
keras快速搭建神經網路進行電影文字評論二分類
在本次部落格中,將討論英語文字分類問題,可同樣適用於文字情感分類,屬性分類等文字二分類問題。
1、資料準備
使用 IMDB 資料集,它包含來自網際網路電影資料庫(IMDB)的 50 000 條嚴重兩極分化的評論。資料集被分為用於訓練的 25 000 條評論與用於測試的 25 000 條評論,訓練集和測試集都包含 50% 的正面評論和 50% 的負面評論。
這個資料集已經在keras的database裡面有下載和讀取的方法,這裡我們直接呼叫即可。
from keras.datasets import imdb
(train_data, train_labels), (test_data, test_labels) = imdb.load_data(num_words=10000)
我們來打印出資料的一些資訊
# 列印資料集大小及部分資料資訊
print(train_data.shape)
print(train_data[0])
print(train_labels)
print(test_labels.shape)
可以看出,訓練集和測試集都有25000條評論,每條評論是一個長度不等的向量。在這個資料集中,每條評論已經編碼為數字,具體編碼流程如下:
首先,對25000條評論分詞,詞形還原,再進行詞頻統計,按照出現頻率從高到低編號1,2,3…接下來,把每一條評論裡面各個單詞轉化為對應標號,即組成這裡的每條評論行向量。
舉個例子,假設詞頻統計結果為{“I”: 29, “love”: 49, “you”: 21, “don’t”: 34, “hurt”: 102},那麼一條評論為"I hurt you"的行向量即為[29, 102, 21]
在這個資料集裡面,keras也提供了每個單詞編號對應編號這樣一個字典,這就意味著我們可以反解析出每條評論。
word_index = imdb.get_word_index() # word_index是一個字典,鍵為單詞,值為編碼後的數字
reverse_word_index = dict([(value, key) for (key, value) in word_index.items()]) # 將鍵值交換
這樣,reverse_word_index就記錄了每個編號對應的單詞,我們就可以反解析每條評論啦~
''' 還原第一條評論資訊.注意,索引減去了 3,因為 0、1、2是為“padding”(填充)、 “start of sequence”(序列開始)、“unknown”(未知詞)分別保留的索引 ''' decoded_review = ' '.join([reverse_word_index.get(i-3, '?') for i in train_data[0]])
我們打印出第一條評論的文字資訊:
? this film was just brilliant casting location scenery story direction
everyone's really suited the part they played and you could just imagine being there robert ?
is an amazing actor and now the same being director ? father came from the same scottish island as myself
so i loved the fact there was a real connection with this film the witty remarks throughout
the film were great it was just brilliant so much that i bought the film as soon as it was released for ?
and would recommend it to everyone to watch and the fly fishing was amazing really cried at the end it was so sad and you know what they say if you cry at a film
it must have been good and this definitely was also ?
to the two little boy's that played the ? of norman and paul they were just brilliant children are often left out of the ? list
i think because the stars that play them all grown up are such a big profile for the whole film
but these children are amazing and should be praised for what they have done
don't you think the whole story was so lovely because it was true and was someone's life after all that was shared with us all
2、資料預處理:對資料簡單編碼
因為一共10000個單詞(我們只選取了10000個出現頻率最高的單詞),我們給每條評論的向量初始化為10000個0的行向量,依次看每條評論出現單詞的編號是多少,在對應編號處將其置為1。假設某條評論出現單詞編號以此為12,250, 3600,則該評論處理後的向量為10000個零, 將第12, 250, 3600個零置為1。
# 使用one-hot編碼,使列表轉化為大小一致的張量
def vectorize_sequences(sequences, dimension=10000):
results = np.zeros((len(sequences), dimension)) # 建立一個sequences行,10000列的0向量
for i, sequence in enumerate(sequences):
results[i, sequence] = 1 # 將單詞出現指定處置為1
return results
x_train = vectorize_sequences(train_data)
x_test = vectorize_sequences(test_data)
與此同時,我們也將標籤向量化:
import numpy as np
# 將標籤向量化
y_train = np.asarray(train_labels).astype('float32')
y_test = np.asarray(test_labels).astype('float32')
3、建立模型
在keras裡面,模型可以通過models.Sequential()或者API建立。這裡我們用最常用的models.Sequential()
# 建立模型
model = models.Sequential()
