSQL、Spark Streaming、GraphX、MLlib等子專案,Spark是基於記憶體計算的大資料平行計算框架。Spark基於記憶體計算,提高了在大資料環境下資料處理的實時性,同時保證了高容錯性和高可伸縮性,允許使用者將
2為什麼要學Spark
Spark是一個開源的類似於Hadoop MapReduce的通用的平行計算框架,Spark基於map reduce演算法實現的分散式計算,擁有
Spark是MapReduce的替代方案,而且相容HDFS、Hive,可融入Hadoop的生態系統,以彌補MapReduce的不足。
3 Spark特點
1) 快
與Hadoop的MapReduce相比,Spark基於記憶體的運算要快100倍以上,基於硬碟的運算也要快10倍以上。Spark實現了高效的DAG執行引擎,可以通過基於記憶體來高效處理資料流。

2)易用
Spark支援Java、Python和Scala的API,還支援超過80種高階演算法,使使用者可以快速構建不同的應用。而且Spark支援互動式的Python和Scala的shell,可以非常方便地在這些shell中使用Spark叢集來驗證解決問題的方法。

3)通用
Spark提供了統一的解決方案。Spark可以用於批處理、互動式查詢(Spark SQL)、實時流處理(Spark Streaming)、機器學習(Spark MLlib)和圖計算(GraphX)。這些不同型別的處理都可以在同一個應用中無縫使用。Spark統一的解決方案非常具有吸引力,畢竟任何公司都想用統一的平臺去處理遇到的問題,減少開發和維護的人力成本和部署平臺的物力成本。
4)相容性
Spark可以非常方便地與其他的開源產品進行融合。比如,Spark可以使用Hadoop的YARN和Apache Mesos作為它的資源管理和排程器,並且可以處理所有Hadoop支援的資料,包括HDFS、HBase和Cassandra等。這對於已經部署Hadoop叢集的使用者特別重要,因為不需要做任何資料遷移就可以使用Spark的強大處理能力。Spark也可以不依賴於第三方的資源管理和排程器,它實現了Standalone作為其內建的資源管理和排程框架,這樣進一步降低了Spark的使用門檻,使得所有人都可以非常容易地部署和使用Spark。此外,Spark還提供了在EC2上部署Standalone的Spark叢集的工具。

4.spark安裝
1)下載spark安裝包
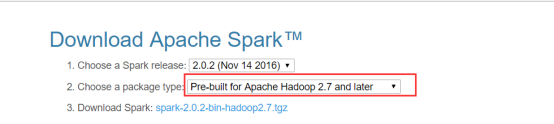
下載地址spark官網:http://spark.apache.org/downloads.html這裡我們使用 spark-2.0.2-bin-hadoop2.7版本.
2)解壓安裝包
tar -zxvf spark-2.0.2-bin-hadoop2.7.tgz -C /soft
3)建立軟連線
ln -s spark-2.0.2-bin-hadoop2.7.tgz spark
4)修改配置檔案
(1)配置檔案目錄在 /opt/bigdata/spark/conf
nano spark-env.sh 修改檔案(先把spark-env.sh.template重新命名為spark-env.sh)
(2)配置spark環境變數
#指定spark老大Master的IP
export SPARK_MASTER_HOST=s201
#指定spark老大Master的埠
export SPARK_MASTER_PORT=7077
5)
(0)sc:SparkContext物件spark程式的入口點,封裝了整個spark執行環境的資訊