
網路爬蟲簡單的實現爬取百度貼吧圖片
我們要爬取的網站是https://tieba.baidu.com/p/3797994694
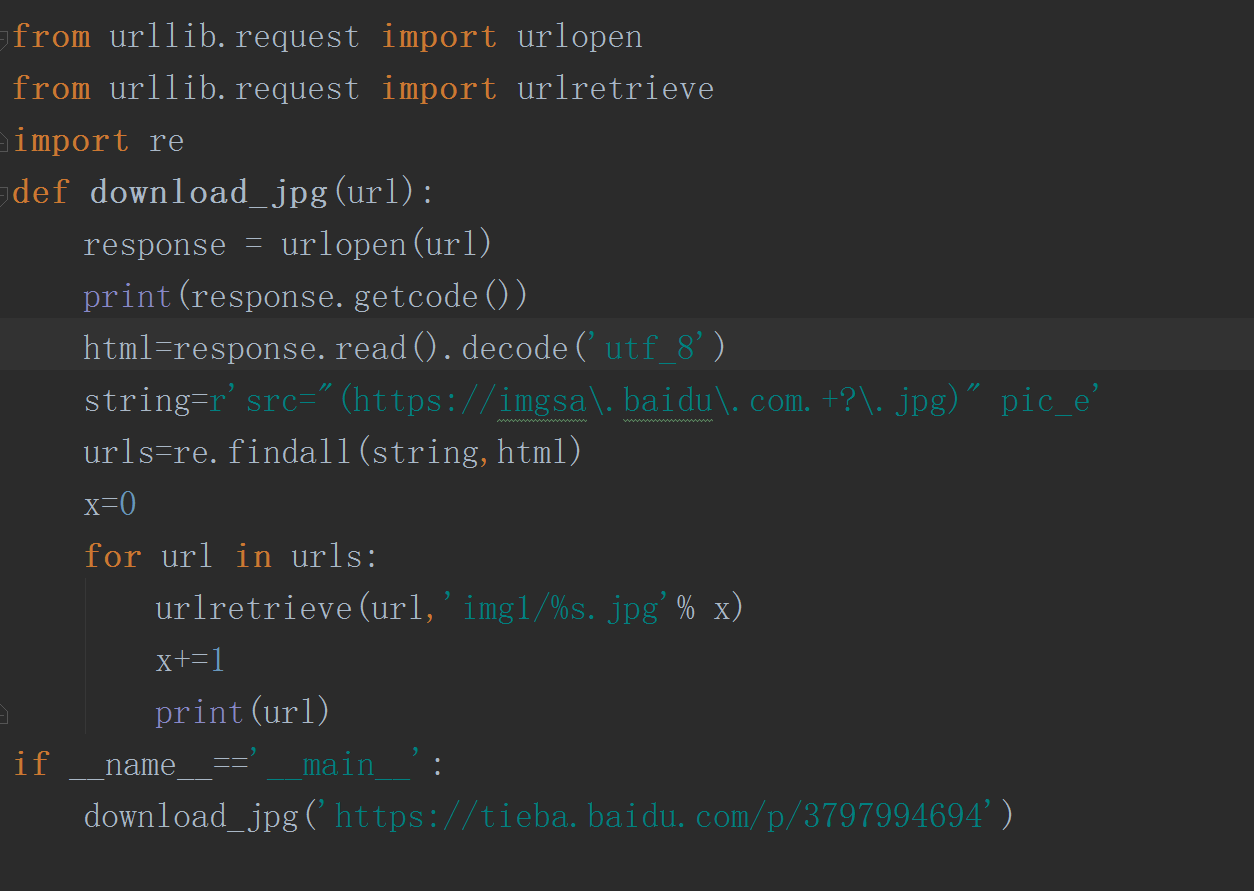
首先爬取第一頁的圖片,使用python3自帶庫urllib,詳細的程式碼如下:

相關推薦
網路爬蟲簡單的實現爬取百度貼吧圖片
我們要爬取的網站是https://tieba.baidu.com/p/3797994694 首先爬取第一頁的圖片,使用python3自帶庫urllib,詳細的程式碼如下: 接下來爬去多頁的圖片,這裡我們選取五頁的圖片,這裡我們採用requests,beautifuls
Python簡易爬蟲爬取百度貼吧圖片
decode works 接口 def 讀取 min baidu 得到 internal 通過python 來實現這樣一個簡單的爬蟲功能,把我們想要的圖片爬取到本地。(Python版本為3.6.0) 一.獲取整個頁面數據 def getHtml(url)
Python爬蟲教程:爬取百度貼吧
貼吧爬取 寫程式碼前,構思需要的功能塊;寫程式碼時,把各個功能模組名提前寫好 初始化 初始化必要引數,完成基礎設定 爬取百度貼吧lol吧:爬取地址中的get引數須傳遞(可以指定不同主題的貼吧和頁碼) 主題名 初始網址 請求頭 生成網址 生成每一頁的路由
實戰python 爬蟲爬取百度貼吧圖片
#!/usr/bin/python import urllib,urllib2import re def getHtml(url): page = urllib2.urlopen(url) return page.read() def getImage(html): re_img = re.compil
XPath:爬取百度貼吧圖片,並儲存本地
使用XPath,我們可以先將 HTML檔案 轉換成 XML文件,然後用 XPath 查詢 HTML 節點或元素。 什麼是XML XML 指可擴充套件標記語言(EXtensible Markup
爬取百度貼吧圖片
本次文章內容是爬取貼吧圖片,希望對大家有所幫助 使用環境:我用的是python2.7.9 在Python 3以後的版本中,urllib2這個模組已經不單獨存在(也就是說當你import urllib2時,系統提示你沒這個模組),urllib2被合併到了urllib中。 url
Python爬取百度貼吧圖片指令碼
新手,以下是爬取百度貼吧制定帖子的圖片指令碼,因為指令碼主要是解析html程式碼,因此一旦百度修改頁面前端程式碼,那麼指令碼會失效,權當爬蟲入門練習吧,後續還會嘗試更多的爬蟲。 # coding=ut
python網路爬蟲學習(二)一個爬取百度貼吧的爬蟲程式
今天進一步學習了python網路爬蟲的知識,學會了寫一個簡單的爬蟲程式,用於爬取百度貼吧的網頁並儲存為HTML檔案。下面對我在實現這個功能時的程式碼以及所遇到的問題的記錄總結和反思。 首先分析實現這個功能的具體思路: 通過對貼吧URL的觀察,可以看出貼吧中的
Python爬蟲實例(一)爬取百度貼吧帖子中的圖片
選擇 圖片查看 負責 targe mpat wid agent html headers 程序功能說明:爬取百度貼吧帖子中的圖片,用戶輸入貼吧名稱和要爬取的起始和終止頁數即可進行爬取。 思路分析: 一、指定貼吧url的獲取 例如我們進入秦時明月吧,提取並分析其有效url如下
完整的爬蟲程序爬取百度貼吧的圖片
列表 文檔 for tieba http ... 自增 num 圖片 #!/usr/bin/env python#-- coding:utf-8 -- import osimport urllibimport urllib2from lxml import etree cl
