
3D點雲資料分析:pointNet++論文分析及閱讀筆記
PointNet的缺點:
- PointNet不捕獲由度量空間點引起的區域性結構,限制了它識別細粒度圖案和泛化到複雜場景的能力。
利用度量空間距離,我們的網路能夠通過增加上下文尺度來學習區域性特徵。
- 點集通常採用不同的密度進行取樣,這導致在統一密度下訓練的網路的效能大大降低。
新的集合學習層來自適應地結合多個尺度的特徵。
一,介紹:
PointNet++:分層方式處理在度量空間中取樣的一組點 。
- 通過基礎空間的距離度量將這組點分割成重疊的區域性區域。
- 提取區域性特徵來捕獲來自小鄰域的精細幾何結構; 這些區域性特徵被進一步分組為更大的單元並被處理以產生更高階的特徵。
- 重複這個過程直到我們獲得整個點集的特徵。
需要解決的問題:
- 如何生成點集的劃分
- 如何通過區域性特徵學習抽象點集或區域性特徵。
這兩個問題是相關的:
點集的分割必須產生跨分割槽的共同結構,以便像卷積設定那樣共享區域性特徵學習者的權重。
PointNet++在巢狀的分割輸入集上遞迴的運用pointNet
每個分割槽:相鄰的球。每個分割槽包含質心位置和規模。質心通過最遠取樣點演算法獲得(FPS)
感受野依賴輸入資料和度量。
二.問題描述:
X = (M; d) 是離散的度量空間,m是點,d是距離度量。m的密度不均勻,
三.方法:
可以看作增加了層次結構的pointNet,
- 複習pointnet:缺乏不同規模上捕捉區域性上下文的能力。(採用分層特徵學習框架)
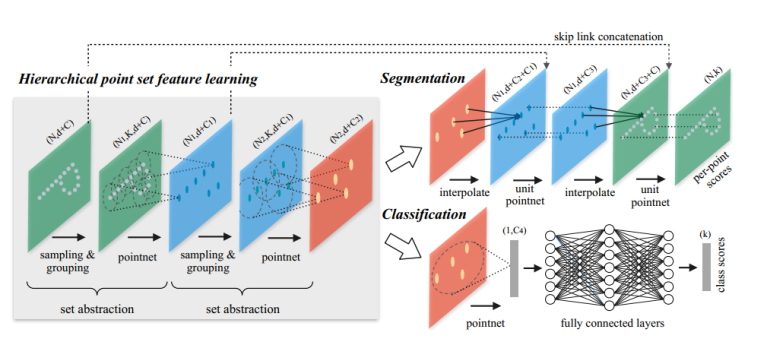
- 分層架構:
New architecture builds a hierarchical grouping of points and progressively abstract larger and larger local regions along the hierarchy.
At each level, aset of points is processed and abstracted to produce a new set with fewer elements.
抽象層的三個關鍵層:
Sampling layer : selects a set of points from input points (確定區域性區域的圖心)
Grouping layer : 分組層通過查詢質心周圍的“鄰近”點來構建區域性區域集。
PointNet layer :使用小型PointNet將區域性區域模式編碼為特徵向量

輸入:N * (d + c) 矩陣,d緯度座標,c點特徵緯度。
輸出:. It outputs an N0 × (d + C0) matrix of N0 subsampled points with d-dim coordinates and new C0-dim feature vectors summarizing local context
取樣層:迭代最遠點取樣(FPS)來選擇點x1,x2...的子集 ,(距離其餘的子集在歐幾里得空間上距離最遠)
分組層:
輸入:大小為N(d + C)的點集和大小為NId的一組質心的座標
輸出:groups of point sets of size N0 × K × (d + C),where each group corresponds to a local region and K is the number of points in the neighborhood of centroid points
使用方法:bell查詢(和cnn相比)
pointNet層:
輸入:N0 local regions of points with data size N0×K×(d+C)
輸出:輸出中的每個區域性區域都由其質心和區域性特徵抽象出來,這些特徵對質心的鄰域進行編碼。 Output data size is N0 × (d + C0)
將區域性的點座標進行轉化,通過使用相對座標和點要素,我們可以捕捉到區域性區域內的點對點關係 。
3.3 對不均勻取樣的魯棒特徵學習:
we should look for larger scale patterns in greater vicinity.
density adaptive PointNet layers
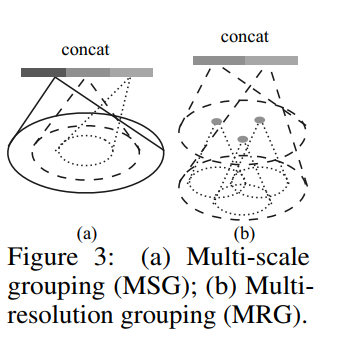
Multi-scale grouping (MSG).
- apply grouping layers with different scales
- according PointNets to extract features of each scale
- Features at different scales are concatenated to form a multi-scale
feature.
