
作業四:詞頻統計-基本功能
一、基本資訊
1、本次作業的地址:https://edu.cnblogs.com/campus/ntu/Embedded_Application/homework/2088
2、專案Git地址:https://gitee.com/ntucs/PairProg/tree/SE045_060
3.開發環境:Pycharm2017、Python3.7
4.結對成員:1613072045徐澤輝 、1613072060楊春華
二:專案分析
2.1 程式執行模組(方法、函式)介紹
①任務一:讀取檔案,統計有效行數
def process_file(dst): # 讀檔案到緩衝區,統計文字行數
try: # 開啟
file = open(dst, 'r') # dst為文字的目錄路徑
except IOError as e:
print(e)
return None
try:
lines = len(file.readlines())#統計文字行數
# 關閉檔案,重新開啟
file.close()
file = open(dst, "r")
bvffer = file.read()
except:
print("Read File Error!")
return None
file.close()
return bvffer, lines
②任務一:使用正則表示式統計詞頻,存放如字典,統計單詞總數
def process_buffer(bvffer): # 處理緩衝區,返回存放每個單詞頻率的字典word_freq,單詞總數
if bvffer:
word_freq = {}
# 將文字內容都小寫
bvffer = bvffer.lower()
# 用空格消除文字中標點符號
Char = {",.;!?"}
for ch in Char:
bvffer = bvffer.replace(ch, ' ')
words = bvffer.split(' ')
# 正則匹配至少以4個英文字母開頭,跟上字母數字符號,單詞以分隔符分割,不區分大小寫
regex_word = "^[a-z]{4}(\w)*"
for word in words:
if re.match(regex_word, word):
# 資料字典已經存在該單詞,數量+1
if word in word_freq.keys():
word_freq[word] = word_freq[word] + 1
# 不存在,把單詞存入字典,數量置為1
else:
word_freq[word] = 1
return word_freq, len(words)
③任務一:按照單詞的頻數排序,返回前十的單片語
def output_result(word_freq): # 按照單詞的頻數排序,返回前十的單片語 if word_freq: sorted_word_freq = sorted(word_freq.items(), key=lambda v: v[1], reverse=True) for item in sorted_word_freq[:10]: # 輸出 Top 10 的單詞 print('<' + str(item[0]) + '>:' + str(item[1])) return sorted_word_freq[:10]
④任務一:儲存結果到檔案(result.txt)
