
深度解讀 AlphaGo 演算法原理
http://blog.csdn.net/songrotek/article/details/51065143
http://blog.csdn.net/dinosoft/article/details/50893291
https://www.zhihu.com/question/39905662
https://yq.aliyun.com/articles/53737
https://wenku.baidu.com/view/3cbb606f49649b6648d747fb.html
深度解讀AlphaGo

















































































原版論文是《Mastering the game of Go with deep neural networks and tree search》,有時間的還是建議讀一讀,沒時間的可以看看我這篇筆記湊活一下。網上有一些分析AlphaGo的文章,但最經典的肯定還是原文,還是踏踏實實搞懂AlphaGo的基本原理我們再來吹牛逼吧。
需要的一些背景
對圍棋不瞭解的,其實也不怎麼影響,因為只有feature engineering用了點圍棋的知識。這裡有一篇《九張圖告訴你圍棋到底怎麼下》可以簡單看看。
對深度學習不怎麼了解的,可以簡單當作一個黑盒演算法。但
“深度學習是機器學習的一種,它是一臺精密的流水線,整頭豬從這邊趕進去,香腸從那邊出來就可以了。”- 1
- 1
蒙特卡羅方法
蒙特卡羅演算法:取樣越多,越近似最優解;
拉斯維加斯演算法:取樣越多,越有機會找到最優解;
舉個例子,假如筐裡有100個蘋果,讓我每次閉眼拿1個,挑出最大的。於是我隨機拿1個,再隨機拿1個跟它比,留下大的,再隨機拿1個……我每拿一次,留下的蘋果都至少不比上次的小。拿的次數越多,挑出的蘋果就越大,但我除非拿100次,否則無法肯定挑出了最大的。這個挑蘋果的演算法,就屬於蒙特卡羅演算法——儘量找好的,但不保證是最好的。
作者:蘇椰
連結:https://www.zhihu.com/question/20254139/answer/33572009 - 1
- 2
- 3
- 4
- 5
- 6
- 1
- 2
- 3
- 4
- 5
- 6
蒙特卡羅樹搜尋(MCTS)
網上的文章要不拿蒙特卡羅方法忽悠過去;要不籠統提一下,不提細節;要不就以為只是樹形的隨機搜尋,沒啥好談。但MCTS對於理解AlphaGo還是挺關鍵的。
MCTS這裡的取樣,是指一次從根節點到遊戲結束的路徑訪問。只要取樣次數夠多,我們可以近似知道走那條路徑比較好。貌似就是普通的蒙特卡羅方法?但對於樹型結構,解空間太大,不可能完全隨機去取樣,有額外一些細節問題要解決:分支節點怎麼選(寬度優化)?不選比較有效的分支會浪費大量的無謂搜尋。評估節點是否一定要走到底得到遊戲最終結果(深度優化)?怎麼走?隨機走?
基本的MCTS有4個步驟Selection,Expansion,Simulation,Backpropagation(論文裡是backup,還以為是備份的意思),論文裡state,action,r(reward),Q 函式都是MCTS的術語。 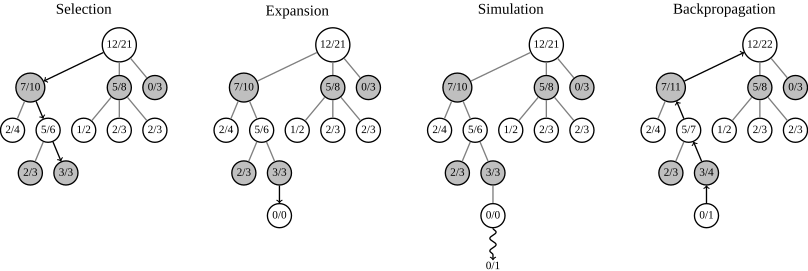
圖片展示瞭如何更新節點的勝率,選擇勝率大的分支進行搜尋(7/10->5/6->3/3),到了3/3葉子節點進行展開選擇一個action,然後進行模擬,評估這個action的結果。然後把結果向上回溯到根節點。來自維基百科
具體的細節,可以參考UCT(Upper Confidence Bound for Trees) algorithm – the most popular algorithm in the MCTS family。從維基百科最下方那篇論文截的圖。原文有點長,這裡點到為止,足夠理解AlphaGO即可。N是搜尋次數,控制exploitation vs. exploration。免得一直搜那個最好的分支,錯過邊上其他次優分支上的好機會。