model.add(layers.Dense(16, activation='relu', input_shape=(10000, )))
model.add(layers.Dense(16, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
接下來對神經網路層數,每層神經元個數,啟用函式等加以說明。這裡我們設定了三層神經網路,兩個隱藏層, 一個輸出層。考慮到資料量較小,這裡只有兩個隱藏層,且隱藏層神經元個數也較少(16和16,一般設定為2的冪)。因為這是二分類問題,所有最後一層,即輸出層只有一個神經元,且用“sigmod”輸出為二分類的概率。注意sigmod一般用於二分類問題,多分類問題輸出概率時用"softmax"。啟用函式在隱藏層都是"relu",也可以是"tanh"等,但不能是"sigmod",想一想這是為什麼???“sigmod"這個函式求導後最大值在0處取得,為0.25,遠小於1,當資料流入每一層神經網路時都會進行鏈式求導,自然就會讓輸入資料越來越小,導致"梯度彌散”,導致“早停”,達不到訓練效果。
4、模型訓練
model.compile(
optimizer=RMSprop(lr=0.001),
loss='binary_crossentropy',
metrics=['accuracy'])
優化器選擇隨機梯度下降(SGD)的變體,RMSprop,學習率為0.001,損失函式為二分類的交叉熵,評估指標為準確率。
因為這個資料集訓練集和測試集完全一樣,導致我們只能用一個。所有我們將訓練集裡面劃分一下,後15000條評論作為訓練模型用,前10000條評論作為測試用。
train_partion_data = x_train[10000:]
train_partion_label = y_train[10000:]
test_partion_data = x_train[:10000]
test_partion_label = y_train[:10000]
接下來開始訓練:
history = model.fit(
train_partion_data,
train_partion_label,
epochs=20, batch_size=512,
validation_data=(test_partion_data, test_partion_label))
用fit函式進行訓練,前兩個引數是訓練集資料和標籤,epochs是訓練多少輪,batch_size是一次訓練傳入多少樣本,validation_data裡面是測試資料和標籤,每一輪訓練完後都會用這裡面數據測試一下準確率。
最後別忘了儲存訓練好的模型,以便進行後期繼續訓練後者直接用於實際預測、分析和視覺化。
print(history.history)
model.save('IMDB.json')
模型訓練後有個history方法,裡面記錄了每一輪訓練的損失值和準確率,方便視覺化和觀察在第幾輪開始出現過擬合。
5、結果展示、視覺化和分析
首先看看第一輪訓練結果和最後一輪訓練結果:
Epoch 1/20
512/15000 [>.............................] - ETA: 2:10 - loss: 0.6931 - acc: 0.5020
1024/15000 [=>............................] - ETA: 1:03 - loss: 0.6841 - acc: 0.5850
1536/15000 [==>...........................] - ETA: 41s - loss: 0.6771 - acc: 0.5632
2048/15000 [===>..........................] - ETA: 30s - loss: 0.6726 - acc: 0.5708
2560/15000 [====>.........................] - ETA: 23s - loss: 0.6591 - acc: 0.6121
3072/15000 [=====>........................] - ETA: 18s - loss: 0.6472 - acc: 0.6328
3584/15000 [======>.......................] - ETA: 15s - loss: 0.6357 - acc: 0.6551
4096/15000 [=======>......................] - ETA: 13s - loss: 0.6258 - acc: 0.6641
4608/15000 [========>.....................] - ETA: 11s - loss: 0.6206 - acc: 0.6691
5120/15000 [=========>....................] - ETA: 9s - loss: 0.6090 - acc: 0.6779
5632/15000 [==========>...................] - ETA: 8s - loss: 0.5998 - acc: 0.6919
6144/15000 [===========>..................] - ETA: 7s - loss: 0.5899 - acc: 0.7020
6656/15000 [============>.................] - ETA: 6s - loss: 0.5837 - acc: 0.7090
7168/15000 [=============>................] - ETA: 5s - loss: 0.5754 - acc: 0.7153
7680/15000 [==============>...............] - ETA: 5s - loss: 0.5674 - acc: 0.7230
8192/15000 [===============>..............] - ETA: 4s - loss: 0.5622 - acc: 0.7266
8704/15000 [================>.............] - ETA: 3s - loss: 0.5551 - acc: 0.7330
9216/15000 [=================>............] - ETA: 3s - loss: 0.5485 - acc: 0.7396
9728/15000 [==================>...........] - ETA: 3s - loss: 0.5429 - acc: 0.7457
10240/15000 [===================>..........] - ETA: 2s - loss: 0.5354 - acc: 0.7509
10752/15000 [====================>.........] - ETA: 2s - loss: 0.5294 - acc: 0.7557
11264/15000 [=====================>........] - ETA: 1s - loss: 0.5230 - acc: 0.7607
