
c4.5演算法解讀
目錄
C4.5演算法是用於生成決策樹的一種經典演算法,是ID3演算法的一種延伸和優化。
所以要介紹C4.5演算法,就要把ID3,以及ID3中設計的熵的概念一起進行講解。
關於熵的概念在溯源探幽--熵的世界文章中做了很詳細的介紹,所以這裡大致過一下。
一、熵的認識
1、熵的概念
熵:是表示隨機變數不確定性的度量,熵的取值越大,隨機變數的不確定性也越大。
設X是一個取有限個值的離散隨機變數,其概率分佈為
P(X=xi)=pi, i=1,2,⋯,n
熵計算公式:H(X)=- ∑ pi * logpi,i=1,2, ... , n
一個栗子: A集合[1,1,2,2,2,2,2,2,2,2]
B集合[1,1,2,3,4,5,6,7,8,9]
先觀察下資料,對於集合A,裡面只有1、2兩個不同資料;
而B集合裡面有9個不同資料,很顯然B比A更加混亂一些,
這是我們直觀的感受,接下來我們用公式計算一下
H(A)=-2/10*log(2/10)+(-8/10*log(8/10))=0.217
(1的概率為2/10,2的概率為8/10)
H(B)=-2/10*log(2/10)+(-1/10*log(1/10))*8=0. 940
(1的概率為2/10,其他8個值的概率為1/10)
通過公式計算我們也可以得到,A的熵值較小,說明A比B更加有效一點
對於熵:H(X)=- ∑ pi * logpi
不確定性越大,得到的熵值也就越大
當p=0或p=1時,H(p)=0,隨機變數完全沒有不確定性
當p=0.5時,H(p)=1,此時隨機變數的不確定性最大
2、資訊熵公式推導
對於公式H(X)我們也可以進行簡單的推導:
假設我們有兩個類別1,2.對應的概率分別為P1=x ,P2=1-x
H(x)=-(xlog(x)+(1-x)log(1-x)),其實就是求H(X)的極值點,
很顯然,當x趨於+∞和-∞時,H(X)趨於0,所以就變成求最大值點,最簡單的方式就是求導;
H(x)’=log(x)-1/ln(a)-log(1-x)+1/ln(a)=0
Log(x)-log(1-x)=0
Log(x/(1-x))=0
x/(1-x)=1
最終可以求的x=0.5(如下圖)

二、ID3
ID3演算法的核心是在決策樹各個子節點上應用資訊增益準則選擇特徵,遞迴的構建決策樹.
具體方法是:從根節點開始,對節點計算所有可能的特徵的資訊增益,選擇資訊增益最大的特徵作為節點的特徵,由該特徵的不同取值建立子節點;再對子節點遞迴呼叫以上方法,構建決策樹。直到所有特徵的資訊增益均很小或沒有特徵可以選擇為止。最後得到一個決策樹。
【資訊增益:表示特徵X使得類Y的不確定性減少的程度。(分類後的專一性,希望分類後的結果是同類在一起) 】
ID3過程:
根據資訊增益(Informationgain)來選取Feature作為決策樹分裂的節點.特徵A對訓練資料集D的資訊增益定義為集合D的經驗熵(所謂經驗熵,指的是熵是有某個資料集合估計得到的)H(D)與特徵A給定條件下D的經驗條件熵 H(D∣A) 之差,記為g(D,A).
g(D,A)=H(D)−H(D|A) 實際上就是特徵A和D的互資訊
例項論證
插入一個例子:接下來所有的演算法和實踐都用本例來進行計算
小王是一家著名高爾夫俱樂部的經理。但是他被僱員數量問題搞得心情十分不好。某些天好像所有人都來玩高爾夫,以至於所有員工都忙的團團轉還是應付不過來,而有些天不知道什麼原因卻一個人也不來,俱樂部為僱員數量浪費了不少資金。
小王的目的是通過下週天氣預報尋找什麼時候人們會打高爾夫,以適時調整僱員數量。因此首先他必須瞭解人們決定是否打球的原因。

回到ID3演算法
分別以A1,A2,A3,A4 來表示
outlook,temperature,humidity和windy情況4個特徵,下面來計算每個特徵的資訊增益.
具體如下:
在歷史資料中(14天)有9天打球,5天不打球,
所以此時總體的熵應為:
H(D)=-9/14*log(9/14)-5/14*log(4/14)=0.940

