
ElasticSearch 索引 剖析
ElasticSearch index 剖析
在看ElasticSearch權威指南基礎入門中關於:分片內部原理這一小節內容後,大致對ElasticSearch的索引、搜尋底層實現有了一個初步的認識。記錄一下在看文件的過程中碰到的問題以及我的理解。此外,在文章的末尾,還討論分散式系統中的主從複製原理,以及採用這種副本複製方案帶來的資料一致性問題。
ElasticSearch index 操作背後發生了什麼?
更具體地,就是執行PUT操作向ElasticSearch新增一篇文件時,底層發生的一系列操作。
PUT user/profile/10 { "content":"向user索引中新增一篇id為10的文件" }
通過PUT請求發起了索引新文件的操作,該操作能夠執行的前提是:叢集中有“一定數量”的活躍 shards。這個配置由wait_for_active_shards指定。ElasticSearch關於分片有2個重要的概念:primary shard 和 replica。在定義索引的時候指定索引有幾個主分片,以及每個主分片有多少個副本。比如:
PUT user
{
"settings": {
"number_of_shards": 3,
"number_of_replicas": 2
},
介紹一下叢集的環境:ElasticSearch6.3.2三節點叢集。定義了一個user索引,該索引有三個主分片,每個主分片2個副本。如圖,每個節點上有三個shards:一個 primary shard,二個replica
wait_for_active_shards
To improve the resiliency of writes to the system, indexing operations can be configured to wait for a certain number of active shard copies before proceeding with the operation.
在索引一篇文件時,通過wait_for_active_shards指定有多少個活躍的shards時,才能執行索引文件的操作。預設情況下,只要primary shard 是活躍的就可以索引文件
wait_for_active_shards值為1
By default, write operations only wait for the primary shards to be active before proceeding (i.e.
wait_for_active_shards=1)
來驗證一下:在只有一臺節點的ElasticSearch上:三個primary shard 全部分配在一臺節點中,並且存在著未分配的replica
執行:
PUT user/profile/10
{
"content":"向user索引中新增一篇id為10的文件"
}返回結果:
{
"_index": "user",
"_type": "profile",
"_id": "10",
"_version": 1,
"result": "created",
"_shards": {
"total": 3,
"successful": 1,
"failed": 0
},
"_seq_no": 0,
"_primary_term": 1
}在_shards 中,total 為3,說明該索引操作應該在3個(一個primary shard,二個replica)分片中執行成功;但是successful為1 說明 PUT操作 在其中一個分片中執行成功了,就返回給client索引成功的確認。這個分片就是primary shard,因為只有一臺節點,另外2個replica 屬於 unassigned shards,不可能在2個replica 中執行成功。總之,預設情況下,只要primary shard 是活躍的,就能索引文件(index操作)
現在在單節點的叢集上,刪除原來的user索引,並指定:wait_for_active_shards=2,這意味著一個索引操作至少要在2個分片上執行成功,才能返回給client acknowledge。
"settings": {
"index.write.wait_for_active_shards": "2"
}再次向user索引中PUT 一篇文件:
PUT user/profile/10
{
"content":"向user索引中新增一篇id為10的文件"
}返回結果:
{
"statusCode": 504,
"error": "Gateway Time-out",
"message": "Client request timeout"
}由於是單節點的ElasticSearch,另外的2個replica無法分配,因此不可能是活躍的。而我們指定的wait_for_active_shards為2,但現在只有1個primary shard是活躍的,因此無法進行索引操作了。
The primary shard assigned to perform the index operation might not be available when the index operation is executed. Some reasons for this might be that the primary shard is currently recovering from a gateway or undergoing relocation. By default, the index operation will wait on the primary shard to become available for up to 1 minute before failing and responding with an error.
