
作業4:詞頻統計——基本功能
一、基本資訊
1.本次作業的地址: https://edu.cnblogs.com/campus/ntu/Embedded_Application/homework/2088
2.專案Git的地址:https://gitee.com/ntucs/PairProg/tree/SE016_017
3.開發環境:Pycharm2018、Python3.6
4.結對成員:1613072013 劉賽、1613072011蔣兆豐
二、專案分析
2.1 程式執行模組(方法、函式)介紹
①任務一:讀取檔案、統計行數寫入result.txt方法

import re
import jieba
from string import punctuation
def process_file(dst): # 讀檔案到緩衝區
try: # 開啟檔案
f=open(dst,'r')
except IOError as s:
print (s)
return None
try: # 讀檔案到緩衝區
x=f.read()
except:
print ("Read File Error!")
return None
bvffer=x
return bvffer
②任務一:使用正則表示式統計詞頻,存放如字典模組
def line_count(dst):
count=0
for index,line in enumerate(open(dst,'r')):
count+=1
print("text line :",count)
def process_buffer(bvffer):
c=bvffer.lower()
result=re.sub("[0-9]+[a-z]+"," ",c)
re1=re.findall('[a-z]+\w+',result)
d=open("stopwords.txt",'r').read()
if re1:
word_freq = {}
# 下面新增處理緩衝區 bvffer程式碼,統計每個單詞的頻率,存放在字典word_freq
for word in re1:
if word not in d:
if word not in word_freq:
word_freq[word]=0
word_freq[word]+=1
return word_freq
③任務一:儲存排名前十結果至result.txt模組
def output_result(word_freq):
doc=open('result.txt','w')
if word_freq:
sorted_word_freq = sorted(word_freq.items(), key=lambda v: v[1], reverse=True)
print(len(word_freq))
for item in sorted_word_freq[:10]: # 輸出 Top 10 的單詞
print(item[0],":",item[1])
print(item[0],":",item[1],file=doc)
doc.close()
④任務一:主函式呼叫各個模組邏輯
if __name__ == "__main__":
import argparse
parser = argparse.ArgumentParser()
parser.add_argument('dst')
args = parser.parse_args()
dst = args.dst
line_count(dst)
bvffer = process_file(dst)
word_freq = process_buffer(bvffer)
output_result(word_freq)
word_frequency(bvffer)
⑤任務二:停詞表模組
功能實現方法:使用 nltk(Natural Language Toolkit,自然語言處理工具包,在NLP領域中,最常使用的一個Python庫。)下載英文停詞表,存放到list_stopWords集合中,接著對將要處理的英文單詞進行判斷是否與list_stopWords中的詞彙相等,如果相等則跳過,即停詞功能。
程式碼模組如下:
d=open("stopwords.txt",'r').read() #停詞
if re1:
word_freq = {}
# 下面新增處理緩衝區 bvffer程式碼,統計每個單詞的頻率,存放在字典word_freq
for word in re1:
if word not in d:
if word not in word_freq:
word_freq[word]=0
word_freq[word]+=1
return word_freq
任務二:列出高頻短語模組
def Phrase_statistics(bvffer): #統計高頻片語
text=nltk.text.Text(bvffer.split())
print(text.collocations())
2.2 程式演算法時間、空間複雜度分析
def process_buffer(bvffer):
c=bvffer.lower()
result=re.sub("[0-9]+[a-z]+"," ",c)
re1=re.findall('[a-z]+\w+',result)
d=open("stopwords.txt",'r').read()
if re1:
word_freq = {}
# 下面新增處理緩衝區 bvffer程式碼,統計每個單詞的頻率,存放在字典word_freq
for word in re1:
if word not in d:
if word not in word_freq:
word_freq[word]=0
word_freq[word]+=1
return word_freq
假設字典中有n個元素,執行一次就迴圈一次,共n次,所以時間複雜度為O(n),每次建立一個空間存放將要使用詞,所以空間複雜度為O(1)
2.3 程式執行案例截圖
result執行截圖:


高頻片語截圖:

三、效能分析
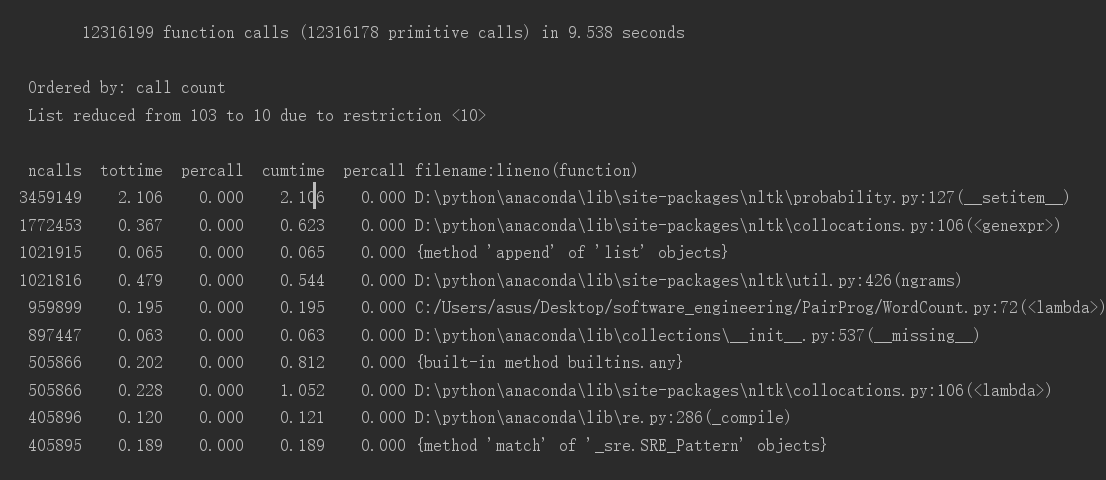
1.

