論文閱讀 | MIX: Multi-Channel Information Crossing for Text Matching
阿新 • • 發佈:2018-11-10
MIX: Multi-Channel Information Crossing for Text Matching
(騰訊2018 KDD)
主要特點:
- 1.本文中對於句子匹配,考慮了很多不同層面的:詞,短語,句法,詞頻和權重,語法信心等資訊
- 2.通過多通道將所有資訊整合起來,其中包括:
- (1)semantic information:unigrams,bigrams,trigrams(用於相似度匹配)
- (2)structure information:詞的權重,詞性,實體(作為注意力機制)
模型具體細節
1.local matching
(1)unigram可能會存在相同但其實意義不同的情況
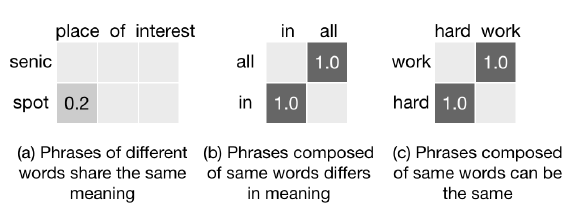
(2)故增加使用bigrams,trigrams
2.local and global matching
2.1 使用idf作為attention
其中的idf組成的attention矩陣:使用兩個詞的idf相乘作為其值
舉例來說,對於一個問題:What year did Lebron James win his first MVP?