索引操作會在1分鐘之後超時。
總結一下:由於文件最終是存在在某個ElasticSearch shard下面的,而每個shard又設定了副本數。預設情況下,在進行索引文件操作時,ElasticSearch會檢查活躍的分片數量是否達到wait_for_active_shards設定的值。若未達到,則索引操作會超時,超時時間為1分鐘。另外,值得注意的是:檢查活躍分片數量只是在開始索引資料的時候檢查,若檢查通過後,在索引文件的過程中,叢集中又有分片因為某些原因掛掉了,那索引文件操作還是會繼續進行。
因為索引文件操作(也即寫操作)發生在 檢查活躍分片數量 操作之後。試想以下幾個問題:
- 問題1:檢查活躍分片數量滿足
wait_for_active_shards設定的值之後,在持續 bulk index 文件過程中有 shard 失效了(這裡的shard是replica),那 難道不能繼續索引文件了? - 問題2:在什麼時候檢查叢集中的活躍分片數量?難道要 每次client傳送索引文件請求時就要檢查一次嗎?還是說週期性地隔多久檢查一次?
- 問題3:這裡的 check-then-act 並不是原子操作,因此
wait_for_active_shards這個配置引數又有多大的意義?
因此,官方文件中是這麼說的:
It is important to note that this setting greatly reduces the chances of the write operation not writing to the requisite number of shard copies, but it does not completely eliminate the possibility, because this check occurs before the write operation commences. Once the write operation is underway, it is still possible for replication to fail on any number of shard copies but still succeed on the primary.
- 該引數只是儘可能地保證新文件能夠寫入到我們所要求的shard數量中(reduce the chance of ....)。比如:
wait_for_active_shards設定為2,那也只是儘可能地保證將新文件寫入了2個shard中,當然一個是primary shard,另外就是某一個replica - check 操作發生在 write操作之前,在寫操作正在進行過程中,有可能某些shard出了問題,只要不是primary shard,那寫操作還是會繼續進行。
最後,說一下wait_for_active_shards引數的取值:可以設定成 all 或者是 1到 number_of_replicas+1 之間的任何一個整數。
Valid values are
allor any positive integer up to the total number of configured copies per shard in the index (which isnumber_of_replicas+1)
number_of_replicas 為索引指定的副本的數量,加1是指:再算上primary shard。比如前面user索引的副本數量為2,那麼wait_for_active_shards最多設定為3。
好,前面討論完了ElasticSearch能夠執行索引操作(寫操作)了,接下來是在寫操作過程中發生了什麼?比如說ElasticSearch是如何做到近實時搜尋的?在將文件寫入ElasticSearch時候發生了故障,那文件會不會丟失?
由於ElasticSearch底層是Lucene,在將一篇文件寫入ElasticSearch,並最終能被Client查詢到,涉及到以下幾個概念:倒排索引、Lucene段、提交點、translog、ElasticSearch分片。這裡概念都是參考《ElasticSearch definitive guide》中相關的描述。
In Elasticsearch, the most basic unit of storage of data is a shard. But, looking through the Lucene lens makes things a bit different. Here, each Elasticsearch shard is a Lucene index, and each Lucene index consists of several Lucene segments. A segment is an inverted index of the mapping of terms to the documents containing those terms.