AlphaGo

四大元件。最後只直接用了其中3個,間接用其中1個。
Policy Network (Pσ)
Supervised learning(SL)學的objective是高手在當前棋面(state)選擇的下法(action)。Pσ=(a|s)
要點
1. 從棋局中隨機抽取棋面(state/position)
2. 30 million positions from the KGS Go Server (KGS是一個圍棋網站)。資料可以說是核心,所以說AI戰勝人類還為時尚早,AlphaGo目前還是站在人類expert的肩膀上前進。
3. 棋盤當作19*19的黑白二值影象,然後用卷積層(13層)。比影象還好處理。rectifier nonlinearities
3. output all legal moves
4. raw input的準確率:55.7%。all input features:57.0%。後面methods有提到具體什麼特徵。需要一點圍棋知識,比如liberties是氣的意思
Fast Rollout Policy (Pπ)
linear softmax + small pattern features 。對比前面Policy Network,
- 非線性 -> 線性
- 區域性特徵 -> 全棋盤
準確率降到24.2%,但是時間3ms-> 2μs。前面MCTS提到評估的時候需要走到底,速度快的優勢就體現出來了。
Reinforcement Learning of Policy Networks (Pρ)
要點
- 前面policy networks的結果作為初始值ρ=μ
- 隨機選前面某一輪的policy network來對決,降低過擬合。
- zt=±1是最後的勝負。決出勝負之後,作為前面每一步的梯度優化方向,贏棋就增大預測的P,輸棋就減少P。
- 校正最終objective是贏棋,而原始的SL Policy Networks預測的是跟expert走法一致的準確率。所以對決結果80%+勝出SL。
跟Pachi對決,勝率從原來當初SL Policy Networks的11%上升到85%,提升還是非常大的。
Reinforcement Learning of Value Networks (vθ)
判斷一個棋面,黑或白贏的概率各是多少。所以引數只有s。當然,你列舉一下a也能得到p(a|s)。不同就是能知道雙方勝率的相對值
- using policy p for both players (區別RL Policy Network:前面隨機的一個P和最新的P對決)
- vθ(s)≈vPρ(s)≈v∗(s) 。v∗(s) 是理論上最優下法得到的分數。顯然不可能得到,只能用我們目前最強的Pρ演算法來近似。但這個要走到完才知道,只好再用Value Network vθ(s)來學習一下了。
Δθ∝∂vθ(s)∂θ(z−vθ(s))
(上面式子應該是求min(z−vθ(s))2,轉成max就可以去掉求導的負號)因為前序下法是強關聯的,輸入只有一個棋子不同,z是最後結果,一直不變,所以直接這麼算會overfitting。變成直接記住結果了。解法就是隻抽取game中的position,居然生成了30 million distinct positions。那就是有這麼多局game了。
| MSE | training set | test set |
|---|---|---|
| before | 0.19 | 0.37 |
| after | 0.226 | 0.234 |
AlphaGo與其他程式的對比。AlphaGo上面提到的幾個元件之間對比。這幾個元件單獨都可以用來當AI,用MCTS組裝起來威力更強。(kyu:級,dan:段)

