
使用pytorch快速搭建神經網路實現二分類任務(包含示例)
阿新 • • 發佈:2020-08-03
# 使用pytorch快速搭建神經網路實現二分類任務(包含示例)
---
## Introduce
[上一篇學習筆記](https://www.cnblogs.com/wangqinze/p/13418291.html)介紹了不使用pytorch包裝好的神經網路框架實現logistic迴歸模型,並且根據autograd實現了神經網路引數更新。
==**本文介紹利用pytorch快速搭建神經網路。即利用torch.nn以及torch.optim庫來快捷搭建一個簡單的神經網路來實現二分類功能。**==
- **利用pytorch已經包裝好的庫(torch.nn)來快速搭建神經網路結構。**
- **利用已經包裝好的包含各種優化演算法的庫(torch.optim)來優化神經網路中的引數,如權值引數w和閾值引數b。**
==以下均為初學者筆記。==
---
## Build a neural network structure
假設我們要搭建一個帶有兩個隱層的神經網路來實現節點的二分類,輸入層包括2個節點(輸入節點特徵),兩個隱層均包含5個節點(特徵對映),輸出層包括2個節點(分別輸出屬於對應節點標籤的概率)。如下圖所示:
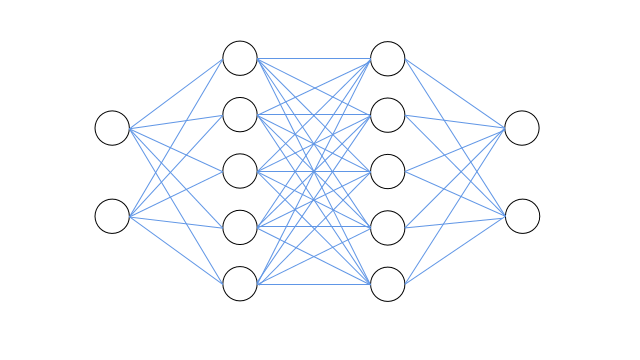
上圖從左右到右為輸入層、隱藏層、隱藏層、輸出層,各層之間採用全連線結構。神經網路兩隱藏層的啟用函式均採用sigmoid函式,輸出層最後採用softmax函式歸一化概率。
**網路搭建過程中使用的torch.nn相關模組介紹如下:**
- **torch.nn.Sequential**:是一個時序容器,我們可以通過呼叫其構造器,將神經網路模組按照輸入層到輸出層的順序傳入,以此構造完整的神經網路結構,具體用法參考如下神經網路搭建程式碼。
- **torch.nn.Linear**:設定網路中的全連線層,用來實現網路中節點輸入的線性求和,即實現如下線性變換函式:
$$
y = xA^T + b
$$
```
'''
搭建神經網路,
輸入層包括2個節點,兩個隱層均包含5個節點,輸出層包括1個節點。'''
net = nn.Sequential(
nn.Linear(2,5), # 輸入層與第一隱層結點數設定,全連線結構
torch.nn.Sigmoid(), # 第一隱層啟用函式採用sigmoid
nn.Linear(5,5), # 第一隱層與第二隱層結點數設定,全連線結構
torch.nn.Sigmoid(), # 第一隱層啟用函式採用sigmoid
nn.Linear(5,2), # 第二隱層與輸出層層結點數設定,全連線結構
nn.Softmax(dim=1) # 由於有兩個概率輸出,因此對其使用Softmax進行概率歸一化,dim=1代表行歸一化
)
print(net)
'''
Sequential(
(0): Linear(in_features=2, out_features=5, bias=True)
(1): Sigmoid()
(2): Linear(in_features=5, out_features=5, bias=True)
(3): Sigmoid()
(4): Linear(in_features=5, out_features=2, bias=True)
(5): Softmax(dim=1)
)'''
```
---
## Configure Loss Function and Optimizer
**note:** torch.optim庫中封裝了許多常用的優化方法,這邊使用了最常用的隨機梯度下降來優化網路引數。例子中使用了交叉熵損失作為代價函式,其實torch.nn中也封裝了許多代價函式,具體可以檢視官方文件。**對於pytorch中各種損失函式的學習以及優化方法的學習將在後期進行補充。**
**配置損失函式和優化器的程式碼如下所示:**
```
# 配置損失函式和優化器
optimizer = torch.optim.SGD(net.parameters(),lr=0.01) # 優化器使用隨機梯度下降,傳入網路引數和學習率
loss_func = torch.nn.CrossEntropyLoss() # 損失函式使用交叉熵損失函式
```
---
## Model Training
**神經網路訓練過程大致如下**:首先輸入資料,接著神經網路進行前向傳播,計算輸出層的輸出,進而計算預先定義好的損失(如本例中的交叉熵損失),接著進行誤差反向傳播,利用事先設定的優化方法(如本例中的隨機梯度下降SGD)來更新網路中的引數,如權值引數w和閾值引數b。接著反覆進行上述迭代,達到最大迭代次數(num_epoch)或者損失值滿足某條件之後訓練停止,從而我們可以得到一個由大量資料訓練完成的神經網路模型。**模型訓練的程式碼如下所示:**
```
# 模型訓練
num_epoch = 10000 # 最大迭代更新次數
for epoch in range(num_epoch):
y_p = net(x_t) # 喂資料並前向傳播
loss = loss_func(y_p,y_t.long()) # 計算損失
'''
PyTorch預設會對梯度進行累加,因此為了不使得之前計算的梯度影響到當前計算,需要手動清除梯度。
pyTorch這樣子設定也有許多好處,但是由於個人能力,還沒完全弄懂。
'''
optimizer.zero_grad() # 清除梯度
loss.backward() # 計算梯度,誤差回傳
optimizer.step() # 根據計算的梯度,更新網路中的引數
if epoch % 1000 == 0:
print('epoch: {}, loss: {}'.format(epoch, loss.data.item()))
'''
每1000次輸出損失如下:
epoch: 0, loss: 0.7303197979927063
epoch: 1000, loss: 0.669952392578125
epoch: 2000, loss: 0.6142827868461609
epoch: 3000, loss: 0.5110923051834106
epoch: 4000, loss: 0.4233965575695038
epoch: 5000, loss: 0.37978556752204895
epoch: 6000, loss: 0.3588798940181732
epoch: 7000, loss: 0.3476340174674988
......