它們之間的關係示意圖如下:
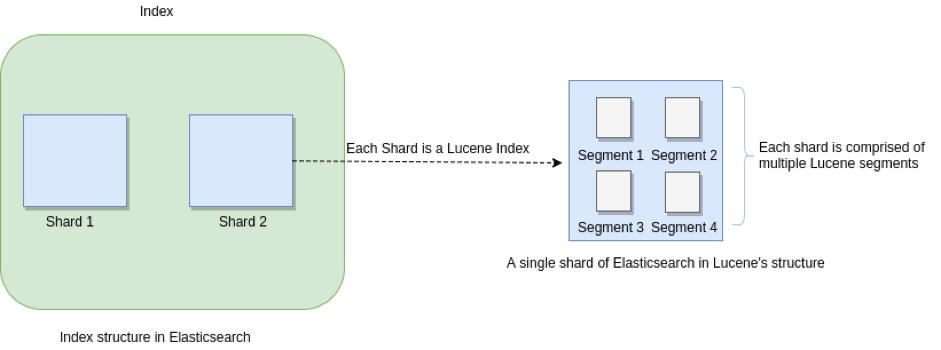
一個ElasticSearch 索引可由多個 primary shard組成,每個primary shard相當於一個Lucene Index;一個Lucene index 由多個Segment組成,每個Segment是一個倒排索引結構表
從文件的角度來看:文章會被analyze(比如分詞),然後放到倒排索引(posting list)中。倒排索引之於ElasticSearch就相當於B+樹之於Mysql,是儲存引擎底層的儲存結構。
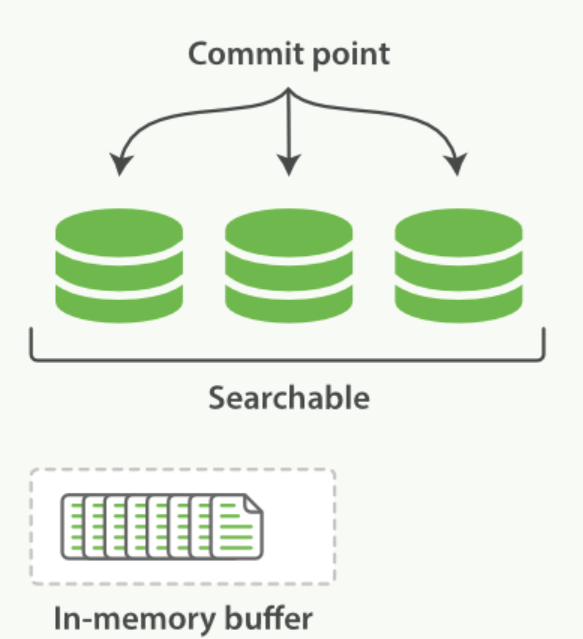
當文件寫入ElasticSearch時,文件首先被儲存在記憶體索引快取中(in-memeory indexing buffer)。而in-memory buffer是每隔1秒鐘重新整理一次,重新整理成一個個的可搜尋的段--下圖中的綠色圓柱表示(segment),然後這些段是每隔30分鐘同步到磁碟中持久化儲存,段同步到磁碟的過程稱為 提交 commit。
在這裡涉及到了兩個過程:① In-memory buffer中的文件被重新整理成段;②段提交 同步到磁碟 持久化儲存。
過程①預設是1秒鐘1次,這也能理解為什麼ElasticSearch中還有段合併操作。另外ElasticSearch提供了 refresh API 來控制過程①。refresh操作強制把In-memory buffer中的內容重新整理成段。refresh示意圖如下:

比如說,你可以在每次index一篇文件之後就呼叫一次refresh API,也即:每索引一篇文件就強制重新整理生成一個段,這會導致系統中存在大量的小段,是有效能開銷的。而我們所說的ElasticSearch是提供了近實時搜尋,指的是:文件的變化並不是立即對搜尋可見,但會在一秒之後變為可見,一秒鐘之後,我們寫入的文件就可以被搜尋到了。
對於過程②,就是將段重新整理到磁碟中去,預設是每隔30分鐘一次,這個重新整理過程稱為提交。如果還未來得及提交時,發生了故障,那豈不是會丟失大量的文件資料?這個時候,就引入了translog
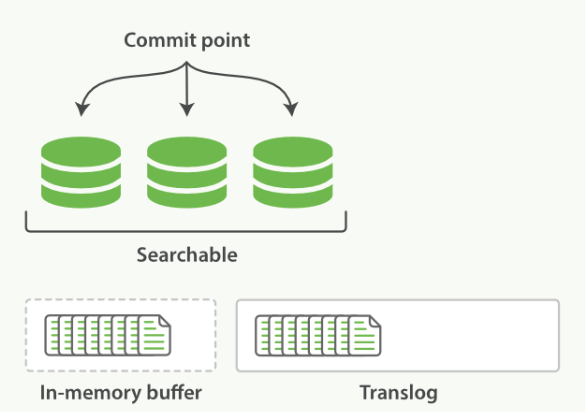
每篇文件寫入到In-memroy buffer中時,同時也會向 translog中寫一條記錄。In-memory buffer 每秒重新整理一次,重新整理後生成新段,in-memory被清空,文件可以被搜尋。
而translog 預設是每5秒鐘重新整理一次到磁碟,或者是在每次請求(index、delete、update、bulk)之後就重新整理到磁碟。每5秒鐘重新整理一次就是非同步重新整理,可以通過如下方式開啟:
PUT /my_index/_settings
{
"index.translog.durability": "async",
"index.translog.sync_interval": "5s"
}這種方式的話,還是有可能會丟失文件資料,比如Client發起index操作之後,ElasticSearch返回了200響應,但是由於translog要等5秒鐘之後才重新整理到磁碟,如果在5秒內系統宕機了,那麼這幾秒鐘內寫入的文件資料就丟失了。
而在每次請求操作(index、delete、update、bulk)執行後就重新整理translog到磁碟,則是translog同步重新整理,比如說:當Client PUT一個文件:
PUT user/profile/10
{
"content":"向user索引中新增一篇id為10的文件"
}在前面提到的三節點ElasticSearch叢集中,該user索引有三個primary shard,每個primary shard2個replica,那麼translog需要在某個primary shard中重新整理成功,並且在該primary shard的兩個replica中也重新整理成功,才會給Client返回 200 PUT成功響應。這種方式就保證了,只要Client接收到的響應是200,就意味著該文件一定是成功索引到ElasticSearch中去了。因為translog是成功持久化到磁碟之後,再給Client響應的,系統宕機後在下一次重啟ElasticSearch時,就會讀取translog進行恢復。
By default, Elasticsearch
fsyncs and commits the translog every 5 seconds ifindex.translog.durabilityis set toasyncor if set torequest(default) at the end of every index, delete, update, or bulk request. More precisely, if set torequest, Elasticsearch will only report success of an index, delete, update, or bulk request to the client after the translog has been successfullyfsynced and committed on the primary and on every allocated replica.
這也是為什麼,在我們關閉ElasticSearch時最好進行一次flush操作,將段重新整理到磁碟中。因為這樣會清空translog,那麼在重啟ElasticSearch就會很快(不需要恢復大量的translog了)
translog 也被用來提供實時 CRUD 。當你試著通過ID查詢、更新、刪除一個文件,它會在嘗試從相應的段中檢索之前, 首先檢查 translog 任何最近的變更。這意味著它總是能夠實時地獲取到文件的最新版本。
放一張總結性的圖,如下:
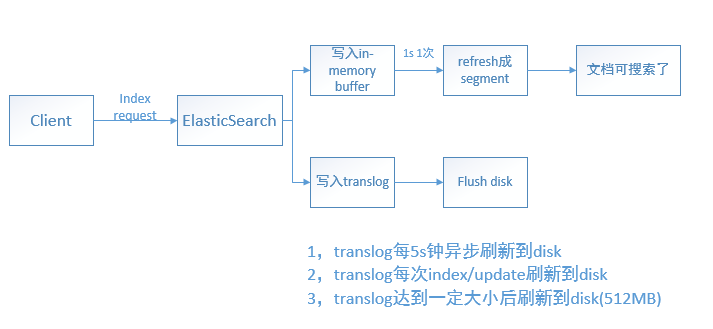
有個問題是:為什麼translog可以在每次請求之後重新整理到磁碟?難道不會影響效能嗎?相比於將 段(segment)重新整理到磁碟,重新整理translog的代價是要小得多的,因為translog是經過精心設計的資料結構,而段(segment)是倒排索引,我們無法做到每次將段重新整理到磁碟;而translog相比於段要輕量級簡單得多,因此通過translog機制來保證資料不丟失又不影響查詢效能。
Changes to Lucene are only persisted to disk during a Lucene commit, which is a relatively expensive operation and so cannot be performed after every index or delete operation.
