
作業詞頻統計——基本功能
一、基本資訊
作業地址:https://edu.cnblogs.com/campus/ntu/Embedded_Application/homework/2088
專案git地址:https://gitee.com/ntucs/PairProg/tree/SE032_033/
結對成員:1613072032 趙亦明
1613072033 王楠楠
二、專案分析
2.1 程式執行模組(方法、函式)介紹
2.2.1 讀取檔案到緩衝區
1 def process_file(dst): #讀檔案到緩衝區 2 try: # 開啟檔案s 3 d = open(dst, "r") 4 except IOError as s: 5 print(s) 6 return None 7 try: # 讀檔案到緩衝區 8 bvffer = d.read() 9 except: 10 print('Read File Error!') 11 return None 12 d.close() 13 return bvffer
2.1.2 統計檔案的有效行數
1 def process_rowCount(bvffer): # 計算文章的行數 2 if bvffer: 3 count = 1 4 for word in bvffer: # 開始計數 5 if word == '\n': 6 count = count + 1 7 print("lines:{:}".format(count)) 8 f = open('result.txt', 'w')9 print("lines:{:}".format(count),file=f) 10 f.close()
2.1.3 統計檔案的單詞總數
1 def process_wordNumber(words): 2 if words: 3 wordNew = [] 4 words_select = '[a-z]{4}(\w)*' 5 for i in range(len(words)): 6 word = re.match(words_select, words[i]) # 如果不匹配,返回NULL型別 7 if word: 8 wordNew.append(word.group()) 9 print("words:{:}".format(len(wordNew))) 10 f = open('result.txt', 'a') 11 print("words:{:}".format(len(wordNew)),file=f) 12 f.close() 13 return wordNew
2.1.4 輸出頻率最高的前10個片語
1 def output_result(word_freq): 2 if word_freq: 3 sorted_word_freq = sorted(word_freq.items(), key=lambda v: v[1], reverse=True) 4 for item in sorted_word_freq[:10]: # 輸出 Top 10 的單詞 5 print("詞:%-5s 頻:%-4d " % (item[0], item[1]))
2.1.5 停用詞模組
1 def process_twoPhrase(words): 2 useless_twoPhrase =['they were','would have','there were','have been','that would'] 3 words_group = [] 4 for i in range(len(words) - 1): 5 str = '%s %s' % (words[i], words[i + 1]) 6 words_group.append(str) 7 word_freq = {} 8 for word in words_group: 9 if word in useless_twoPhrase: 10 continue 11 else: 12 word_freq[word] = word_freq.get(word, 0) + 1 # 將片語進行計數統計 13 return word_freq 14 15 16 def process_threePhrase(words): 17 words_group = [] 18 for i in range(len(words) - 2): 19 str = '%s %s %s' % (words[i], words[i + 1], words[i + 2]) 20 words_group.append(str) 21 word_freq = {} 22 for word in words_group: 23 word_freq[word] = word_freq.get(word, 0) + 1 # 將片語進行計數統計 24 return word_freq
2.1.6 高頻片語模組
1 def output_result(word_freq): 2 if word_freq: 3 sorted_word_freq = sorted(word_freq.items(), key=lambda v: v[1], reverse=True) 4 for item in sorted_word_freq[:10]: # 輸出 Top 10 頻率高的 5 print("<{:}>:{:}".format(item[0], item[1])) 6 f = open('result.txt','a') 7 print("<{:}>:{:}".format(item[0], item[1]), file=f) 8 f.close()
2.1.7 主函式
1 if __name__ == "__main__": 2 # 把分析結果儲存到檔案中 3 cProfile.run("main()", filename="result.wordcount") 4 p = pstats.Stats("result.wordcount") 5 p.strip_dirs().sort_stats("calls").print_stats(10) 6 p.strip_dirs().sort_stats("cumulative", "name").print_stats(10) 7 p.print_callers(0.5, "process_transform") 8 p.print_callers(0.5, "process_rowCount") 9 p.print_callers(0.5, "process_wordNumber") 10 p.print_callers(0.5, "process_stopwordSelect") 11 p.print_callers(0.5, "process_twoPhrase") 12 p.print_callers(0.5, "process_threePhrase") 13 p.print_callers(0.5, "output_result") 14 p.print_callees("process_buffer")
2.2 程式演算法的時間、空間複雜度分析
假設停詞表檔案有N個單詞,待分析的文字單詞集合有n個單詞,根據兩個for迴圈分析,則該模組的時間複雜度大概為O(N*n),又根據作業系統的空間記憶體重複呼叫可知,該模組的時間複雜度經優化後應該小於O(N*n)。
2.3 程式執行案例截圖
2.3.1 task1