(各種稀疏性的訓練集)
Multi-resolution grouping (MRG). (這種更好)
MSG的計算成本太高。新方法:still preserves the ability to adaptively aggregate information according to the distributional properties of points。
當局部區域的密度較低時,第一個向量可能不如第二個向量可靠,因為在計算第一個向量中的子區域包含更稀疏的點並且更多地受到抽樣不足的影響。 在這種情況下,第二個向量應該加權得更高。
當局部區域的密度很高時,第一個向量提供更精細的細節資訊,因為它具有以較低解析度遞迴地檢查較高解析度的能力。
3.4 Point Feature Propagation for Set Segmentation
在集合抽象層中,對原始點集進行二次抽樣。 然而,在集合分割任務中,比如語義點標註,
我們希望獲得所有原始點的點特徵。
方法1:
always sample all points as centroids in all set abstraction levels (高成本)
方法2:
propagate features from subsampled points to the original points
hierarchical propagation strategy with distance based interpolation and across level skip links
In a feature propagation level, we propagate point features from
Nl × (d + C) points to Nl-1 points where Nl-1 and Nl (with Nl ≤ Nl-1) are point set size of input and output of set abstraction level l.
我們通過在Nl1點的座標處插入Nl個點的特徵值f來實現特徵傳播。在插值的眾多選擇中,我們使用基於k近鄰的反向距離加權平均值。

The interpolated features on Nl-1 points are then concatenated with skip linked point features from the set abstraction level.
結果:
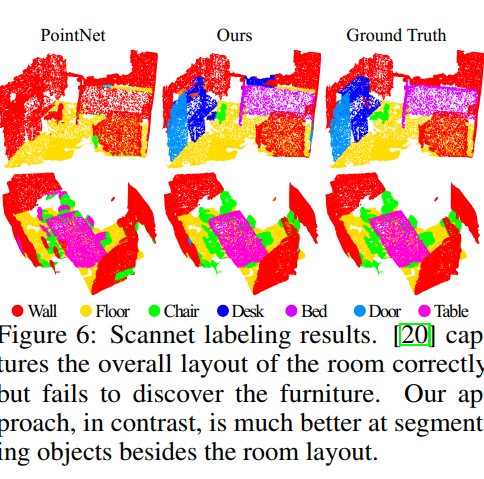
本質:是PointNet的分層版本
PointNet的不足:
1)無法很好地捕捉由度量空間引起的區域性結構問題,由此限制了網路對精細場景的識別以及對複雜場景的泛化能力。
2)欠缺了對區域性特徵的提取及處理,比如說點雲空間中臨近點一般都具有相近的特徵,同屬於一個物體空間中的點的概率也很大,就好比二維影象中,同一個物體的畫素值都相近一樣。
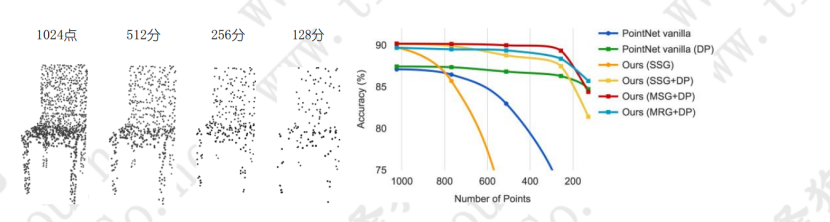
3)點雲資料的一個特徵是資料密度不同,體現出近多遠少等問題,而在密度不同的情況下,使用統一的模板處理這些資料顯然是不對的,基於此,PointNet++的作者提出了密度適應的網路結構。
PointNet++解決的問題:
1.如何對點雲進行區域性劃分
對資料集進行劃分,提取區域性特徵,然後不斷抽象,提取更高維的特徵,是PointNet++的基本思路,那麼首先的問題是如何定義區域性,PointNet++給出的解決思路是使用點球模型,從全部資料集中選出若干質心點,然後選取半徑,完成覆蓋整個資料集的任務。在質心點的選取上,採用的是FPS演算法,即隨機選取一個點,然後選擇離這個點最遠的點加入到結果集中,迭代這個過程,直到結果集中點的數量達到某個給定值,在PointNet++中,很常見的一個詞是metric,即度量,PointNet++中的很多東西都是依賴度量的,而在PointNet中,其實對於度量並不是很強調,或者細究的話都有可能不需要是度量空間(這個度量指的是什麼呢?)。在讀到中心點的集合後,第二個問題是如何選擇半徑,其實半徑的選取是個很麻煩的事,在點雲資料集中,有些地方比較稠密,有些地方比較稀疏,稠密的地方必然半徑要小,而稀疏的地方必然半徑要大,不然可能都提取不出什麼特徵,此時引出第二個問題——密度適應,若半徑確定,即區域性大小確定,此時訓練的模板大小也就確定了。
2.如何對點雲進行區域性特徵提取
每個圖層都有三個子階段:取樣,分組和PointNeting。在第一階段,選擇質心,在第二階段,把他們周圍的鄰近點(在給定的半徑內)建立多個子點雲。然後他們將它們給到一個PointNet網路,並獲得這些子點雲的更高維表示。然後,他們重複這個過程。
(這兩個問題是關聯的)
3.如何進行密度適應?
