
菜鳥學爬蟲之爬取網易新聞
學習了python基本語法後,對爬蟲產生了很大的興趣,廢話不多說,今天來爬取網易新聞,實戰出真知。
開啟網易新聞(https://news.163.com/)可以發現新聞分為這樣的幾個板塊:
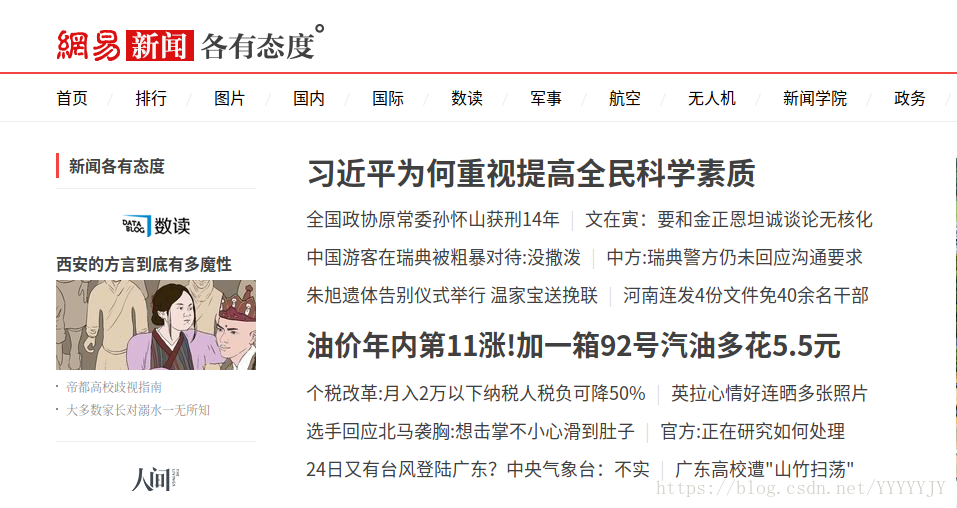
這次選擇國內板塊來爬取文章。
1.準備
環境:python3
編譯器:PyCharm
安裝selenium針對三大瀏覽器驅動driver
下載地址
1.chromedriver :https://code.google.com/p/chromedriver/downloads/list
2.Firefox的驅動geckodriver :https://github.com/mozilla/geckodriver/releases/
3.IE的驅動IEdriver :http://www.nuget.org/packages/Selenium.WebDriver.IEDriver/
瞭解網頁
網頁絢麗多彩,美輪美奐,如同一幅水彩畫。爬取資料首先需要知道所需要抓取的資料是怎樣的呈現的,就像學作一幅畫,開始前你要知道這幅畫是用什麼畫出來的,鉛筆還是水彩筆…可能種類是多樣的,但是放到網頁資訊來說這兒只有兩種呈現方式:
1、HTML
2、JSON
HTML是用來描述網頁的一種語言
JSON是一種輕量級的資料交換格式
爬取網頁資訊其實就是向網頁提出請求,伺服器就會將資料反饋給你
2.獲得動態載入原始碼
匯入需要的用的模組和庫:
from bs4 import BeautifulSoup
import time
import def_text_save as dts
import def_get_data as dgd
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.action_chains import ActionChains #引入ActionChains滑鼠操作類獲取網頁資訊需要傳送請求,requests能幫我們很好的完成這件事,但是仔細觀察發現網易新聞是動態載入,requests返回的是即時資訊,網頁部分稍後加載出來的資料沒有返回,這種情況selenium能夠幫助我們得到更多的資料,我們將selenium理解為一個自動化測試工具就好,Selenium測試直接執行在瀏覽器中,就像真正的使用者在操作一樣。
我使用的瀏覽器為Firefox
browser = webdriver.Firefox()#根據瀏覽器切換
browser.maximize_window()#最大化視窗
browser.get('http://news.163.com/domestic/')這樣我們就能驅動瀏覽器自動登陸網易新聞頁面,
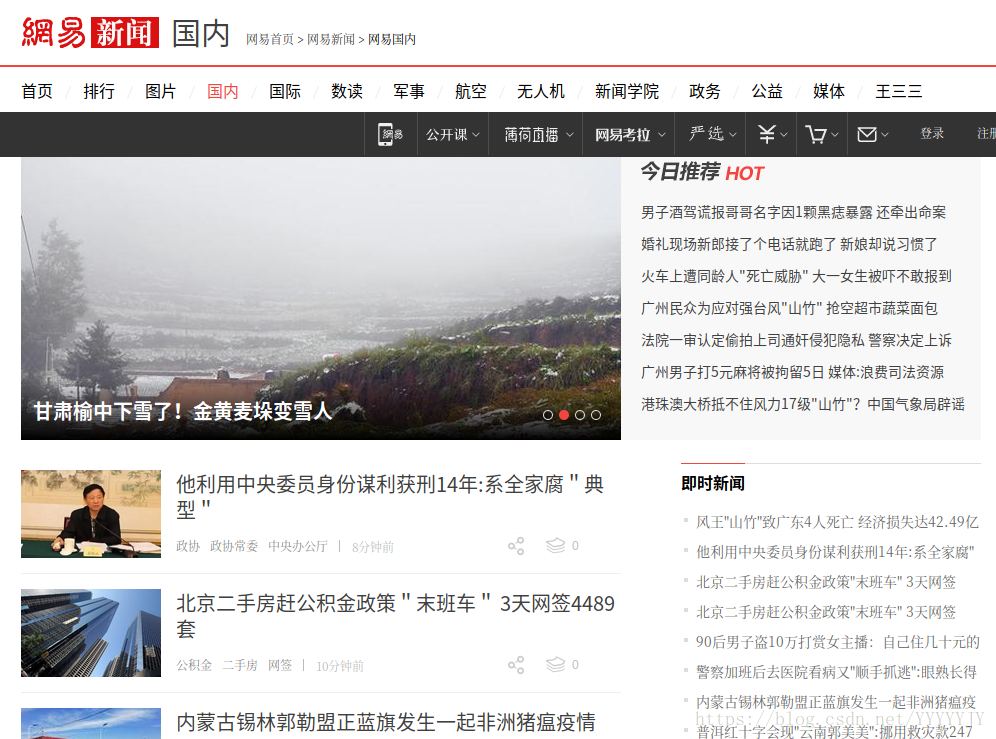
我們的目標自然是一次將國內板塊爬取下來,觀察網頁,在網頁不斷向下刷時,新的新聞才會加載出來,到最下面甚至還有需要點選按鈕才能重新整理:
這時使用selenium就能展現其優勢:自動化,模擬滑鼠鍵盤操作:
diver.execute_script("window.scrollBy(0,5000)")
