
爬取百度貼吧圖片
阿新 • • 發佈:2018-11-11
本次文章內容是爬取貼吧圖片,希望對大家有所幫助
使用環境:我用的是python2.7.9
在Python 3以後的版本中,urllib2這個模組已經不單獨存在(也就是說當你import urllib2時,系統提示你沒這個模組),urllib2被合併到了urllib中。
- urllib2.urlopen()變成了urllib.request.urlopen()
- urllib2.Request()變成了urllib.request.Request()
如果有的用的是python3以後的版本,記得改一下哦
一、 獲取要爬取的貼吧的網址
開啟瀏覽器,找到我們想爬取的貼吧,獲取其網址

二、 獲取頁面原始碼
利用下面函式來獲取原始碼
def gethtml(url):
page = urllib.urlopen(url)
html = page.read()
return html
三、匹配的圖片地址
首先,我們開啟第一步的網址,右擊審查元素,在審查元素中找到圖片的地址,觀察其地址的格式
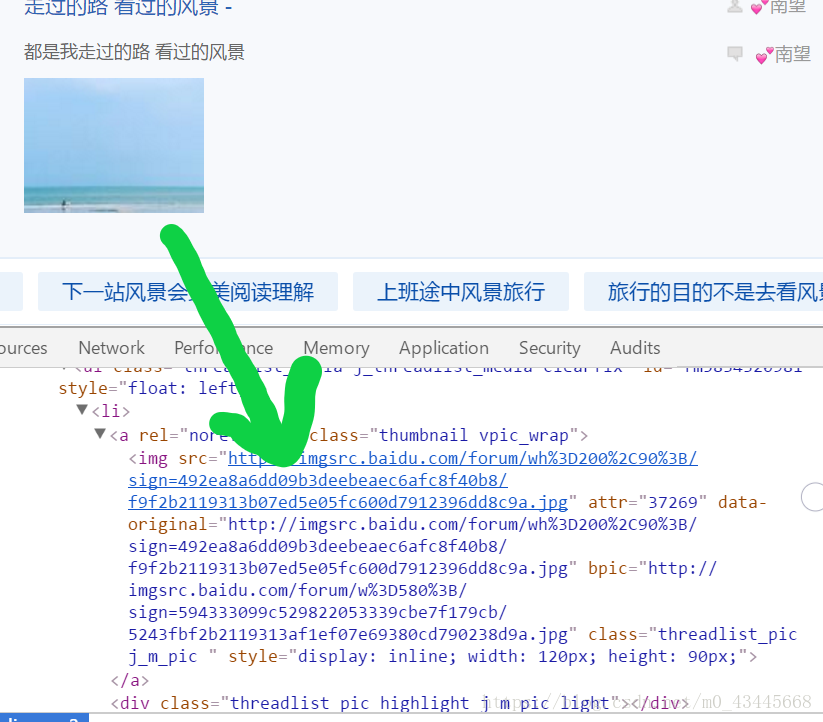
這裡,我匹配的是bpic等於的那個網址,從這我們可以看到圖片的地址是以.jpg結尾,利用正則進行匹配
reg = r'bpic="(.*?\.jpg).*?pic'
這裡括號所括住的部分,正是我們所需要的地址
- (.*?)是進行最小匹配,是非貪婪模式
- \ 是轉義字元
四、儲存圖片至本地
存入本地
urllib.urlretrieve(imgurl, '%s.jpg' % x)
或者可以存至自己新建的資料夾
f = open('tupian/'+str(x)+'.jpg', 'wb')
f.write((urllib2.urlopen(imgurl)).read())
f.close()
五、完整程式碼呈現
程式碼中有中文時,完整新增的是 # - * - coding:utf-8 - * -
