
公開課機器學習筆記(7)Softmax迴歸模型
在本節中,我們介紹Softmax迴歸模型,該模型是logistic迴歸模型在多分類問題上的推廣,在多分類問題中,類標籤  可以取兩個以上的值。 Softmax迴歸模型對於諸如MNIST手寫數字分類等問題是很有用的,該問題的目的是辨識10個不同的單個數字。Softmax迴歸是有監督的,不過後面也會介紹它與深度學習/無監督學習方法的結合。(譯者注:
MNIST 是一個手寫數字識別庫,由NYU 的Yann LeCun 等人維護。http://yann.lecun.com/exdb/mnist/ )
可以取兩個以上的值。 Softmax迴歸模型對於諸如MNIST手寫數字分類等問題是很有用的,該問題的目的是辨識10個不同的單個數字。Softmax迴歸是有監督的,不過後面也會介紹它與深度學習/無監督學習方法的結合。(譯者注:
MNIST 是一個手寫數字識別庫,由NYU 的Yann LeCun 等人維護。http://yann.lecun.com/exdb/mnist/ )
回想一下在 logistic 迴歸中,我們的訓練集由 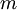 個已標記的樣本構成:
個已標記的樣本構成: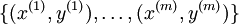 ,其中輸入特徵
,其中輸入特徵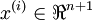 。(我們對符號的約定如下:特徵向量
。(我們對符號的約定如下:特徵向量 
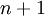 ,其中
,其中 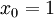 對應截距項
。) 由於 logistic 迴歸是針對二分類問題的,因此類標記
對應截距項
。) 由於 logistic 迴歸是針對二分類問題的,因此類標記 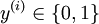 。假設函式(hypothesis function) 如下:
。假設函式(hypothesis function) 如下:
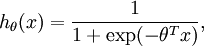
我們將訓練模型引數  ,使其能夠最小化代價函式 :
,使其能夠最小化代價函式 :
![\begin{align}J(\theta) = -\frac{1}{m} \left[ \sum_{i=1}^m y^{(i)} \log h_\theta(x^{(i)}) + (1-y^{(i)}) \log (1-h_\theta(x^{(i)})) \right]\end{align}](http://ufldl.stanford.edu/wiki/images/math/f/a/6/fa6565f1e7b91831e306ec404ccc1156.png)
在 softmax迴歸中,我們解決的是多分類問題(相對於 logistic 迴歸解決的二分類問題),類標 可以取  個不同的值(而不是
2 個)。因此,對於訓練集 ,我們有
個不同的值(而不是
2 個)。因此,對於訓練集 ,我們有 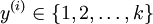 。(注意此處的類別下標從
1 開始,而不是 0)。例如,在 MNIST 數字識別任務中,我們有
。(注意此處的類別下標從
1 開始,而不是 0)。例如,在 MNIST 數字識別任務中,我們有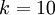 個不同的類別。
個不同的類別。
對於給定的測試輸入 ,我們想用假設函式針對每一個類別j估算出概率值 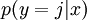 。也就是說,我們想估計
。也就是說,我們想估計
維的向量(向量元素的和為1)來表示這 個估計的概率值。
具體地說,我們的假設函式 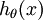 形式如下:
形式如下:
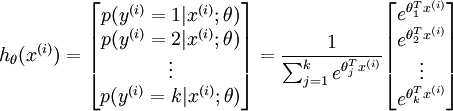
其中 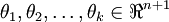 是模型的引數。請注意
是模型的引數。請注意 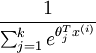 這一項對概率分佈進行歸一化,使得所有概率之和為
1 。
這一項對概率分佈進行歸一化,使得所有概率之和為
1 。
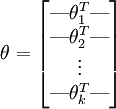