def save_result(lines, words, items): # 儲存結果到檔案(result.txt) try: result = open("C:\\Users\\YCH19981203\\result.txt", "w") # 以寫模式開啟,並清空檔案內容 except Exception as e: result = open("C:\\Users\\YCH19981203\\result.txt", "x") # 檔案不存在,建立檔案並開啟 # 寫入檔案result.txt result.write("lines:" + lines + "\n") result.write("words:" + words + "\n") for item in items: item = '<' + str(item[0]) + '>:' + str(item[1]) + '\n' result.write(item) print('寫入result.txt已完成') result.close()
⑤任務一:主函式
def main(): # 命令列傳遞引數 dst='C:\\Users\\YCH19981203\\Gone_with_the_wind.txt' bvffer, lines = process_file(dst) word_freq, words = process_buffer(bvffer) items = output_result(word_freq) # 把lines、words型別強制轉化為str lines = str(lines) words = str(words) save_result(lines, words, items) Phrase_freq2 = process_Phrase2(bvffer) # 生成片語字典 Phrase_freq3 = process_Phrase3(bvffer) # 生成片語字典 output_result(Phrase_freq2) output_result(Phrase_freq3)
⑥任務二:停詞表,這裡沒有用nltk工具庫,建立了一個停詞表檔案,新的 process_buffer(bvffer)如下
def process_buffer(bvffer): # 處理緩衝區,返回存放每個單詞頻率的字典word_freq,單詞總數 if bvffer: word_freq = {} # 將文字內容都小寫 bvffer = bvffer.lower() # 用空格消除文字中標點符號 Char = {",.;!?"} for ch in Char: bvffer = bvffer.replace(ch, ' ') words = bvffer.split(' ') # 正則匹配至少以4個英文字母開頭,跟上字母數字符號,單詞以分隔符分割,不區分大小寫 regex_word = "^[a-z]{4}(\w)*" stopList = open("C:\\Users\\YCH19981203\\stopwords.txt", "r") StopList=stopList.read() for word in words: if word not in StopList: if re.match(regex_word, word): # 資料字典已經存在該單詞,數量+1 if word in word_freq.keys(): word_freq[word] = word_freq[word] + 1 # 不存在,把單詞存入字典,數量為1 else: word_freq[word] = 1 return word_freq, len(words)
⑦任務二:統計兩個單詞片語
def process_Phrase2(bvffer): #統計兩個單詞片語 Phrase = [] Phrase_freq = {} words = bvffer.strip().split()#單詞分割 for y in range(len(words) - 1): if words[y][-1] in '’“‘!;,.?”' or words[y + 1][0] in '’“‘!;,.?”': # 判斷兩個單詞之間是否有其他符號 continue elif words[y][0] in '’“‘!;,.?”': # 