......
All index and delete operations are written to the translog after being processed by the internal Lucene index but before they are acknowledged. In the event of a crash, recent transactions that have been acknowledged but not yet included in the last Lucene commit can instead be recovered from the translog when the shard recovers.總結一下:
這裡一共有三個地方有“重新整理操作”:
in-memory buffer 重新整理 生成segment
每秒一次,文件重新整理成segment就可以被搜尋到了,ElasticSearch提供了refresh API 來控制這個過程
translog 重新整理到磁碟
由
index.translog.durability來設定,或者由index.translog.flush_threshold_size來設定當translog達到一定大小之後重新整理到磁碟(預設512MB)段(segment) 重新整理到磁碟
每30分鐘一次,ElasticSearch提供了flush API 來控制這個過程。在段被重新整理到磁碟(就是通常所說的commit操作)中時,也會清空重新整理translog。
存在的一些問題
這個 issue 和 這個 issue 討論了index.write.wait_for_active_shards引數的來龍去脈。
以三節點ElasticSearch6.3.2叢集,索引設定為3個primary shard,每個primary shard 有2個replica 來討論:
- client向其中一個節點發起Index操作索引文件,這個寫操作請求當然是傳送到primary shard上,但是當Client收到200響應時,該文件是否已經複製到另外2個replica上?
- Client將一篇文件成功寫入到ElasticSearch了(收到了200響應),它能在replica所在的節點上 GET 到這篇文件嗎?Client發起查詢請求,又能查詢到這篇文件嗎?(注意:GET 和 Query 是不一樣的)
- 前面提到,當 index 一篇文件時,primary shard 和2個replica 上的translog 要 都重新整理 到磁碟,才返回 200 響應,那它是否與引數
index.write.wait_for_active_shards預設值 矛盾?因為index.write.wait_for_active_shards預設值為1,即:只要primary shard 是活躍的,就可以進行 index 操作。也就是說:當Client收到200的index成功響應,此時primary shard 已經將文件 複製 到2個replica 上了嗎?這兩個 replica 已經將文件重新整理成 segment了嗎?還是說這兩個 replica 僅僅只是 將索引該文件的 translog 重新整理到磁碟上了?
ElasticSearch副本複製方式討論
ElasticSearch索引是一個邏輯概念,囊括現實世界中的資料。比如 定義一個 user 索引儲存所有的使用者資料資訊。索引由若干個primary shard組成,就相當於把使用者資料資訊 分開成 若干個部分儲存,每個primary shard儲存user索引中的一部分資料。為了保證資料可靠性不丟失,可以為每個primary shard配置副本(replica)。顯然,primary shard 和它對應的replica 是不會儲存在同一臺機器(node)上的,因為如果該機器宕機了,那麼primary shard 和 副本(replica) 都會丟失,那整個系統就丟失一部分資料了。
primary shard 和 replica 這種副本備份方案,稱為主從備份。primary shard是主(single leader),replica 是 從 (multiple replica)。由於是分散式環境,可能存在多個Client同時向ElasticSearch發起索引文件的請求,這篇文件會根據 文件id 雜湊到某個 primary shard,primary shard寫入該文件 並分發給 replica 進行儲存。由於採用了雜湊,這也是為什麼 在定義索引的時候,需要指定primary shard個數,並且 primary shard個數一經指定後不可修改的原因。因為primary shard個數一旦改變,雜湊對映 結果就變了。而採用這種主從副本備份方案,這也是為什麼 索引操作(寫操作、update操作) 只能由 primary shard處理,而讀操作既可以從 primary shard讀取,也可以從 replica 讀取的原因。相對於文件而言,primary shard是single leader,所有的文件修改操作都統一由primary shard處理,能避免一些 併發修改 衝突。但是預設情況下,ElasticSearch 副本複製方式 是非同步的,也正如前面 index.write.wait_for_active_shards討論,只要primary shard 是活躍的就可以進行索引操作,primary shard 將文件 “ 儲存 ” 之後,就返回給client 響應,然後primary shard 再將該文件同步給replicas,而這就是非同步副本複製方式。在ElasticSearch官方討論論壇裡面,也有關於副本複製方式的討論:這篇文章提出了一個問題:Client向primary shard寫入文件成功,primary shard 是通過何種方式將該文件同步到 replica的?