11776/15000 [======================>.......] - ETA: 1s - loss: 0.5162 - acc: 0.7655
12288/15000 [=======================>......] - ETA: 1s - loss: 0.5106 - acc: 0.7687
12800/15000 [========================>.....] - ETA: 1s - loss: 0.5047 - acc: 0.7730
13312/15000 [=========================>....] - ETA: 0s - loss: 0.5017 - acc: 0.7741
13824/15000 [==========================>...] - ETA: 0s - loss: 0.4987 - acc: 0.7765
14336/15000 [===========================>..] - ETA: 0s - loss: 0.4944 - acc: 0.7795
14848/15000 [============================>.] - ETA: 0s - loss: 0.4896 - acc: 0.7828
15000/15000 [==============================] - 8s 513us/step - loss: 0.4879 - acc: 0.7841
- val_loss: 0.3425 - val_acc: 0.8788
Epoch 20/20
512/15000 [>.............................] - ETA: 1s - loss: 0.0015 - acc: 1.0000
1024/15000 [=>............................] - ETA: 1s - loss: 0.0013 - acc: 1.0000
1536/15000 [==>...........................] - ETA: 1s - loss: 0.0015 - acc: 1.0000
2048/15000 [===>..........................] - ETA: 1s - loss: 0.0016 - acc: 1.0000
2560/15000 [====>.........................] - ETA: 1s - loss: 0.0016 - acc: 1.0000
3072/15000 [=====>........................] - ETA: 1s - loss: 0.0016 - acc: 1.0000
3584/15000 [======>.......................] - ETA: 1s - loss: 0.0016 - acc: 1.0000
4096/15000 [=======>......................] - ETA: 1s - loss: 0.0015 - acc: 1.0000
4608/15000 [========>.....................] - ETA: 1s - loss: 0.0015 - acc: 1.0000
5120/15000 [=========>....................] - ETA: 1s - loss: 0.0015 - acc: 1.0000
5632/15000 [==========>...................] - ETA: 1s - loss: 0.0015 - acc: 1.0000
6144/15000 [===========>..................] - ETA: 0s - loss: 0.0014 - acc: 1.0000
6656/15000 [============>.................] - ETA: 0s - loss: 0.0014 - acc: 1.0000
7168/15000 [=============>................] - ETA: 0s - loss: 0.0014 - acc: 1.0000
7680/15000 [==============>...............] - ETA: 0s - loss: 0.0014 - acc: 1.0000
8192/15000 [===============>..............] - ETA: 0s - loss: 0.0014 - acc: 1.0000
8704/15000 [================>.............] - ETA: 0s - loss: 0.0014 - acc: 1.0000
9216/15000 [=================>............] - ETA: 0s - loss: 0.0017 - acc: 0.9999
9728/15000 [==================>...........] - ETA: 0s - loss: 0.0017 - acc: 0.9999
10240/15000 [===================>..........] - ETA: 0s - loss: 0.0017 - acc: 0.9999
10752/15000 [====================>.........] - ETA: 0s - loss: 0.0016 - acc: 0.9999
11264/15000 [=====================>........] - ETA: 0s - loss: 0.0016 - acc: 0.9999
11776/15000 [======================>.......] - ETA: 0s - loss: 0.0016 - acc: 0.9999
12288/15000 [=======================>......] - ETA: 0s - loss: 0.0016 - acc: 0.9999
12800/15000 [========================>.....] - ETA: 0s - loss: 0.0016 - acc: 0.9999
13312/15000 [=========================>....] - ETA: 0s - loss: 0.0016 - acc: 0.9999
13824/15000 [==========================>...] - ETA: 0s - loss: 0.0016 - acc: 0.9999
14336/15000 [===========================>..] - ETA: 0s - loss: 0.0016 - acc: 0.9999