'''
print("所有樣本的預測標籤: \n",torch.max(y_p,dim = 1)[1])
'''
note:可以發現前100個標籤預測為0,後100個樣本標籤預測為1。因此所訓練模型可以正確預測訓練集標籤。
所有樣本的預測標籤:
tensor([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1])
'''
```
---
## 網路的儲存和提取
```
'''兩種儲存方式
第一種: 儲存網路的所有引數(包括網路結構)
torch.save(net,'net.pkl')
對應載入方式: net1 = torch.load('net.pkl')
第二種: 僅儲存網路中需要訓練的引數 ,即net.state_dict(),如權值引數w和閾值引數b。(不包括網路結構)
torch.save(net.state_dict(),'net_parameter.pkl')
對應載入方式:
載入時需要提供兩個資訊:
第一: 網路結構資訊,需要先重新搭建和儲存的網路同樣的網路結構。
第二: 儲存的網路中的引數的資訊,權值和閾值引數。
具體載入方式如下:
net = nn.Sequential(
nn.Linear(2,5),
torch.nn.Sigmoid(),
nn.Linear(5,5),
torch.nn.Sigmoid(),
nn.Linear(5,2),
nn.Softmax(dim=1)
)
net2.load_state_dict(torch.load('net_parameter.pkl')
'''
```
[本文參考-1](https://github.com/zergtant/pytorch-handbook/blob/master/chapter1/3_neural_networks_tutorial.ipynb)
[本文參考-2](https://zhuanlan.zhihu.com/p/115251842)
## 附完整程式碼
```
import torch
import torch.nn as nn
'''
使用正態分佈隨機生成兩類資料
第一類有100個點,使用均值為2,標準差為1的正態分佈隨機生成,標籤為0。
第二類有100個點,使用均值為-2,標準差為1的正態分佈隨機生成,標籤為1。
torch.normal(tensor1,tensor2)
輸入兩個張量,tensor1為正態分佈的均值,tensor2為正態分佈的標準差。
torch.normal以此抽取tensor1和tensor2中對應位置的元素值構造對應的正態分佈以隨機生成資料,返回資料張量。
'''
x1_t = torch.normal(2*torch.ones(100,2),1)
y1_t = torch.zeros(100)
x2_t = torch.normal(-2*torch.ones(100,2),1)
y2_t = torch.ones(100)
x_t = torch.cat((x1_t,x2_t),0)
y_t = torch.cat((y1_t,y2_t),0)
'''
搭建神經網路,
輸入層包括2個節點,兩個隱層均包含5個節點,輸出層包括1個節點。
'''
net = nn.Sequential(
nn.Linear(2,5), # 輸入層與第一隱層結點數設定,全連線結構
torch.nn.Sigmoid(), # 第一隱層啟用函式採用sigmoid
nn.Linear(5,5), # 第一隱層與第二隱層結點數設定,全連線結構
torch.nn.Sigmoid(), # 第一隱層啟用函式採用sigmoid
nn.Linear(5,2), # 第二隱層與輸出層層結點數設定,全連線結構
nn.Softmax(dim=1) # 由於有兩個概率輸出,因此對其使用Softmax進行概率歸一化
)
print(net)
'''
Sequential(
(0): Linear(in_features=2, out_features=5, bias=True)
(1): Sigmoid()
(2): Linear(in_features=5, out_features=5, bias=True)
(3): Sigmoid()
(4): Linear(in_features=5, out_features=2, bias=True)
(5): Softmax(dim=1)
)'''
# 配置損失函式和優化器
optimizer = torch.optim.SGD(net.parameters(),lr=0.01) # 優化器使用隨機梯度下降,傳入網路引數和學習率
loss_func = torch.nn.CrossEntropyLoss() # 損失函式使用交叉熵損失函式
# 模型訓練
num_epoch = 10000 # 最大迭代更新次數
for epoch in range(num_epoch):
y_p = net(x_t) # 喂資料並前向傳播
loss = loss_func(y_p,y_t.long()) # 計算損失
'''
PyTorch預設會對梯度進行累加,因此為了不使得之前計算的梯度影響到當前計算,需要手動清除梯度。
pyTorch這樣子設定也有許多好處,但是由於個人能力,還沒完全弄懂。
'''
optimizer.zero_grad() # 清除梯度
loss.backward() # 計算梯度,誤差回傳
optimizer.step() # 根據計算的梯度,更新網路中的引數
if epoch % 1000 == 0:
print('epoch: {}, loss: {}'.format(epoch, loss.data.item()))
'''
torch.max(y_p,dim = 1)[0]是每行最大的值
torch.max(y_p,dim = 1)[0]是每行最大的值的下標,可認為標籤
'''
print("所有樣本的預測標籤: \n",torch.max(y_p,dim = 1)[1]