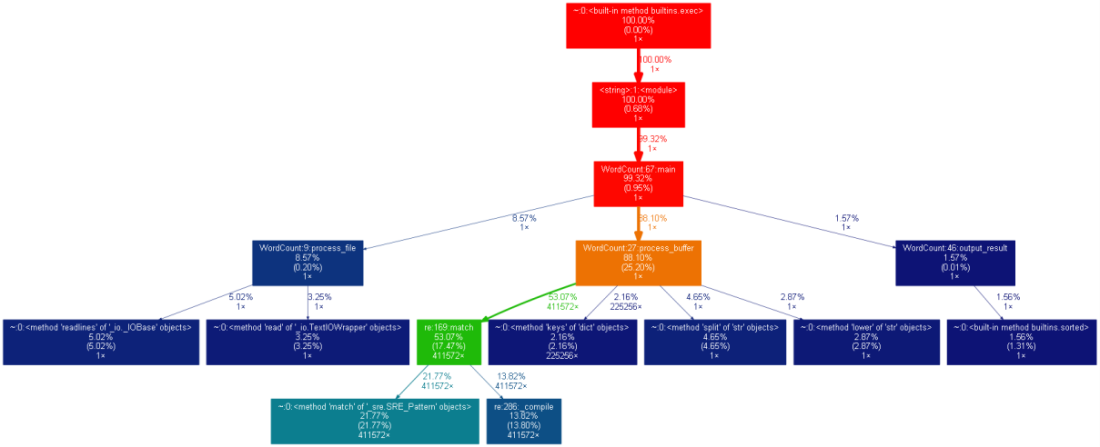
2.
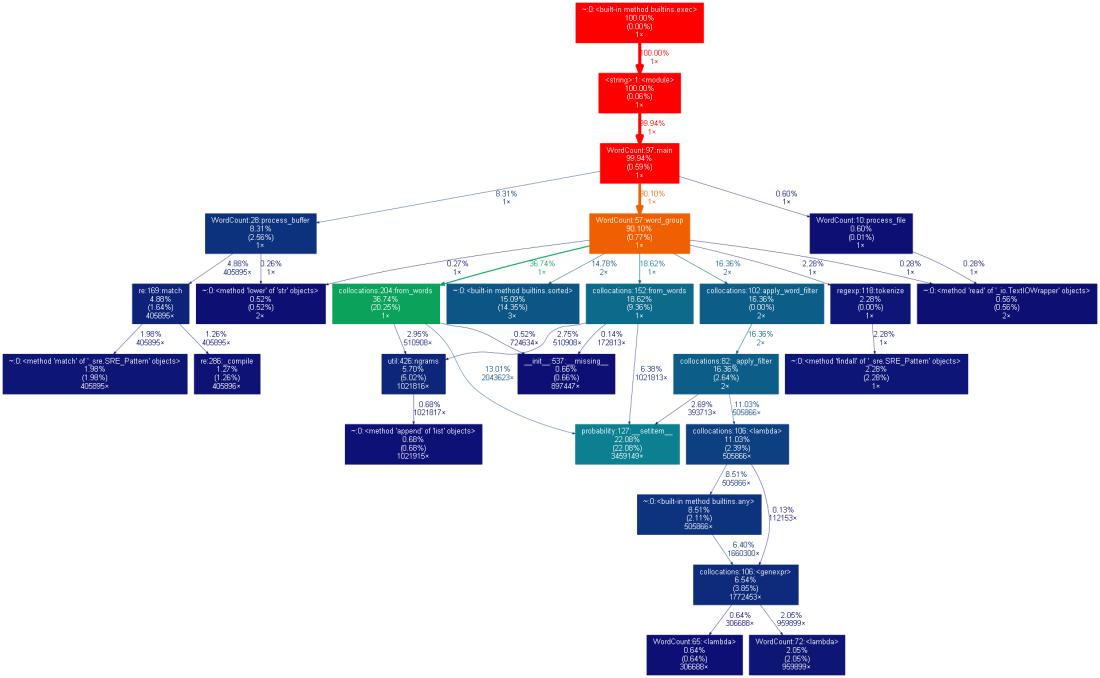
四、其他
4.1 結隊程式設計時間開銷
由於之前沒有接觸過python,大部分的時間用於學習python的各種函式應用,,查閱資料,一邊做,一邊學。查閱技術文件、結隊程式設計。大體分工為兩位同學同時查閱技術文件,接著交流討論。對各個技術方式實踐結隊程式設計最後選擇最合適的方案。
4.2 結隊程式設計照片

五、事後分析與總結
五、事後分析與總結
5.1簡述結對程式設計時,針對某個問題的討論決策過程。
在實現檢視高頻短語的功能時,蔣兆豐的程式碼與我的程式碼一度產生衝突。蔣兆豐的想法是使用字串組成想要提取的短語,我的想法是使用nltk中的collection方法。
5.2評價對方:請評價一下你的合作伙伴,又哪些具體的優點和需要改進的地方。 這個部分兩人都要提供自己的看法。
(1)劉賽對蔣兆豐的評價:蔣兆豐同學積極主動,好學,在我們學習python的時候理解的很快也理解的很好。
(2)蔣兆豐對劉賽的評價:劉賽同學在程式設計的時候有遇到很多問題,討論的時候提出了比較好的想法。
5.3評價整個過程
結對程式設計是一個相互學習、相互磨合的漸進過程,團隊合作對於程式設計而言很重要。
5.5其他
在學習一門新的語言時要多查詢資料多餘同學討論,並且要多敲程式碼,多進行實踐。