
【Python例項第7講】真實資料集的異常檢測
阿新 • • 發佈:2018-11-09
機器學習訓練營——機器學習愛好者的自由交流空間(qq 群號:696721295)
在這個例子裡,我們闡述在真實資料集上的穩健協方差估計的必要性。這樣的協方差估計,對異常點檢測,以及更好地理解資料結構都是有益的。
為了方便資料視覺化,我們選擇來自波士頓房價資料集的兩個變數組成的二維資料集作為示例資料集。在下面的例子裡,主要的結果是經驗協方差估計,它受觀測資料形態的影響很大。但是,我們仍然假設資料服從正態分佈。這可能產生有偏的結構估計,但在某種程度上仍然是準確的。
一個例子
這個例子闡述,當資料存在一個類時,穩健的協方差估計如何幫助確定另一個相關的類。這個例子裡的很多觀測,很難確定屬於同一個類,這給經驗協方差估計帶來了困難。當然,可以利用一些篩選工具,例如,支援向量機、高斯混合模型、單變數異常點檢測,確定資料裡存在兩個類。但是,當維數大於2時,這些工具很難奏效。
程式碼詳解
首先,載入必需的函式庫。
print(__doc__) # Author: Virgile Fritsch <[email protected]> # License: BSD 3 clause import numpy as np from sklearn.covariance import EllipticEnvelope from sklearn.svm import OneClassSVM import matplotlib.pyplot as plt import matplotlib.font_manager from sklearn.datasets import load_boston
取資料集裡的兩個變數,這兩個變數的觀測組成兩類。
X1 = load_boston()['data'][:, [8, 10]] # two clusters
定義要使用的分類器物件classifiers, 它是一個字典型,由Empirical Covariance, Robust Covariance, 單類支援向量機 OCSVM 三個分類器組成。
# Define "classifiers" to be used classifiers = { "Empirical Covariance": EllipticEnvelope(support_fraction=1., contamination=0.261), "Robust Covariance (Minimum Covariance Determinant)": EllipticEnvelope(contamination=0.261), "OCSVM": OneClassSVM(nu=0.261, gamma=0.05)} colors = ['m', 'g', 'b'] legend1 = {}
使用定義的三個分類器,確定異常點檢測邊界。
xx1, yy1 = np.meshgrid(np.linspace(-8, 28, 500), np.linspace(3, 40, 500))
for i, (clf_name, clf) in enumerate(classifiers.items()):
plt.figure(1)
clf.fit(X1)
Z1 = clf.decision_function(np.c_[xx1.ravel(), yy1.ravel()])
Z1 = Z1.reshape(xx1.shape)
legend1[clf_name] = plt.contour(
xx1, yy1, Z1, levels=[0], linewidths=2, colors=colors[i])
legend1_values_list = list(legend1.values())
legend1_keys_list = list(legend1.keys())
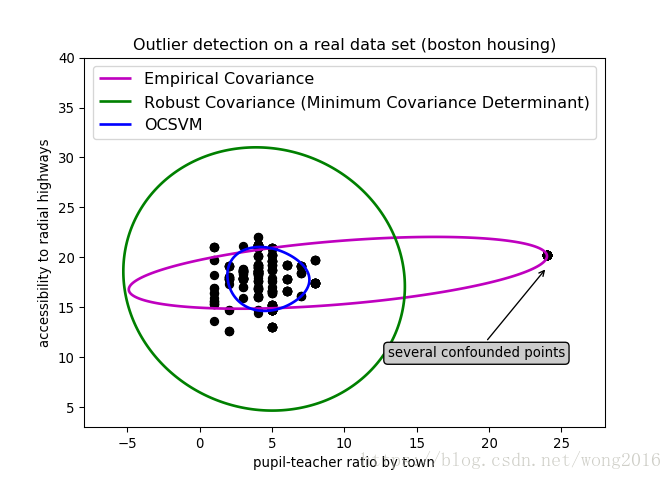
畫出結果圖,我們會看到一個明顯異常的觀測點。
plt.figure(1) # two clusters
plt.title("Outlier detection on a real data set (boston housing)")
plt.scatter(X1[:, 0], X1[:, 1], color='black')
bbox_args = dict(boxstyle="round", fc="0.8")
arrow_args = dict(arrowstyle="->")
plt.annotate("several confounded points", xy=(24, 19),
xycoords="data", textcoords="data",
xytext=(13, 10), bbox=bbox_args, arrowprops=arrow_args)
plt.xlim((xx1.min(), xx1.max()))
plt.ylim((yy1.min(), yy1.max()))
plt.legend((legend1_values_list[0].collections[0],
legend1_values_list[1].collections[0],
legend1_values_list[2].collections[0]),
(legend1_keys_list[0], legend1_keys_list[1], legend1_keys_list[2]),
loc="upper center",
prop=matplotlib.font_manager.FontProperties(size=12))
plt.ylabel("accessibility to radial highways")
plt.xlabel("pupil-teacher ratio by town")
plt.show()
閱讀更多精彩內容,請關注微信公眾號:統計學習與大資料