14848/15000 [============================>.] - ETA: 0s - loss: 0.0016 - acc: 0.9999
15000/15000 [==============================] - 3s 170us/step - loss: 0.0016 - acc: 0.9999
- val_loss: 0.7605 - val_acc: 0.8631
在20次訓練後,準確率為86.31%。
我們來看看歷史紀錄打印出的值看看是否發生了過擬合:
history = {
'val_loss': [0.3797392254829407, 0.300249081659317, 0.3083435884475708, 0.283885223865509, 0.2847259536743164, 0.3144310226917267, 0.31279232678413393, 0.38592003211975096, 0.36343686447143553, 0.3843619570732117, 0.4167306966781616, 0.45070800895690916, 0.46998676981925963, 0.502394838142395, 0.5363822244167328, 0.572349524307251, 0.6167236045837402, 0.6382174592018127, 0.7905949376106263, 0.7077673551559448],
'val_acc': [0.8683999997138977, 0.8898000004768372, 0.8715000001907348, 0.8831000001907349, 0.8867000002861023, 0.8772999998092651, 0.8844999999046326, 0.8650999998092651, 0.8783000001907348, 0.8790000001907349, 0.8768999999046325, 0.8692999998092651, 0.8731999997138977, 0.8721999996185302, 0.8688999997138978, 0.8694999996185303, 0.8648999995231629, 0.8663999996185303, 0.8495000007629394, 0.8646999994277954],
'loss': [0.5085020663420359, 0.30055405753453573, 0.2179573760588964, 0.1750892378250758, 0.1426703708012899, 0.11497294256687164, 0.09784598382711411, 0.08069058032830556, 0.06599647818009059, 0.055482132176558174, 0.045179014571507775, 0.038426268839836124, 0.029788546661535898, 0.02438261934618155, 0.0176644352838397, 0.016922697043418884, 0.009341424687206746, 0.011814989059666792, 0.005609988443056742, 0.005509983973701795],
'acc': [0.7815333335240682, 0.9044666666984558, 0.9285333332697551, 0.9436666668891907, 0.954333333047231, 0.9652000000635783, 0.9706666668256124, 0.9762666667938232, 0.9821333333015442, 0.9851333333015442, 0.9887333332379659, 0.9912000002543131, 0.9928666666666667, 0.9948666666666667, 0.9978666666666667, 0.9970000001589457, 0.9994, 0.9974666666666666, 0.9998000002543131, 0.9996666666666667]
}
前兩個引數,‘val_loss’和’val_acc’就是測試集的效果,在第二輪訓練的時候,準確率達到0.8898,但最後一次訓練卻只有0.86.這明顯發生了過擬合,我們來畫出訓練集和測試集loss變化曲線,以供進一步分析。
import matplotlib.pyplot as plt
history_dict = {
'val_loss': [0.3797392254829407, 0.300249081659317, 0.3083435884475708, 0.283885223865509, 0.2847259536743164, 0.3144310226917267, 0.31279232678413393, 0.38592003211975096, 0.36343686447143553, 0.3843619570732117, 0.4167306966781616, 0.45070800895690916, 0.46998676981925963, 0.502394838142395, 0.5363822244167328, 0.572349524307251, 0.6167236045837402, 0.6382174592018127, 0.7905949376106263, 0.7077673551559448],
'val_acc': [0.8683999997138977, 0.8898000004768372, 0.8715000001907348, 0.8831000001907349, 0.8867000002861023, 0.8772999998092651, 0.8844999999046326, 0.8650999998092651, 0.8783000001907348, 0.8790000001907349, 0.8768999999046325, 0.8692999998092651, 0.8731999997138977, 0.8721999996185302, 0.8688999997138978, 0.8694999996185303, 0.8648999995231629, 0.8663999996185303, 0.8495000007629394, 0.8646999994277954],
'loss': [0.5085020663420359, 0.30055405753453573, 0.2179573760588964, 0.1750892378250758, 0.1426703708012899, 0.11497294256687164, 0.09784598382711411, 0.08069058032830556, 0.06599647818009059, 0.055482132176558174, 0.045179014571507775, 0.038426268839836124, 0.029788546661535898, 0.02438261934618155, 0.0176644352838397, 0.016922697043418884, 0.009341424687206746, 0.011814989059666792, 0.005609988443056742, 0.005509983973701795],
