
分析 AlphaGo 演算法原理的本質
和兒子討論演算法,兒子建議我參考一下AlphaGo的原理,發給我參考資料看了一下,感覺很受啟發。
一、AlphaGo的數學模型
1.1 圍棋問題的本質
圍棋問題本質上是一個數據分類問題。
圍棋問題可以這樣描述:給你一個圍棋的佈局,求出最佳落子位置。換句話講:
- 輸入是圍棋佈局,可以抽象為19x19階矩陣,元素取值-1、0、1。
- 輸出是一個位置,共有19x19=361種可能。
容易聯想到,實質上這是把19x19尺寸影象分成361類的問題。
1.2 影象分類的 CNN 模型
這裡給出影象分類的CNN網路模型示意圖:
圖1. 用於影象分類的CNN模型示意圖
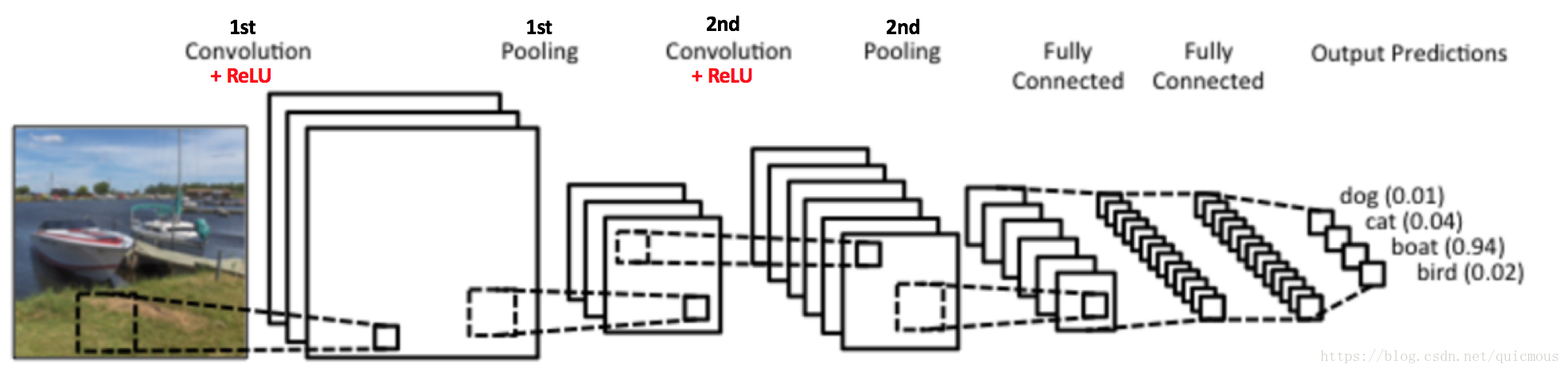
圖中輸入一幅圖片,輸出一個四維向量,給出了輸入影象是 dog、cat、boat、bird 四類目標的概率分佈。
1.3 圍棋的 CNN 模型
圍棋的 CNN 模型和影象分類模型本質上是一樣的,輸入是19x19解析度的棋局“影象”,輸出是361維概率分佈向量。其中,概率最大的那個位置就是最佳落子位置。
1.4 聰明的谷歌研究團隊
圍棋問題抽象成純粹的數學問題,是AlphaGo的核心問題。AlphaGo很聰明,把該問題抽象成了CNN網路模型,這是令人拍案叫絕的地方。
有時候不得不佩服谷歌的研究團隊,當年讀谷歌的FaceNet那篇論文時,我都有要自殺的感覺,真的,我覺得那個三元組模型太聰明瞭,通過一個間接的方法構造損失函式,避免了對海量組合樣本的標註(其實人臉特徵提取模型也不可能人工標註訓練樣本)。當年我苦思冥想也沒找到如此巧妙的途徑,這一點對谷歌俺是心悅誠服。
深度學習技術的推廣普及,谷歌功不可沒。谷歌為人類文明進步做出巨大貢獻,是一家偉大的公司。希望我們中國的企業也能把目光放遠一些,肩負起解放全人類的光榮使命。
二、模型和訓練
2.1 向人類學習
人類積累了大量的棋譜,展示了各種棋局如何落子的示例。這些可以作為訓練樣本。谷歌從圍棋對戰平臺KGS上獲得了人類選手的圍棋對弈棋譜,對於每一種棋局,都會有一個人類進行的落子,這也就是一個天然訓練樣本 ,如此可以得到3000萬個訓練樣本。
谷歌的實驗結果表明,這個方法不夠好。估計有兩原因:
- 數量太少:數量不足以覆蓋所有情況。
- 質量太差:人類的經驗未必正確,跟臭棋簍子學下棋,肯定學不好。
2.2 MCTS 蒙特卡洛搜尋樹
MCTS這個想法很奇妙,不需要任何人類的棋譜。
2.2.1 決策樹
我們可以這樣設想,圍棋的所有可能的局面和落子方法如果全部展開,是一個無比龐大的決策樹。每個節點對應一個棋局,每個棋局都有一個最佳落子推薦位置。這樣圍棋問題就搞定了。
由於這棵決策樹過於龐大,我們可以構造其一部分,用這一部分做訓練樣本,然後其餘的部分,通過訓練卷積神經網路模型來進行預測計算。
2.2.2 MCTS 決策樹
MCTS開始構造搜尋樹之前,首先假定任何棋局在任何位置落子,取勝的機會都是相同的。也就是說,當出現一個新的棋局時,MCTS會為該棋局構造一個初始的19x19階落子決策權重矩陣,每個落子位置的權重被初始化成相同的值。
圖2. 棋局和決策權重矩陣示意圖
從空白棋局開始,隨機落子,直至對弈結束。把對弈過程中出現的棋局放入決策樹,各個棋局根據最終勝負調整其決策矩陣權重。接下來下第二盤時,我們就有了一個稍微有一點點經驗的的落子參考權重指導。如此下去,對弈10萬盤,我們將構造出一個有一定”智力“的決策樹。
2.2.3 MCTS 特點分析
MCTS有如下幾個特點:
- MCTS 不僅可以用於構建訓練樣本,而且在對弈過程中,也可以根據對手落子情況繼續”線上“模擬。可以想象,進行得了大量隨機模擬後,可以得出最佳的走起方法。這種方法谷歌論文中稱為Rollout。
- MCTS 可以平行計算,可以通過增加計算資源數量提升計算速度。
2.3 人類經驗 + MCTS,增強演算法能力
MCTS的棋局落子權重矩陣,可以根據人類的棋譜初始化,可以提高訓練速度。實驗表明,在開局前面的20步人類的經驗是可以起到有效作用的。
三、強化學習和自我對弈
接下來的故事就沒前面精彩了,但是引入了另外一項新技術——強化學習,於是乎誕生了 AlphaGo Zero。限於篇幅,強化學習和AlphaGo Zero 以後再慢慢討論吧。