判斷第一個單詞前是否有符號 words[y] = words[y][1:] elif words[y + 1][-1] in '’“‘!;,.?”': # 判斷第二個單詞後是否有符號 words[y + 1] = words[y + 1][:len(words[y + 1]) - 1] Phrase.append(words[y] + ' ' + words[y + 1]) # 錄入列表Phrase for ph in Phrase: Phrase_freq[ph] = Phrase_freq.get(ph, 0) + 1 # 生成片語字典 return Phrase_freq
⑧任務二:函式分析模組
if __name__ == "__main__": import cProfile import pstats cProfile.run("main()", filename="result.out") p = pstats.Stats('result.out') # 建立Stats物件 p.sort_stats('calls').print_stats(10) # 按照呼叫次數排序,列印前10函式的資訊 p.strip_dirs().sort_stats("cumulative", "name").print_stats(10) # 按照執行時間和函式名排序,只打印前10行函式的資訊 p.print_callees("process_buffer") # 檢視process_buffer()函式中呼叫了哪些函式
2.2result.txt截圖
沒有停詞表
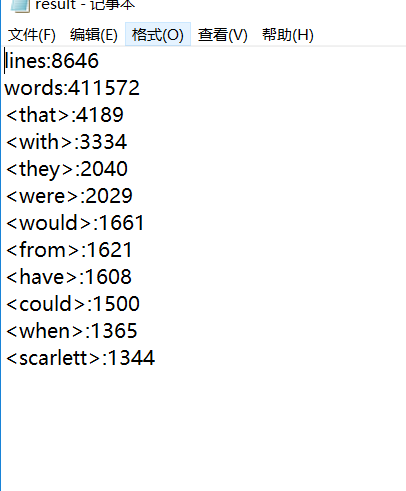
使用停詞表後

2.3片語兩個單詞和三個單詞的排名前十截圖
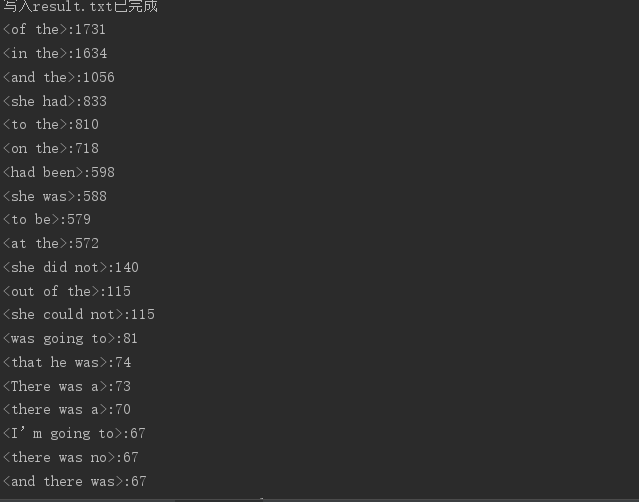
2.3程式演算法的時間、空間複雜度分析
.程式演算法的時間、空間複雜度分析
時間複雜度:本程式process_buffer(bvffer)函式中所有的迴圈都是單層迴圈且每一層迴圈執行的次數都是常量有限次,因此函式迴圈部分的時間複雜度為O(n)。
而python程式中sort函式的時間複雜度為O( n*log2(n) ),因此程式的時間複雜度為O( n*log2(n) )
空間複雜度:sort函式的空間複雜度是O( n*log2(n) ),for迴圈的空間複雜度是O(n),因此程式的空間複雜度是O(n*log2(n)
三、效能分析
執行時間結果圖如下
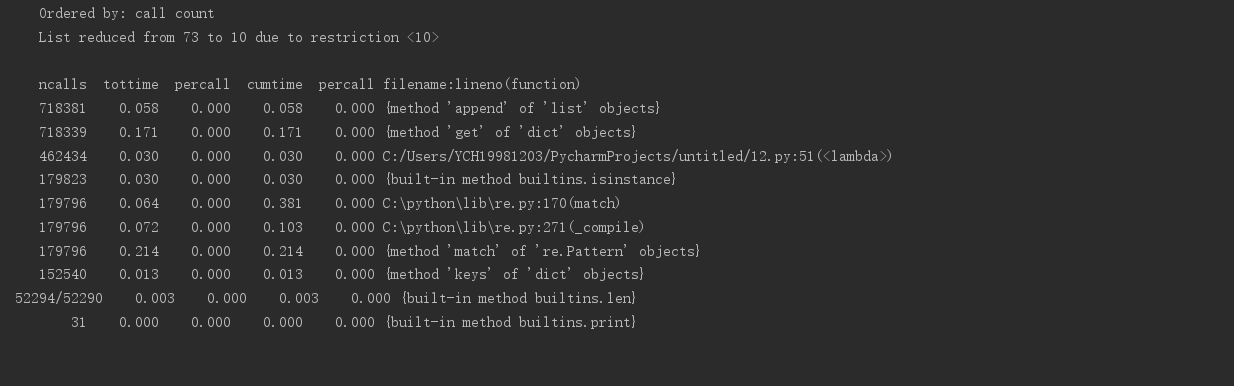
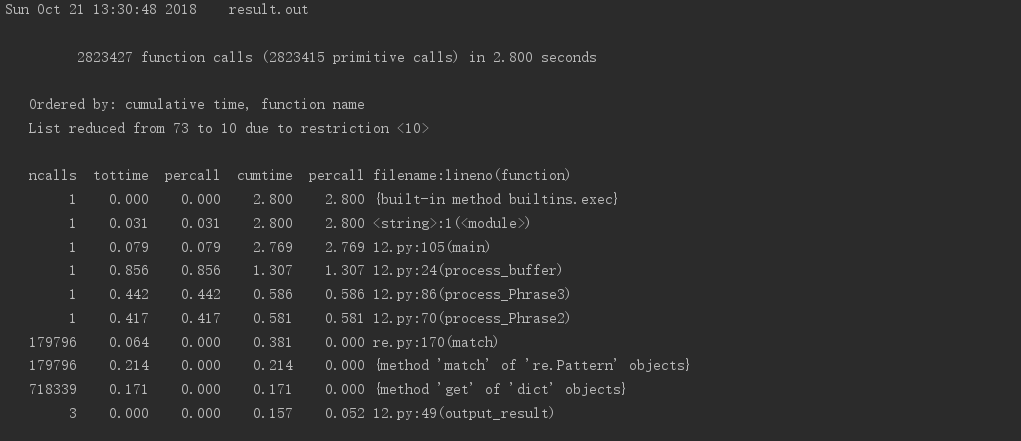
四、其他
4.1 結隊程式設計時間開銷
大概三天左右完成全部功能。主要時間開銷分兩個部分:上網查閱CSDN,部落格、結隊程式設計。大體分工查閱技術文件,交流討論。每個實現功能都經過討論,哪一種更加的方便,節約時間開銷
4.2 結隊程式設計照片

五、事後分析與總結
1、 簡述結對程式設計時,針對某個問題的討論決策過程
停詞表的呼叫,原本想通過呼叫函式來實現,後來為了減少空間的使用,在process_buffer(bvffer)函式裡直接用for語句迴圈檢查了
2、評價
(1)徐澤輝對楊春華的評價:楊春華同學個人能力較強,能夠很快的理清楚程式設計思路,在程式碼編寫與除錯方面也非常熟練,非常樂意解決問題。期待與他下一次的合作。
(2)楊春華對徐澤輝的評價:雖然程式設計能力方面不足,但是積極的查閱資料,是不可或缺的一部分,為專案做出貢獻。
3、關於結對過程的建議
結對程式設計能夠增強我們的合作能力,能夠及時發現一些問題,有時候自己想出來的未必是最好的辦法,集思廣益,同伴的幫助能少走很多彎路。
4 、其它:
希望下次還能有一起合作完成別的語言專案的機會,加強自己的動手能力