為了方便起見,我們同樣使用符號 來表示全部的模型引數。在實現Softmax迴歸時,將 用一個 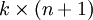 的矩陣來表示會很方便,該矩陣是將
的矩陣來表示會很方便,該矩陣是將 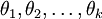 按行羅列起來得到的,如下所示:
按行羅列起來得到的,如下所示:
代價函式
現在我們來介紹 softmax 迴歸演算法的代價函式。在下面的公式中,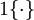 是示性函式,其取值規則為:
是示性函式,其取值規則為:
值為真的表示式
, 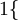 值為假的表示式
值為假的表示式 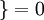 。舉例來說,表示式
。舉例來說,表示式 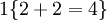
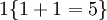 的值為 0。我們的代價函式為:
的值為 0。我們的代價函式為:
![\begin{align}J(\theta) = - \frac{1}{m} \left[ \sum_{i=1}^{m} \sum_{j=1}^{k} 1\left\{y^{(i)} = j\right\} \log \frac{e^{\theta_j^T x^{(i)}}}{\sum_{l=1}^k e^{ \theta_l^T x^{(i)} }}\right]\end{align}](http://ufldl.stanford.edu/wiki/images/math/7/6/3/7634eb3b08dc003aa4591a95824d4fbd.png)
值得注意的是,上述公式是logistic迴歸代價函式的推廣。logistic迴歸代價函式可以改為:
![\begin{align}J(\theta) &= -\frac{1}{m} \left[ \sum_{i=1}^m (1-y^{(i)}) \log (1-h_\theta(x^{(i)})) + y^{(i)} \log h_\theta(x^{(i)}) \right] \\&= - \frac{1}{m} \left[ \sum_{i=1}^{m} \sum_{j=0}^{1} 1\left\{y^{(i)} = j\right\} \log p(y^{(i)} = j | x^{(i)} ; \theta) \right]\end{align}](http://ufldl.stanford.edu/wiki/images/math/5/4/9/5491271f19161f8ea6a6b2a82c83fc3a.png)
可以看到,Softmax代價函式與logistic 代價函式在形式上非常類似,只是在Softmax損失函式中對類標記的 個可能值進行了累加。注意在Softmax迴歸中將 分類為類別  的概率為:
的概率為:
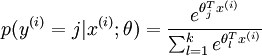 .
.
對於  的最小化問題,目前還沒有閉式解法。因此,我們使用迭代的優化演算法(例如梯度下降法,或 L-BFGS)。經過求導,我們得到梯度公式如下:
的最小化問題,目前還沒有閉式解法。因此,我們使用迭代的優化演算法(例如梯度下降法,或 L-BFGS)。經過求導,我們得到梯度公式如下:
![\begin{align}\nabla_{\theta_j} J(\theta) = - \frac{1}{m} \sum_{i=1}^{m}{ \left[ x^{(i)} \left( 1\{ y^{(i)} = j\} - p(y^{(i)} = j | x^{(i)}; \theta) \right) \right] }\end{align}](http://ufldl.stanford.edu/wiki/images/math/5/9/e/59ef406cef112eb75e54808b560587c9.png)
讓我們來回顧一下符號 "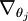 " 的含義。
" 的含義。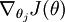 本身是一個向量,它的第
本身是一個向量,它的第  個元素
個元素 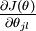 是 對
是 對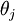 的第 個分量的偏導數。
的第 個分量的偏導數。