採用非同步副本複製方式帶來的一個問題是:讀操作能讀取最新寫入的文件嗎?如果我們指定讀請求去讀primary shard(通過ElasticSearch 的路由機制),那麼是能讀到最新資料的。但是如果讀請求是由某個 replica 接收處理,那也許就不能讀取到剛才最新寫入的文件了。因此,從剛才Client 讀請求的角度來看,ElasticSearch能提供 哪種程度的 一致性呢?而出現這種一致性問題的原因在於:為了保證資料可靠性,採用了副本備份,引入了副本,導致副本和primary shard上的資料不一致,即:存在 replication lag 問題。由於這種副本複製延遲帶來的問題,系統需要給Client 某種資料一致性的 保證,比如說:
read your own write
Client能夠讀取到它自己最新寫入的資料。比如使用者修改了暱稱,那TA訪問自己的主頁時,能看到自己修改了的暱稱,但是TA的好友 可能 並不能立即看到 TA 修改後的暱稱。好友請求的是某個 replica 上的資料,而 primary shard還未來得及把剛才修改的暱稱 同步 到 replica上。
Monotonic reads
單調讀。每次Client讀取的值,是越來越新的值(站在Client角度來看的)。比如說NBA籃球比賽,Client每10分鐘讀一次比賽結果。第10分鐘讀取到的是 1:1,第20分鐘讀到的是2:2,第30分鐘讀到的是3:3,假設在第40分鐘時,實際比賽結果是4:4,Cleint在第40分鐘讀取的時候,讀到的值可以是3:3 這意味著未讀取到最新結果而已,讀到的值也可以是4:4, 但是不能是2:2 。
consistent prefix reads
符合因果關係的一種讀操作。比如說,使用者1 和 使用者2 對話:
使用者1:你現在幹嘛?
使用者2:寫程式碼對於Client讀:應該是先讀取到“你現在幹嘛?”,然後再讀取到 “寫程式碼。如果讀取結果順序亂了,Client就會莫名其妙。
正是由於Client 有了系統給予的這種 一致性 保證,那麼Client(或者說應用程式)就能基於這種保證 來開發功能,為使用者提供服務。
那系統又是如何提供這種一致性保證的呢?或者說ElasticSearch叢集又提供了何種一致性保證?經常聽到的有:強一致性(linearizability)、弱一致性、最終一致性。對於強一致性,通俗的理解就是:實際上資料有多份(primary shard 以及多個 replica),但在Client看來,表現得就只有一份資料。在多個 client 併發讀寫情形下,某個Client在修改資料A,而又有多個Client在同時讀資料A,linearizability 就要保證:如果某個Client讀取到了資料A,那在該Client之後的讀取請求返回的結果都不能比資料A要 舊,至少是資料A的當前值(不能是資料A的舊值)。不說了,再說,我自己都不明白了。
至於系統如何提供這種一致性,會用到一些分散式共識演算法,我也沒有深入地去研究過。
參考資料
ElasticSearch關於translog的官方文件解釋:https://www.elastic.co/guide/en/elasticsearch/reference/master/index-modules-translog.html#_translog_settings
- ElasticSearch權威指南中文版 基礎入門小節中的:分片內部原理(再結合英文原文閱讀一遍):https://elasticsearch.cn/book/elasticsearch_definitive_guide_2.x/translog.html
- 分散式中的 transaction log