簡單爬蟲,爬去百度貼吧圖片
思路: 1.根據初始url獲取網頁內容 2.根據網頁內容獲取總頁數及所有頁面的url 3.根據每頁的url,將網頁下載到本地 4.讀取本地檔案從檔案中解析出所有的jpg圖片的url 5.用圖片的url下載圖片並儲存成指定的資料夾 6.批量下載圖片,預設儲存到當前目錄下 7
PHP爬蟲-爬取百度貼吧首頁違規主題貼
因為是第一次寫,感覺有點冗餘。不過嘛,本文章主要面向不知道爬蟲為何物的小夥伴。o(∩_∩)o <?php $url='http://tieba.baidu.com/f?ie=utf-8&kw=php&fr=search'; // 地址 $html = file_ge
Python爬蟲-爬取百度貼吧
方法 eba style name urlopen for pri url pen 爬取百度貼吧 ===================== ===== 結果示例: ===================================== 1 ‘‘‘ 2 爬去百
第一次初學爬蟲編寫的最簡單的爬出百度貼吧的圖片
、`此程式碼可以無限翻頁下載,可以在上面直接改URL裡面的貼吧名字就能爬取自己喜歡的貼吧的圖片,不過 不建議爬取大貼吧,因為大貼吧 帖子多 執行很久才能下載,下面附上簡單的程式碼 url=‘https://tieba.baidu.com/f?kw=效能測試&am
Python爬取百度貼吧回帖中的微訊號(基於簡單http請求)
作者:草小誠 轉載請注原文地址:https://blog.csdn.net/cxcjoker7894/article/details/85685115 前些日子媳婦兒有個需求,想要一個任意貼吧近期主題帖的所有回帖中的微訊號,用來做一些微商的操作,你懂的。因為有些貼吧專門就是
python爬蟲爬取百度貼吧(入門練習)
需求說明: 從控制檯輸入指定爬取的貼吧名稱,起始頁面,結束頁面,並在檔案中 建立以 貼吧名稱+“爬取內容” 為名字建立檔案件,裡面的每一個 檔案都是爬取到的每一頁html檔案,檔名稱:貼吧名稱_page.html import urllib.reque
python爬蟲(13)爬取百度貼吧帖子
爬取百度貼吧帖子 一開始只是在網上看到別人寫的爬取帖子的文章,然後自己就忍不住手癢自己鍛鍊一下, 然後照著別人的寫完,發現不太過癮, 畢竟只是獲取單個帖子的內容,感覺內容稍顯單薄,然後自己重新做了修改,把它變成重寫成了一個比較強大的爬蟲 精簡版本 簡介 通過帖子的地址,獲
編寫爬蟲爬取百度貼吧帖子的學習筆記
再接再厲,再次使用python3學習編寫了一個爬取百度貼吧帖子的程式,不多說,直接上關鍵程式碼 #抓取貼吧一個帖子上的內容(一頁內容) import urllib import urllib.req
Python爬蟲例項--爬取百度貼吧小說
Python爬蟲例項–爬取百度貼吧小說 寫在前面 本篇文章是我在簡書上寫的第一篇技術文章,作為一個理科生,能把僅剩的一點文筆拿出來獻醜已是不易,希望大家能在指教我的同時給予我一點點鼓勵,謝謝。 一.介紹 小說吧:顧名思義,是一個小說
requests+xpath+map爬取百度貼吧
name ads int strip 獲取 app open http col 1 # requests+xpath+map爬取百度貼吧 2 # 目標內容:跟帖用戶名,跟帖內容,跟帖時間 3 # 分解: 4 # requests獲取網頁 5 # xpath提取內