有了上面的偏導數公式以後,我們就可以將它代入到梯度下降法等演算法中,來最小化 。 例如,在梯度下降法的標準實現中,每一次迭代需要進行如下更新: (
(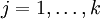 )。
)。
當實現 softmax 迴歸演算法時, 我們通常會使用上述代價函式的一個改進版本。具體來說,就是和權重衰減(weight decay)一起使用。我們接下來介紹使用它的動機和細節。
Softmax迴歸模型引數化的特點
Softmax 迴歸有一個不尋常的特點:它有一個“冗餘”的引數集。為了便於闡述這一特點,假設我們從引數向量 中減去了向量 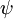 ,這時,每一個 都變成了
,這時,每一個 都變成了 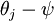 ()。此時假設函式變成了以下的式子:
()。此時假設函式變成了以下的式子:
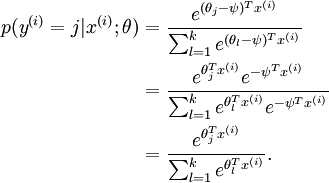
換句話說,從 中減去 完全不影響假設函式的預測結果!這表明前面的
softmax 迴歸模型中存在冗餘的引數。更正式一點來說, Softmax 模型被過度引數化了。對於任意一個用於擬合數據的假設函式,可以求出多組引數值,這些引數得到的是完全相同的假設函式 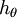 。
。
進一步而言,如果引數 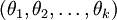 是代價函式 的極小值點,那麼
是代價函式 的極小值點,那麼 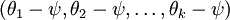 同樣也是它的極小值點,其中 可以為任意向量。因此使 最小化的解不是唯一的。(有趣的是,由於 仍然是一個凸函式,因此梯度下降時不會遇到區域性最優解的問題。但是
Hessian 矩陣是奇異的/不可逆的,這會直接導致採用牛頓法優化就遇到數值計算的問題)
同樣也是它的極小值點,其中 可以為任意向量。因此使 最小化的解不是唯一的。(有趣的是,由於 仍然是一個凸函式,因此梯度下降時不會遇到區域性最優解的問題。但是
Hessian 矩陣是奇異的/不可逆的,這會直接導致採用牛頓法優化就遇到數值計算的問題)
注意,當 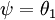 時,我們總是可以將
時,我們總是可以將 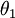 替換為
替換為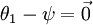 (即替換為全零向量),並且這種變換不會影響假設函式。因此我們可以去掉引數向量 (或者其他 中的任意一個)而不影響假設函式的表達能力。實際上,與其優化全部的 個引數 (其中
(即替換為全零向量),並且這種變換不會影響假設函式。因此我們可以去掉引數向量 (或者其他 中的任意一個)而不影響假設函式的表達能力。實際上,與其優化全部的 個引數 (其中 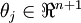 ),我們可以令
),我們可以令 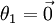 ,只優化剩餘的
,只優化剩餘的 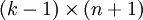 個引數,這樣演算法依然能夠正常工作。
個引數,這樣演算法依然能夠正常工作。
在實際應用中,為了使演算法實現更簡單清楚,往往保留所有引數 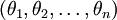 ,而不任意地將某一引數設定為
0。但此時我們需要對代價函式做一個改動:加入權重衰減。權重衰減可以解決 softmax 迴歸的引數冗餘所帶來的數值問題。
,而不任意地將某一引數設定為
0。但此時我們需要對代價函式做一個改動:加入權重衰減。權重衰減可以解決 softmax 迴歸的引數冗餘所帶來的數值問題。
權重衰減
我們通過新增一個權重衰減項 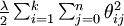 來修改代價函式,這個衰減項會懲罰過大的引數值,現在我們的代價函式變為:
來修改代價函式,這個衰減項會懲罰過大的引數值,現在我們的代價函式變為:
![\begin{align}J(\theta) = - \frac{1}{m} \left[ \sum_{i=1}^{m} \sum_{j=1}^{k} 1\left\{y^{(i)} = j\right\} \log \frac{e^{\theta_j^T x^{(i)}}}{\sum_{l=1}^k e^{ \theta_l^T x^{(i)} }} \right] + \frac{\lambda}{2} \sum_{i=1}^k \sum_{j=0}^n \theta_{ij}^2\end{align}](http://ufldl.stanford.edu/wiki/images/math/4/7/1/471592d82c7f51526bb3876c6b0f868d.png)
有了這個權重衰減項以後 (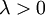 ),代價函式就變成了嚴格的凸函式,這樣就可以保證得到唯一的解了。 此時的 Hessian矩陣變為可逆矩陣,並且因為是凸函式,梯度下降法和
L-BFGS 等演算法可以保證收斂到全域性最優解。
),代價函式就變成了嚴格的凸函式,這樣就可以保證得到唯一的解了。 此時的 Hessian矩陣變為可逆矩陣,並且因為是凸函式,梯度下降法和
L-BFGS 等演算法可以保證收斂到全域性最優解。
為了使用優化演算法,我們需要求得這個新函式 的導數,如下:
![\begin{align}\nabla_{\theta_j} J(\theta) = - \frac{1}{m} \sum_{i=1}^{m}{ \left[ x^{(i)} ( 1\{ y^{(i)} = j\} - p(y^{(i)} = j | x^{(i)}; \theta) ) \right] } + \lambda \theta_j\end{align}](http://ufldl.stanford.edu/wiki/images/math/3/a/f/3afb4b9181a3063ddc639099bc919197.png)
通過最小化 ,我們就能實現一個可用的 softmax 迴歸模型。
Softmax迴歸與Logistic 迴歸的關係
當類別數 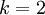 時,softmax 迴歸退化為 logistic 迴歸。這表明 softmax 迴歸是 logistic 迴歸的一般形式。具體地說,當 時,softmax
迴歸的假設函式為:
時,softmax 迴歸退化為 logistic 迴歸。這表明 softmax 迴歸是 logistic 迴歸的一般形式。具體地說,當 時,softmax
迴歸的假設函式為:
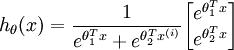
利用softmax迴歸引數冗餘的特點,我們令 ,並且從兩個引數向量中都減去向量 ,得到:
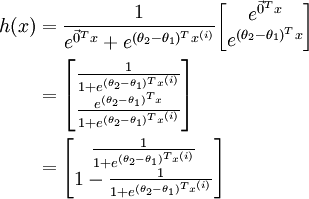
因此,用 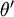 來表示
來表示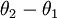 ,我們就會發現
softmax 迴歸器預測其中一個類別的概率為
,我們就會發現
softmax 迴歸器預測其中一個類別的概率為 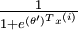 ,另一個類別概率的為
,另一個類別概率的為  ,這與
logistic迴歸是一致的。
,這與
logistic迴歸是一致的。
Softmax 迴歸 vs. k 個二元分類器
如果你在開發一個音樂分類的應用,需要對k種類型的音樂進行識別,那麼是選擇使用 softmax 分類器呢,還是使用 logistic 迴歸演算法建立 k 個獨立的二元分類器呢?
這一選擇取決於你的類別之間是否互斥,例如,如果你有四個類別的音樂,分別為:古典音樂、鄉村音樂、搖滾樂和爵士樂,那麼你可以假設每個訓練樣本只會被打上一個標籤(即:一首歌只能屬於這四種音樂型別的其中一種),此時你應該使用類別數 k = 4 的softmax迴歸。(如果在你的資料集中,有的歌曲不屬於以上四類的其中任何一類,那麼你可以新增一個“其他類”,並將類別數 k 設為5。)
如果你的四個類別如下:人聲音樂、舞曲、影視原聲、流行歌曲,那麼這些類別之間並不是互斥的。例如:一首歌曲可以來源於影視原聲,同時也包含人聲 。這種情況下,使用4個二分類的 logistic 迴歸分類器更為合適。這樣,對於每個新的音樂作品 ,我們的演算法可以分別判斷它是否屬於各個類別。
現在我們來看一個計算視覺領域的例子,你的任務是將影象分到三個不同類別中。(i) 假設這三個類別分別是:室內場景、戶外城區場景、戶外荒野場景。你會使用sofmax迴歸還是 3個logistic 迴歸分類器呢? (ii) 現在假設這三個類別分別是室內場景、黑白圖片、包含人物的圖片,你又會選擇 softmax 迴歸還是多個 logistic 迴歸分類器呢?
