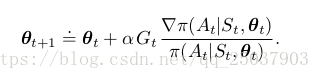強化學習(RLAI)讀書筆記第十三章策略梯度方法(Policy Gradient Methods)
強化學習(RLAI)讀書筆記第十三章策略梯度方法(Policy Gradient Methods)
目前為止本書講述的方法基本都是動作值函式的方法。這一章介紹一個學習引數化策略的方法,這個方法中不需要考慮值函式就可以得到策略。在學習策略引數的時候有可能還會用到值函式,但是選擇動作的時候不需要。使用了一個 作為策略的引數向量,然後用 來表示時間t時選擇動作a時的概率。這一章考慮一個使用 表示的度量函式的梯度來學習策略引數的演算法。
這個方法是來最大化
的,因此引數的更新近似對於J的梯度上升:
,
對於所有滿足此類更新形式的演算法,不論是否計算值函式都叫做policy gradient methods。那些同時計算策略函式和值函式的方法又叫做actor-critic演算法,actor表示學好的策略,而critic表示學好的值函式。
13.1 Policy Approximation and its Advantages
對於策略梯度演算法,策略可以被任意的引數化,只要最後的函式 是一個對於其引數可微的函式。這實際上要求學出來的演算法不能使確定性的。
對於那些離散且不大的動作空間,一個簡單常用的引數化方法是對於每一個狀態動作對都構造一個引數化數值 作為其優先順序的表示。對於比較高優先值的動作選擇的概率就比較大,比如可以根據如下指數softmax的分佈:
這個形式的策略引數化我們叫做動作優先值的soft-max。動作優先值可以被任意地引數化。比如可以直接使用一個神經網路來逼近,或者只使用簡單的線性特徵的形式:
引數化策略的方法一大優勢是可以逼近確定性策略,而對於建立在值函式之上的 -greedy演算法來說不可能做到,因為總要對非最優動作分配 部分的概率。
引數化策略第二個優勢是可以支援對於動作任意分配概率。某些問題裡可能採取任意的動作才是最優的。基於動作值函式的策略就不能自然地支援這一功能。
第三個優勢是某些問題裡策略可能是一個更簡單的函式近似的物件。最後一個優勢是策略的引數化有時是強化學習演算法裡注入關於目標策略的先驗知識的方法。
13.2 The Policy Gradient Theorem
引數化策略相對於 演算法除了實用的優勢之外,還有這一個重要的理論優勢。對於連續的引數化策略,動作概率作為一個已學習引數的函式是連續變化的,不像是 有可能是突變。可能主要因為這個特點所以policy-gradient方法有著更強的收斂特性。特別是策略對於引數的連續性使得這個方法能夠逼近梯度上升演算法。
這一節我們考慮episodic形式的任務,我們定義策略的效能為從起始狀態開始的反饋,即:
這裡把discounting引數
設為1。
使用了函式逼近之後,把策略引數往保證策略更好的方向改變看起來有些困難。問題在於策略的效能依賴於動作的選擇以及在選擇動作時依賴的狀態分佈。這兩個部分都被策略引數影響。對於一個狀態,策略引數對於動作和獎勵的影響可以通過引數直接計算出來。但是策略對於狀態分佈的影響是有關環境的函式而且一般不知道。我們沒有辦法計算出一個有關於策略改變對於狀態分佈的影響的梯度。因為這個影響是未知的。
但是幸運的是,對於這個問題有一個完美的理論答案,叫做policy gradient theorem,書上有推導。它為效能函式J相對於策略引數的梯度提供瞭解析表達。表明了這個梯度與狀態分佈的求導無關。episodic形式的policy gradient theorem推匯出:
。
13.3 REINFORCE: Monte Carlo Policy Gradient
現在考慮推匯出第一個policy-gradient的學習演算法。policy gradient theorem的右端是一個根據目標策略
下狀態分佈進行的加權求和。只要遵循策略
那麼這些狀態就會根據這個分佈的比例被訪問。於是推導得:
在這裡我們可以把隨機梯度上升法寫作
這個演算法叫做all-actions方法,因為它的更新包含了所有動作,是很有前景並且值得研究的,不過目前我們的演算法只關注當前動作
。
通過進一步的推導,我們可以繼續將上式推導為以下形式:
最後一個等式括號裡的正式我們所要的。因此使用這個式子的一個取樣來作為我們泛型演算法的一個例項的REINFORCE update:
這個更新是有其內部邏輯的。每次增量都正比於反饋估計值