LDA學習小記
大部分對LDA的解釋都是通過LDA生成文件的思路,而我們一般是給定文件,利用LDA推測該文件的話題分佈。我在這裡先講一下生成文件的過程,再講我們普遍用到的程式碼中推測話題的過程:
1.文件生成
我比較關注實用性,又不是很喜歡那麼多的數學公式,所以主要先把個人感覺最方便理解的解釋分享給大家看看~反正我看了下邊的解釋腦子裡可以有LDA原理的整個思路。
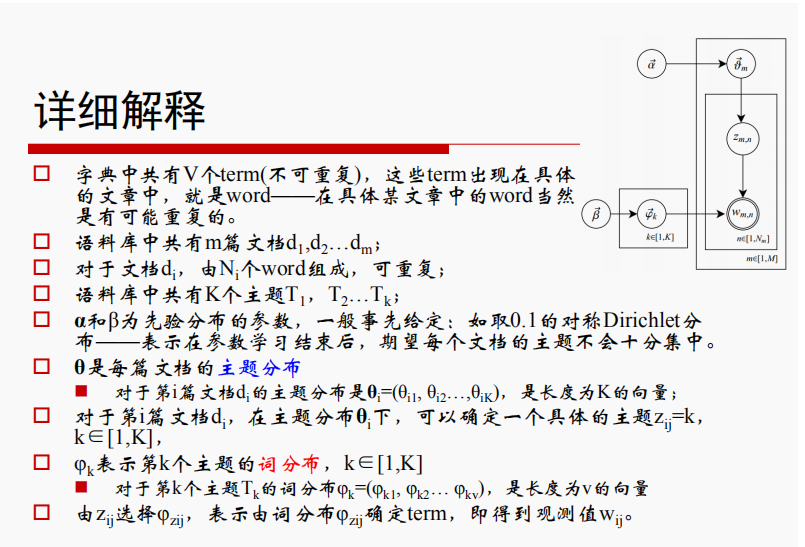
聯絡右上角給出的圖,步驟為從上到下、從左到右,先得到一個主題Zij=k,再得到第k個主題的詞分佈φk,繼而生成文件的詞彙w,迴圈該圖流程,生成整篇文件。
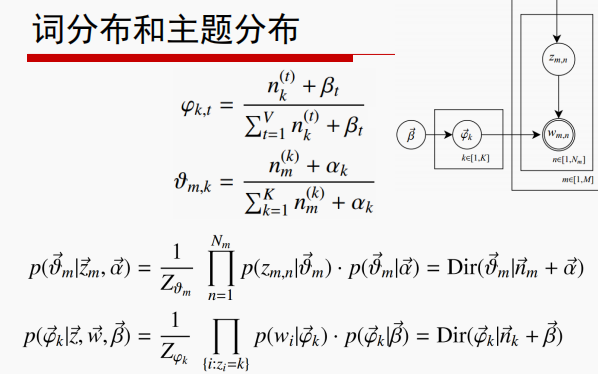
過程中涉及到多種分佈;
共軛分佈:在貝葉斯的理論體系中,如果先驗概率分佈和後驗概率分佈滿足同樣的分佈律的話,就說先驗分佈和後驗分佈是共軛分佈,同時,先驗分佈又叫做似然函式的共軛先驗分佈。大白話來說就是:如果一個概率分佈Z乘以一個分佈Y之後的分佈仍然是Z,那麼就是共軛分佈。二項分佈的共軛先驗分佈是Beta分佈,多項分佈的共軛先驗分佈是Dirichlet分佈。
LDA中涉及的 多項分佈和Dirichlet分佈,LDA中詞和主題服從多項式分佈,兩者的引數服從Dirichlet分佈。我認為引入共軛分佈主要是為了方便計算整個過程中的引數。
2.通過已知文件推測所含話題分佈
通過LDA推測話題分佈時,
1)初始先隨機給文字中的每個詞(喂進去的詞需要經過分詞、通過dictionary每個詞對應一個id,再將id與該詞對應的tf-idf值或詞頻關聯儲存為一個矩陣)分配主題z0(初始設定了要得到的話題個數k,為每個詞分配話題id),也給定了α和β,控制了主題分佈和詞分佈;
2)然後統計詞t屬於主題z的數量以及每個文件m下出現的主題z的數量;通過除了當前詞w以外其他所有詞所屬的主題分佈估計當前詞分配各個主題的概率,即計算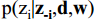
3)當得到當前詞屬於所有主題z的概率分佈後,根據這個概率分佈為該詞采樣(不是取最大值)一個新的主題。
4)用同樣方法更新下一個詞的主題,直到發現每個文件的主題分佈和每個主題的詞分佈收斂(應該是文件中出現的所有同一個詞計算得到的所屬主題分佈都一致),演算法終止,輸出待估計的引數θ和φ,同時每個單詞的主題Zmn也可以得到。
實際中應用會設定最大迭代次數,每一次計算
 的公式稱為Gibbs updating rule
的公式稱為Gibbs updating rule這樣就解釋了內部推測話題的過程。其中涉及的數學計算過程如下(我比較懶,直接貼了鄒博視訊的式子啦,如果對大家有用希望能點個贊之類的啦~~~~~~~~~