在第一個例子中,三個類別是互斥的,因此更適於選擇softmax迴歸分類器 。而在第二個例子中,建立三個獨立的 logistic迴歸分類器更加合適。
相關推薦
公開課機器學習筆記(7)Softmax迴歸模型
在本節中,我們介紹Softmax迴歸模型,該模型是logistic迴歸模型在多分類問題上的推廣,在多分類問題中,類標籤 可以取兩個以上的值。 Softmax迴歸模型對於諸如MNIST手寫數字分類等問題是很有用的,該問題的目的是辨識10個不同的單個數字。Softmax迴歸
公開課機器學習筆記(13)支援向量機三 核函式
2.2、核函式Kernel 2.2.1、特徵空間的隱式對映:核函式 咱們首先給出核函式的來頭:在上文中,我們已經瞭解到了SVM處理線性可分的情況,而對於非線性的情況,SVM 的處理方法是選擇一個核函式 κ(⋅,⋅) ,通過將資料對映到高維空間,來解決在原始空
斯坦福大學深度學習公開課cs231n學習筆記(1)softmax函式理解與應用
<div id="article_content" class="article_content clearfix csdn-tracking-statistics" data-pid="blog" data-mod="popu_307" data-dsm="post"
機器學習筆記(一)線性迴歸模型
一、線性迴歸模型 (一)引入—梯度下降演算法 1. 線性假設: 2. 方差代價函式: 3. 梯度下降: 4. : learning rate (用來控制我們在梯度下降時邁出多大的步子,值較大,梯度下降就很迅速) 值過大易造成無法收斂到minimum(每一步邁更大)
機器學習筆記(三)Logistic迴歸模型
Logistic迴歸模型 1. 模型簡介: 線性迴歸往往並不能很好地解決分類問題,所以我們引出Logistic迴歸演算法,演算法的輸出值或者說預測值一直介於0和1,雖然演算法的名字有“迴歸”二字,但實際上Logistic迴歸是一種分類演算法(classification y = 0 or 1)。 Log
TensorFlow學習筆記(一)-- Softmax迴歸模型識別MNIST
最近學習Tensorflow,特此筆記,學習資料為21個專案玩轉深度學習 基於TensorFlow的實踐詳解 Softmax迴歸是一個線性的多分類模型,它是從Logistic迴歸模型轉化而來的,不同的是Logistic迴歸模型是一個二分類模型,而Softmax迴歸模型是一個多分類模型
Khan公開課 - 統計學學習筆記 (二)總本 樣本 集中趨勢 離中趨勢
分享一下我老師大神的人工智慧教程!零基礎,通俗易懂!http://blog.csdn.net/jiangjunshow 也歡迎大家轉載本篇文章。分享知識,造福人民,實現我們中華民族偉大復興!
斯坦福大學深度學習公開課cs231n學習筆記(10)卷積神經網路
前記:20世紀60年代,Hubel和Wiesel在研究貓腦皮層中用於區域性敏感和方向選擇的神經元時,發現其獨特的網路結構可以有效地降低反饋神經網路的複雜性,繼而提出了卷積神經網路(Convolutio
機器學習筆記(7)——C4.5決策樹中的缺失值處理
缺失值處理是C4.5決策樹演算法中的又一個重要部分,前面已經討論過連續值和剪枝的處理方法: 現實任務中,通常會遇到大量不完整的樣本,如果直接放棄不完整樣本,對資料是極大的浪費,例如下面這個有缺失值的西瓜樣本集,只有4個完整樣本。 在構造決策樹時,處理含有缺失值
機器學習筆記(二)線性迴歸實現
一、向量化 對於大量的求和運算,向量化思想往往能提高計算效率(利用線性代數運算庫),無論我們在使用MATLAB、Java等任何高階語言來編寫程式碼。 運算思想及程式碼對比 的同步更新過程向量化 向量化後的式子表示成為: 其中是一個向量,是一個實數,是一個向量,