#使網頁向下拉,括號內為每次下拉數值在網頁中右鍵點選載入更多按鈕,點選檢視元素,可以看到

通過這個class就可以定位到按鈕,碰到按鈕時,click事件就能幫助我們自動點選按鈕完成網頁重新整理
'''
爬取板塊動態載入部分原始碼
'''
info1=[]
info_links=[] #儲存文章內容連結
try:
while True :
if browser.page_source.find("load_more_btn") != -1 :
browser.find_element_by_class_name("load_more_btn").click()
browser.execute_script("window.scrollBy(0,5000)")
time.sleep(1)
except:
url = browser.page_source#返回載入完全的網頁原始碼
browser.close()#關閉瀏覽器3.獲取有用資訊
簡單來說,BeautifulSoup是python的一個庫,最主要的功能是從網頁抓取資料,能減輕菜鳥的負擔。
通過BeautifulSoup解析網頁原始碼,在加上附帶的函式,我們能輕鬆取出想要的資訊,例如:獲取文章標題,標籤以及文字內容超連結

同樣在文章標題區域右鍵點選檢視元素:
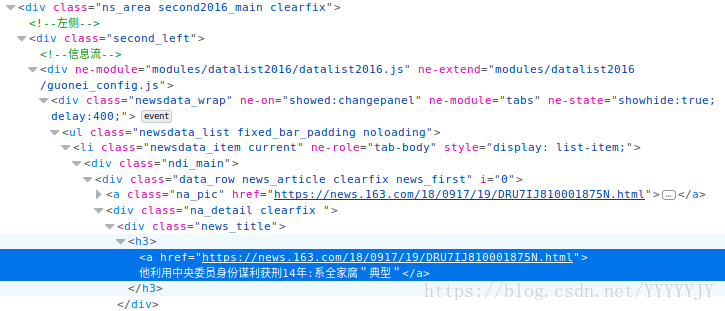
觀察網頁結構發現每一個div 標籤 class=“news_title” 下都是文章的標題和超連結。soup.find_all()函式能幫我們找到我們想要的全部資訊,這一級結構下的內容就能一次摘取出來。最後通過字典,把標籤資訊,挨個個取出來。
info_total=[]
def get_data(url):
soup=BeautifulSoup(url,"html.parser")
titles=soup.find_all('div','news_title')
labels=soup.find('div','ns_area second2016_main clearfix').find_all('div','keywords')
for title, label in zip(titles,labels ):
data = {
'文章標題': title.get_text().split(),
'文章標籤':label.get_text().split() ,
'link':title.find("a").get('href')
}
info_total.append(data)
return info_total4.獲取新聞內容
自此,新聞連結已經被我們取出來存到列表裡了,現在需要做的就是利用連結得到新聞主題內容。新聞主題內容頁面為靜態載入方式,requests能輕鬆處理:
def get_content(url):
info_text = []
info=[]
adata=requests.get(url)
soup=BeautifulSoup(adata.text,'html.parser')
try :