4個特徵逐一分析,先從outlook特徵開始:
Outlook = sunny時,
H(D|A1=sunny)=-2/5*log(2/5)-3/5*log(3/5)=0.971
Outlook = overcast時,
H(D|A1=overcast)=-4/4*log(4/4)-0/4*log(0/4)= 0
Outlook = rainy時,
H(D|A1=rainy)=-3/5*log(3/5)-2/5*log(2/5)= 0.971
根據資料統計,outlook取值分別為
sunny,overcast,rainy的概率分別為: 5/14, 4/14, 5/14
熵值計算: H(D|A1) =5/14* 0.971 + 4/14 * 0 + 5/14 * 0.971 = 0.693
資訊增益:系統的熵值從原始的0.940下降到了0.693,
增益為g(D,A1)=H(D)−H(D|A1)= 0.940- 0.693=0.247
同樣的方式可以計算出其他特徵的資訊增益,那麼我們選擇最大的那個特徵就可以啦,相當於是遍歷了一遍特徵,找出來了大當家,然後再其餘的特徵中繼續通過資訊增益查詢下一個根節點!
g(D,A1)=gain(outlook)=0.247
g(D,A2)=gain(temperature)=0.029
g(D,A3)=gain(humidity)=0.152
g(D,A4)=gain(windy)=0.048
總結
總結一下上面的計算過程,
假設訓練資料集為 D,∣D∣表示其大小.設有 K 個分類 C1,C2,…,Ck,∣Ck∣ 為類 Ck 的大小,即樣本個數, ∑Kk=1∣Ck∣=∣D∣ .設特徵 A 有 n 個不同的取值 {a1,a2,…,an},根據特徵 A 的取值將 D 劃分成 n 個子集 D1,D2,…,Dn,∣Di∣ 為 Di 的大小, ∑ni=1∣Di∣ .記子集 Di中屬於類 Ck的樣本集合為 Dik, ∣Dik∣ 為 Dik 的大小.
於是資訊增益的演算法如下:
計算資料集 D 的經驗熵 H(D):
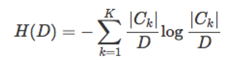
計算特徵A對資料集 D 的經驗條件熵:

具體為:
1.若D中所有例項都屬於同一類 Ck,則 T 為單節點樹,並將類 Ck作為該節點的類標記,返回T.
2.若A=Φ,則T為單節點樹,並將D中例項最大的類Ck作為該節點的類標記,返回T.
3.否則,按照資訊增益的演算法,計算每個特徵對D的資訊增益,取資訊增益最大的特徵 Ag.
4.如果 Ag<ε,則置 T 為單節點樹,並將D中例項最大的類Ck作為該節點的類標記,返回T.
5.否則,對Ag的每一可能值 ai,依Ag=ai將D分成若干非空子集Di,將Di中例項最大的類作為標記,構建子節點,由節點和子節點構成樹T,返回T.
6.對第 i 個子節點,以Di為訓練集,以A−{Ag} 為特徵集,遞迴地呼叫步驟1到步驟5,得到子樹 Ti,返回Ti.
ID3缺點:
ID3採用的資訊增益度量存在一個內在偏置,它優先選擇有較多屬性值的Feature,因為屬性值多的Feature會有相對較大的資訊增益。
(資訊增益反映的給定一個條件以後不確定性減少的程度,必然是分得越細的資料集確定性更高,也就是條件熵越小,資訊增益越大).
為了克服ID3的缺點,引進C4.5演算法
三、C4.5
C4.5演算法是資料探勘十大演算法之一,它是對ID3演算法的改進
避免ID3不足的一個度量就是不用資訊增益來選擇Feature,而是用資訊增益比率(gainratio),增益比率通過引入一個被稱作分裂資訊(Splitinformation)的項來懲罰取值較多的Feature,分裂資訊用來衡量Feature分裂資料的廣度和均勻性:
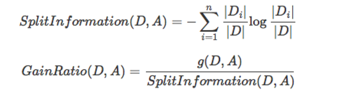
但是當某個Di的大小跟D的大小接近的時候,SplitInformation(D,A)→0,GainRatio(D,A)→∞,為了避免這樣的屬性,可以採用啟發式的思路,只對那些資訊增益比較高的屬性才應用資訊增益比率.
還是之前的例子,根據公式可以直接求解
SplitInformation(outlook)=SplitInformation(D,A1)
=-5/14*log(5/14)-5/14*log(5/14)-5/14*log(5/14)=1.58
g(D,A1)=0.247(ID3演算法結果,直接引用)
GainRatio(D,A1)=g(D,A1) /SplitInformation(D,A1)
=0.247/1.58= 0.16
同理可以求得其他自變數的增益率,
選取最大的資訊增益率作為分裂屬性。
相比ID3,C4.5還能處理連續屬性值,具體步驟為:
•把需要處理的樣本(對應根節點)或樣本子集(對應子樹)按照連續變數的大小從小到大進行排序。
•假設該屬性對應的不同的屬性值一共有N個,那麼總共有N−1個可能的候選分割閾值點,每個候選的分割閾值點的值為上述排序後的屬性值中兩兩前後連續元素的中點,根據這個分割點把原來連續的屬性分成bool屬性.實際上可以不用檢查所有N−1個分割點。
• 用資訊增益比率選擇最佳劃分。
C4.5演算法優缺點分析
優點:
(1)通過資訊增益率選擇分裂屬性,克服了ID3演算法中通過資訊增益傾向於選擇擁有多個屬性值的屬性作為分裂屬性的不足;
(2)能夠處理離散型和連續型的屬性型別,即將連續型的屬性進行離散化處理;
(3)構造決策樹之後進行剪枝操作;
(4)能夠處理具有缺失屬性值的訓練資料。
缺點:
(1)演算法的計算效率較低,特別是針對含有連續屬性值的訓練樣本時表現的尤為突出。
(2)演算法在選擇分裂屬性時沒有考慮到條件屬性間的相關性,只計算資料集中每一個條件屬性與決策屬性之間的期望資訊,有可能影響到屬性選擇的正確性。