吳恩達深度學習筆記(7)--邏輯迴歸的代價函式(Cost Function)
邏輯迴歸的代價函式(Logistic Regression Cost Function) 在上一篇文章中,我們講了邏輯迴歸模型,這裡,我們講邏輯迴歸的代價函式(也翻譯作成本函式)。 吳恩達讓我轉達大家:這一篇有很多公式,做好準備,睜大眼睛!代價函式很重要! 為什麼需要代價函式: 為
機器學習筆記(四)Logistic迴歸實現及正則化
一、Logistic迴歸實現 (一)特徵值較少的情況 1. 實驗資料 吳恩達《機器學習》第二課時作業提供資料1。判斷一個學生能否被一個大學錄取,給出的資料集為學生兩門課的成績和是否被錄取,通過這些資料來預測一個學生能否被錄取。 2. 分類結果評估 橫縱軸(特徵)為學生兩門課成績,可以在圖
深入理解JAVA虛擬機器學習筆記(一)JVM記憶體模型
一、JVM記憶體模型概述 JVM記憶體模型其實也挺簡單的,這裡先提2個知識點: 1、組成:java堆,java棧(即虛擬機器棧),本地方法棧,方法區和程式計數器。 2、是否共享:其中方法區和堆區是執行緒共享的,虛擬機器棧,本地方法棧和程式計數器是執行緒私有的,也稱執行緒
機器學習筆記(二):線性模型
線性模型是機器學習常用的眾多模型中最簡單的模型,但卻蘊含著機器學習中一些重要的基本思想。許多功能更為強大的非線性模型可線上性模型的基礎上通過引入層級結構或高維對映得到,因此瞭解線性模型對學習其他機器學習模型具有重要意義。 本文主要介紹機器學習中常用的線性模型,內
機器學習筆記(五)—— 邏輯迴歸
邏輯迴歸演算法是二分類問題中最常用的幾種分類演算法之一,通過變形,也能夠在多分類問題中發揮餘熱。今天我將從向大家揭開這個簡單演算法的神祕面紗! 一、Sigmoid函式 在迴歸問題中,我們曾經提到,對於資料集
機器學習筆記(四)Logistic迴歸
我們都知道,如果預測值y是個連續的值,我們通常用迴歸的方法去預測,但如果預測值y是個離散的值,也就是所謂的分類問題,用線性迴歸肯定是不合理的,因為你預測的值沒有一個合理的解釋啊。比如對於二分類問題,我
機器學習筆記(一)邏輯迴歸與多項邏輯迴歸
1.邏輯迴歸與多項邏輯迴歸 1.1什麼是邏輯迴歸? 邏輯迴歸,可以說是線上性迴歸的基礎上加上一個sigmoid函式,將線性迴歸產生的值歸一化到[0-1]區間內。sigmoid函式如下:
斯坦福大學公開課機器學習課程(Andrew Ng)五生成學習演算法
課程概要: 1.生成學習演算法(Generative learning algorithm) 2.高斯判別分析(GDA,Gaussian Discriminant Analysis) 3.GDA與logistic模型的聯絡 4.樸素貝葉斯(Naive Bayes) 5.
斯坦福大學公開課機器學習課程(Andrew Ng)四牛頓方法與廣義線性模型
本次課所講主要內容: 1、 牛頓方法:對Logistic模型進行擬合 2、 指數分佈族 3、 廣義線性模型(GLM):聯絡Logistic迴歸和最小二乘模型 一、牛頓方法 牛頓方法與梯度下降法的功能一樣,都是對解空間進行搜尋的方法。 假設有函
Stanford公開課機器學習---week2-1.多變數線性迴歸 (Linear Regression with multiple variable)
3.多變數線性迴歸 (Linear Regression with multiple variable) 3.1 多維特徵(Multiple Features) n 代表特徵的數量 x(i)代表第 i 個訓練例項,是特徵矩陣中的第 i 行,是一個向