2.3.2 task2


三、效能分析
3.1 執行時間
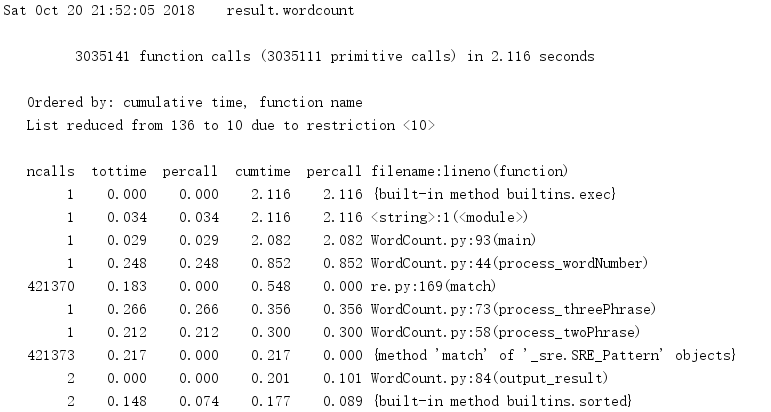
3.2 效能圖表
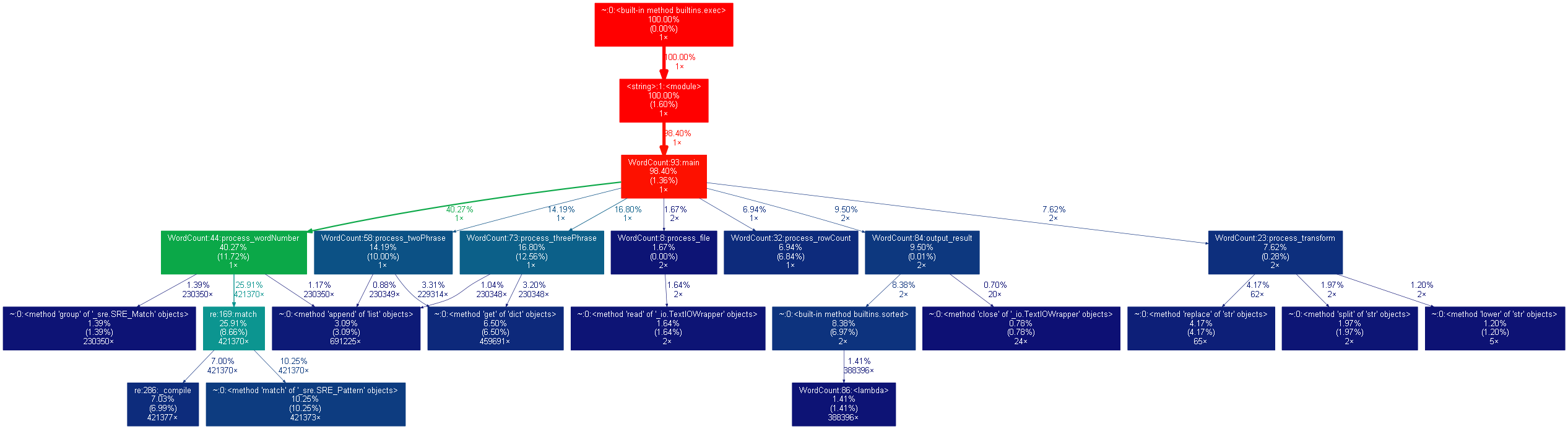
四、其他
4.1 結對程式設計時間開銷
利用課餘時間完成全部內容。團隊成員共同討論,查閱資料,完成程式碼部分的編寫。同時,討論程式碼中不完善的內容。
4.2 結對程式設計照片

五、事後分析與總結
5.1 簡述結對程式設計時,針對某個問題的討論決策過程
- 明確任務和分工。
- 針對需要完成功能,分享各自的想法,同時,進行對比,選取簡單明晰或者效能好一點的方法。
- 完成基本程式碼編寫後,再根據任務要求,檢查執行結果,完善優化程式碼。
5.2 評價對方
王楠楠評價趙亦明:很有想法,動手能力強,認真負責,會主動交流想法。遇到問題時能一起分析並解決,也會認真聽取他人的意見。
趙亦明評價王楠楠:學習能力很強,遇到問題時思路清晰,遇到不懂的會積極主動的查閱資料。
5.3 評價整個過程
整個過程是非常順利和愉快的,過程大概經歷一個星期左右,在確定過基本任務後,編寫程式碼過程中,王楠楠提供想法,然後結合趙亦明的想法,最後由趙亦明編寫程式碼,然後王楠楠最後再閱讀檢查,出現錯誤時,兩個人都會交流想法,不斷嘗試,尋找解決辦法,共同解決問題。平時也會一起交流想法,所以此次結對程式設計更加深了彼此的默契,同時也在結對過程中能夠對比學習到彼此的優缺點,是一次很好的成長。
5.4 其他
結對編碼是一個很好的過程,通過團隊合作完成整個專案,可以避免單人完成時出現的考慮問題的片面性。