#coding:utf8只是簡寫
此程式中,共用到三個庫:
- import re
- import urllib
- import urllib2
#程式碼中有中文時,需加#coding:utf8
# coding:utf8
#匯入需要的模組,這裡需要re模組匹配正則,urllib模組獲取網頁原始碼,urllib2模組將獲取的圖片存入資料夾中
import re
import urllib
import urllib2
#獲取網頁原始碼的函式
def gethtml(url):
page = urllib.urlopen(url)
html = page.read()
return html
#獲取圖片的函式
def getimg(html):
#利用正則獲取圖片的網址
reg = r'bpic="(.*?\.jpg).*?pic'
imgre = re.compile(reg)
imglist = re.findall(imgre,html)
#此變數x用於下載圖片時為圖片命名
x=0
for imgurl in imglist:
#這個print可以用於檢驗匹配出的圖片地址
print imgurl
#第一種:下載圖片,儲存到本地
#urllib.urlretrieve(imgurl, '%s.jpg' % x)
#第二種:將下載好的檔案存入一個資料夾中.(wb存入時會刪除此資料夾原有的圖片)
f = open('tupian/'+str(x)+'.jpg', 'wb')
f.write((urllib2.urlopen(imgurl)).read())
f.close()
x+=1
html = gethtml("http://tieba.baidu.com/f?ie=utf-8&kw=風景")
getimg(html)
結果呈現
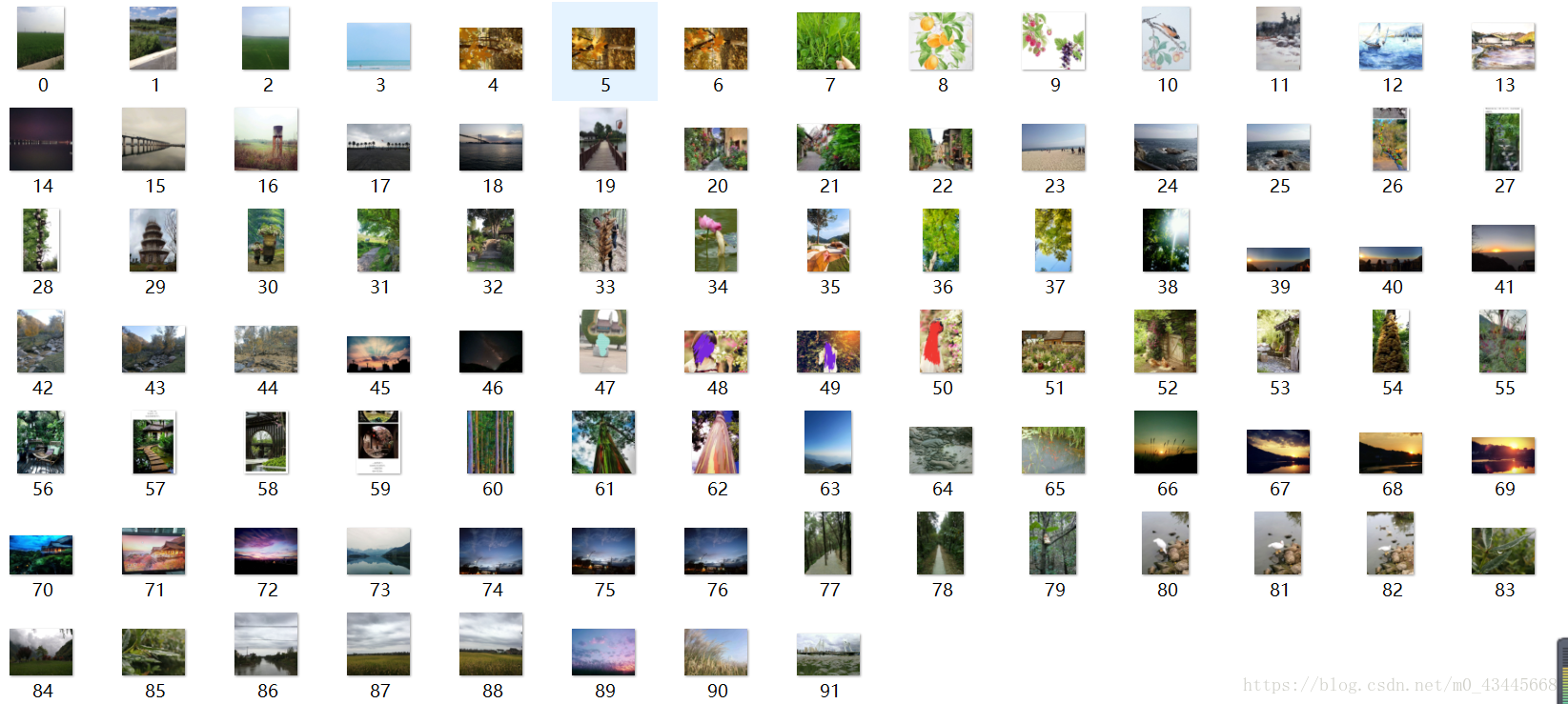
以上就是爬取貼吧圖片的全部過程