(1)對於回答1:Steve Curry won his first MVP in 2014.
儘管其他詞的匹配度很高,但是關鍵詞Lebron James卻沒有匹配成功,使得這個回答其實不是真正的回答

圖a在his,first等詞上匹配度很高,乘以b中tfidf組成的attention矩陣後,這些
非重要詞的重要度下降 (2)而對於回答2:Lebron James was rated as the best player in 2009
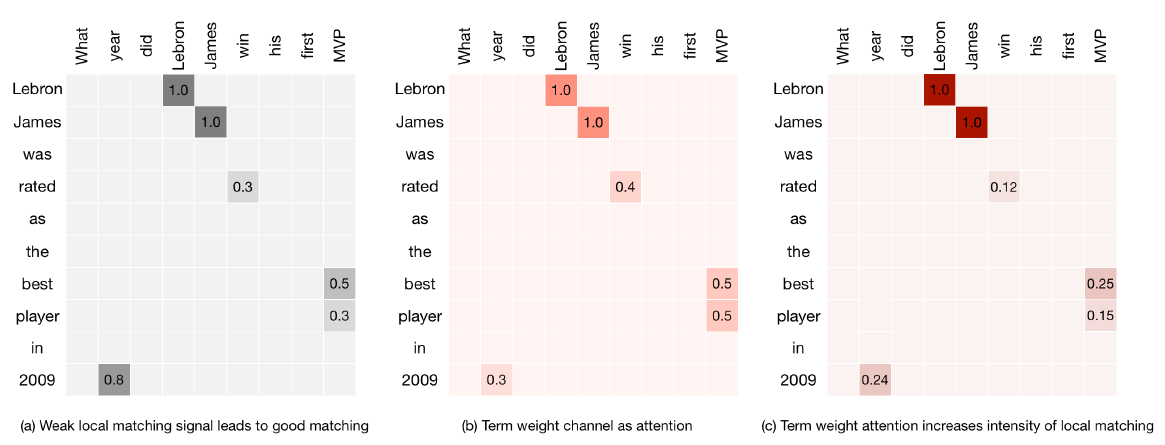
儘管其他詞的匹配不高,但關鍵詞Lebron James的匹配度非常高,通過這種手段,突出了重要詞的匹配度
2.2 Part-of-speech
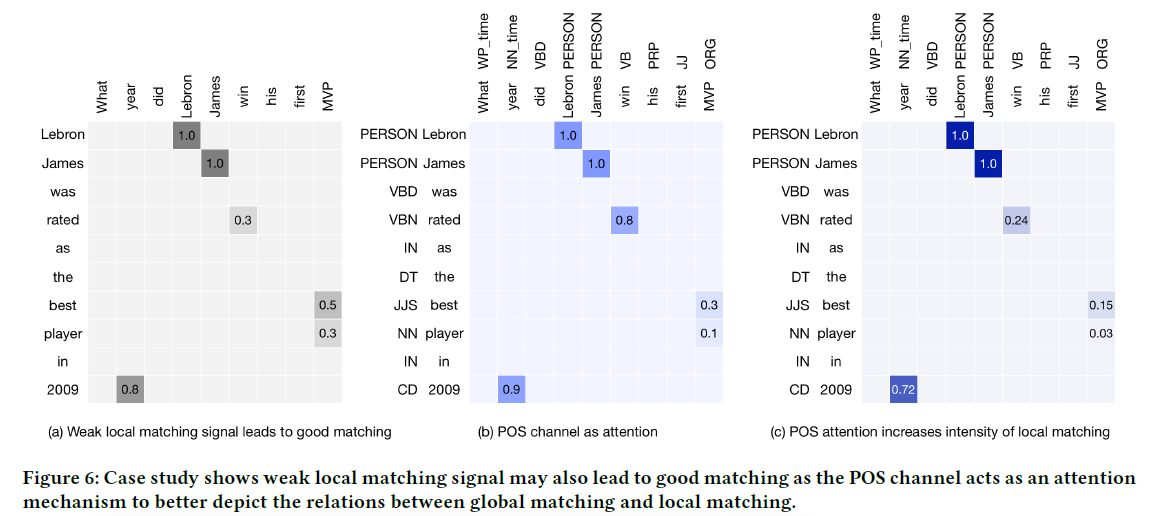
抽出句子中的實體,對於Person tag,Verb,wh_pronoun(英文中存在),time,number給與注意力
2.3 詞的位置
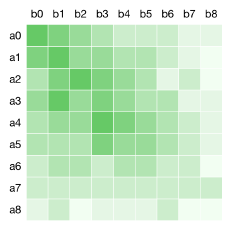
問答中,一般問題和回答中,第一個字和第一個字的匹配度會比第一個字和第七個字的匹配度高。
通過訓練一層attention可以看到如上圖所示,句子位置的注意力程度是不一樣的
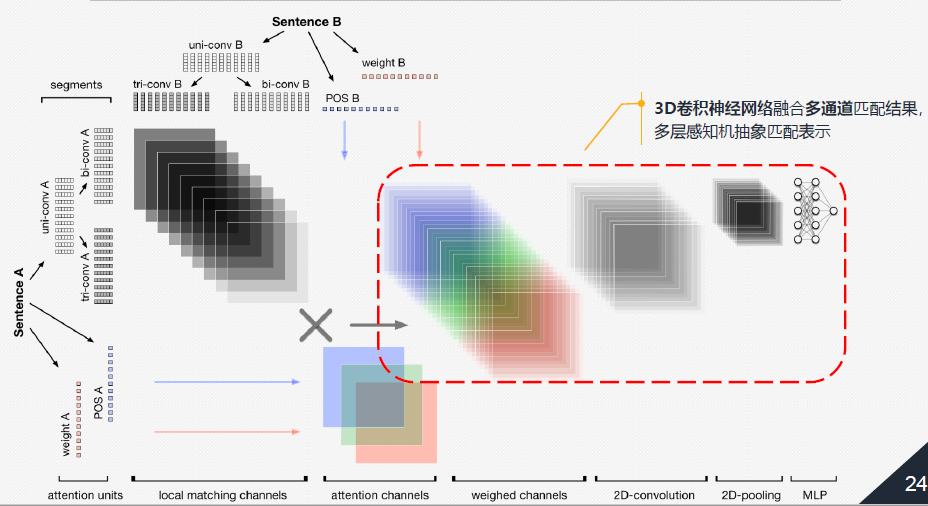
3.多通道融合
通過3D CNN進行卷積