articles = soup.find("div", 'post_header').find('div', 'post_content_main').find('div', 'post_text').find_all('p')
except :
articles = soup.find("div", 'post_content post_area clearfix').find('div', 'post_body').find('div', 'post_text').find_all(
'p')
for a in articles:
a=a.get_text()
a= ' '.join(a.split())
info_text.append(a)
return (info_text)使用 try except的原因在於,網易新聞文章在某個時間段前後,文字資訊所處位置標籤不一樣,對不同的情況應作出不同的處理。
最後遍歷整個列表取出全部文字內容:
for i in info1 :
info_links.append(i.get('link'))
x=0 #控制訪問文章目錄
info_content={}# 儲存文章內容
for i in info_links:
try :
info_content['文章內容']=dgd.get_content(i)
except:
continue
s=str(info1[x]["文章標題"]).replace('[','').replace(']','').replace("'",'').replace(',','').replace('《','').replace('》','').replace('/','').replace(',',' ')
s= ''.join(s.split())
file = '/home/lsgo18/PycharmProjects/網易新聞'+'/'+s
print(s)
dts.text_save(file,info_content['文章內容'],info1[x]['文章標籤'])
x = x + 15.儲存資料到本地txt檔案
python提供了處理檔案的函式open(),第一個引數為檔案路徑,第二為檔案處理模式,”w“模式為只寫(不存在檔案則建立,存在則清空內容)
def text_save(filename, data,lable): #filename為寫入CSV檔案的路徑
file = open(filename,'w')
file.write(str(lable).replace('[','').replace(']','')+'\n')
for i in range(len(data)):
s =str(data[i]).replace('[','').replace(']','')#去除[],這兩行按資料不同,可以選擇
s = s.replace("'",'').replace(',','') +'\n' #去除單引號,逗號,每行末尾追加換行符
file.write(s)
file.close()
print("儲存檔案成功")一個簡單的爬蟲至此就編寫成功:
*———————————————————————————————————————*
歡迎交流指導:
LSGO軟體技術團隊