論文中提到的處理密度適應的方法有兩種
方法1為MSG,即把每種半徑下的區域性特徵都提取出來,然後組合到一起.
作者在如何組合的問題上提到了一種random dropping out input points的方法,存在兩個引數p和q,每個點以q的概率進行丟棄,而q為在[0,p]之間均勻取樣,這樣做,可以讓整體資料集體現出不同的稠密性和均勻性。MSG有一個巨大的問題是運算的問題,然後作者提出we can avoid the feature extraction in large scale neighborhoods at lowest levels,因為在低層級處理大規模資料,可能模板處理能力不夠,感受野有些過大,基於此,作者提出了MRG。
方法二MRG有兩部分向量構成,分別為上一層即Li-1層的向量和直接從raw point上提取的特徵構成,當點比較稀疏時,給從raw point提取的特徵基於較高的權值,而若點比較稠密,則給Li-1層提取的向量給予較高的權值,因為此時raw point的抽象程度可能不夠,而從Li-1層的向量也由底層抽取而得,代表著更大的感受野。當局部區域的密度較低時,第一個向量可能不如第二個向量可靠,因為在計算第一個向量中的子區域包含更稀疏的點並且更多地受到抽樣不足的影響。 在這種情況下,第二個向量應該加權得更高。 當局部區域的密度很高時,第一個向量提供更精細的細節資訊,因為它具有以較低解析度遞迴地檢查較高解析度的能力。
整體的網路結構:
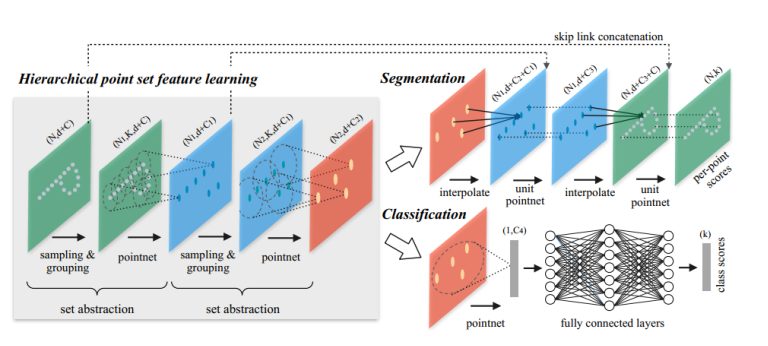
在整體網路結構中,首先進行set abstraction,這一部分主要即對點雲中的點進行區域性劃分,提取整體特徵,如圖可見,在set abstraction中,主要有Sampling layer、Grouping layer、以及PointNet layer三層構成,sampling layer即完成提取中心點工作,採用fps演算法,而在grouping中,即完成group操作,採用mrg或msg方法,最後對於提取出得點,使用pointnet進行特徵提取。在msg中,第一層set abstraction取中心點512個,半徑分別為0.1、0.2、0.4,每個圈內的最大點數為16,32,128。在classification的處理上,與pointnet相似。
分割和語義部分:
在集合抽象層中,對原始點集進行二次抽樣。 然而,在集合分割任務中,比如語義點標註,
我們希望獲得所有原始點的點特徵。
方法1:
always sample all points as centroids in all set abstraction levels (高成本)
方法2:
propagate features from subsampled points to the original points
hierarchical propagation strategy with distance based interpolation and across level skip links

In a feature propagation level, we propagate point features from
Nl × (d + C) points to Nl-1 points where Nl-1 and Nl (with Nl ≤ Nl-1) are point set size of input and output of set abstraction level l.
我們通過在Nl1點的座標處插入Nl個點的特徵值f來實現特徵傳播。在插值的眾多選擇中,我們使用基於k近鄰的反向距離加權平均值。
插值及回溯的方式,對於l - 1層的點,它有l層點插值後與在set abstraction時得到的特徵進行1 * 1的卷積,最終得到l - 1層的點的值,一直回溯,最終得到原始點的score。插值公式如下:
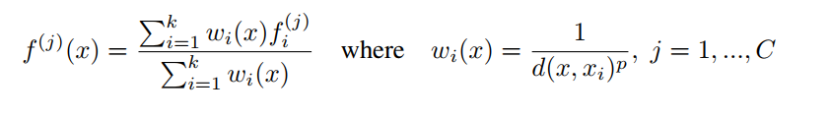
The interpolated features on Nl-1 points are then concatenated with skip linked point features from the set abstraction level.