'acc': [0.7815333335240682, 0.9044666666984558, 0.9285333332697551, 0.9436666668891907, 0.954333333047231, 0.9652000000635783, 0.9706666668256124, 0.9762666667938232, 0.9821333333015442, 0.9851333333015442, 0.9887333332379659, 0.9912000002543131, 0.9928666666666667, 0.9948666666666667, 0.9978666666666667, 0.9970000001589457, 0.9994, 0.9974666666666666, 0.9998000002543131, 0.9996666666666667]
}
loss_values = history_dict['loss'] # 訓練集loss
val_loss_values = history_dict['val_loss'] # 測試集loss
epochs = range(1, len(loss_values) + 1)
plt.plot(epochs, loss_values, 'bo', label='Training loss')
plt.plot(epochs, val_loss_values, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()
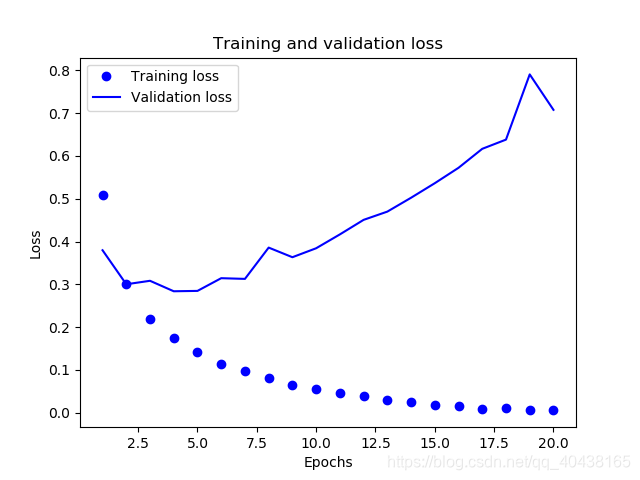
可以看出,訓練集loss不斷減小,而測試集loss卻在增長,發生了過擬合。
為確定我們的判斷,我們再畫出訓練集和測試集的準確率看看:
import matplotlib.pyplot as plt
history_dict = {
'val_loss': [0.3797392254829407, 0.300249081659317, 0.3083435884475708, 0.283885223865509, 0.2847259536743164, 0.3144310226917267, 0.31279232678413393, 0.38592003211975096, 0.36343686447143553, 0.3843619570732117, 0.4167306966781616, 0.45070800895690916, 0.46998676981925963, 0.502394838142395, 0.5363822244167328, 0.572349524307251, 0.6167236045837402, 0.6382174592018127, 0.7905949376106263, 0.7077673551559448],
'val_acc': [0.8683999997138977, 0.8898000004768372, 0.8715000001907348, 0.8831000001907349, 0.8867000002861023, 0.8772999998092651, 0.8844999999046326, 0.8650999998092651, 0.8783000001907348, 0.8790000001907349, 0.8768999999046325, 0.8692999998092651, 0.8731999997138977, 0.8721999996185302, 0.8688999997138978, 0.8694999996185303, 0.8648999995231629, 0.8663999996185303, 0.8495000007629394, 0.8646999994277954],
'loss': [0.5085020663420359, 0.30055405753453573, 0.2179573760588964, 0.1750892378250758, 0.1426703708012899, 0.11497294256687164, 0.09784598382711411, 0.08069058032830556, 0.06599647818009059, 0.055482132176558174, 0.045179014571507775, 0.038426268839836124, 0.029788546661535898, 0.02438261934618155, 0.0176644352838397, 0.016922697043418884, 0.009341424687206746, 0.011814989059666792, 0.005609988443056742, 0.005509983973701795],
'acc': [0.7815333335240682, 0.9044666666984558, 0.9285333332697551, 0.9436666668891907, 0.954333333047231, 0.9652000000635783, 0.9706666668256124, 0.9762666667938232, 0.9821333333015442, 0.9851333333015442, 0.9887333332379659, 0.9912000002543131, 0.9928666666666667, 0.9948666666666667, 0.9978666666666667, 0.9970000001589457, 0.9994, 0.9974666666666666, 0.9998000002543131, 0.9996666666666667]
}
loss_values = history_dict['acc'] # 訓練集loss
val_loss_values = history_dict['val_acc'] # 測試集loss
epochs = range(1, len(loss_values) + 1)
plt.plot(epochs, loss_values, 'bo', label='Training acc')
plt.plot(epochs, val_loss_values, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
plt.show()
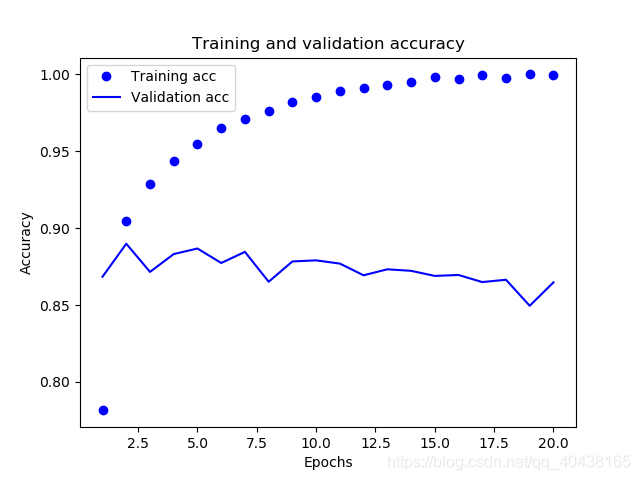
訓練集準確率不斷上升,而測試集準確率卻波瀾起伏,在最後幾次不斷下降,明顯發生過擬合。遇到這種情況我們需要採取一些措施,最簡單的就是少訓練幾輪,當然還有更多方法,比如正則化,dropout等等,以後會討論。