MCTS 組裝起來前面的元件
結構跟標準的MCTS類似。

每次MCTS simulation選擇
at=argmaxa(Q(st,a)+u(st,a))=argmaxa(Q(st,a)+C∗Pσ1+搜索次數N(s,a))
我自己補了個常數C,寫到一起容易看點。
V(θL)是葉子節點的評估值,Q是多次模擬後的期望V(θL)。有趣的是實驗結果λ=0.5是最好的
- value network vθ
- fast rollout走到結束的結果zL
最開始還沒expand Q是0,那SL的Pσ 就是prior probabilities。Pσ還能起到減少搜尋寬度的作用,普通點得分很低。比較難被select到。有趣的結論是,比較得出這裡用SL比RL的要好!!模仿人類走棋的SL結果更適合MCTS搜尋,因為人類選擇的是 a diverse beam of promising moves。而RL的學的是最優的下法(whereas RL optimizes
for the single best move)。所以人類在這一點暫時獲勝!不過另一方面,RL學出來的value networks在評估方面效果好。所以各有所長。
搜尋次數N一多會扣分, 鼓勵exploration其他分支。
summary
整體看完,感覺AlphaGo實力還是挺強的。在機器學習系統設計和應用方面有很大的參考意義。各個元件取長補短也挺有意思。
相關推薦
深度解讀 AlphaGo 演算法原理
http://blog.csdn.net/songrotek/article/details/51065143 http://blog.csdn.net/dinosoft/article/details/50893291 https://www.zhihu.com/question/39905662 h
DQN從入門到放棄5 深度解讀DQN演算法
分享一下我老師大神的人工智慧教程!零基礎,通俗易懂!http://blog.csdn.net/jiangjunshow 也歡迎大家轉載本篇文章。分享知識,造福人民,實現我們中華民族偉大復興!
分析 AlphaGo 演算法原理的本質
和兒子討論演算法,兒子建議我參考一下AlphaGo的原理,發給我參考資料看了一下,感覺很受啟發。 一、AlphaGo的數學模型 1.1 圍棋問題的本質 圍棋問題本質上是一個數據分類問題。 圍棋問題可以這樣描述:給你一個圍棋的佈局,求出最佳落子位置。換句話講: 輸
深度學習CNN演算法原理
深度學習CNN演算法原理 一 卷積神經網路 卷積神經網路(CNN)是一種前饋神經網路,通常包含資料輸入層、卷積計算層、ReLU啟用層、池化層、全連線層(INPUT-CONV-RELU-POOL-FC),是由卷積運算來代替傳統矩陣乘法運算的神經網路。CNN常用於影象的資料處理,常用的LenNe
分享《深度學習與計算機視覺演算法原理框架應用》《大資料架構詳解從資料獲取到深度學習》PDF資料集
下載:https://pan.baidu.com/s/12-s95JrHek82tLRk3UQO_w 更多資料分享:http://blog.51cto.com/3215120 《深度學習與計算機視覺 演算法原理、框架應用》PDF,帶書籤,347頁。《大資料架構詳解:從資料獲取到深度學習》PDF,帶書籤,3
分享《深度學習與計算機視覺演算法原理框架應用》PDF《大資料架構詳解從資料獲取到深度學習》PDF +資料集
下載:https://pan.baidu.com/s/12-s95JrHek82tLRk3UQO_w 更多分享資料:https://www.cnblogs.com/javapythonstudy/ 《深度學習與計算機視覺 演算法原理、框架應用》PDF,帶書籤,347頁。《大資料架構詳解:從資料獲取到深度學
深度學習之神經網路(CNN/RNN/GAN)演算法原理+實戰目前最新
第1章 課程介紹 深度學習的導學課程,主要介紹了深度學習的應用範疇、人才需求情況和主要演算法。對課程章節、課程安排、適用人群、前提條件以及學習完成後達到的程度進行了介紹,讓同學們對本課程有基本的認識。 1-1 課程導學 第2章 神經網路入門 本次實戰課程的入門課程。對機器學習和深度學習做了引入
深度學習之目標檢測常用演算法原理+實踐精講
第1章 課程介紹本章節主要介紹課程的主要內容、核心知識點、課程涉及到的應用案例、深度學習演算法設計通用流程、適應人群、學習本門課程的前置條件、學習後達到的效果等,幫助大家從整體上了解本門課程的整體脈絡。 第2章 目標檢測演算法基礎介紹本章節主要介紹目標檢測演算法的基本概念、傳統的目標檢測演算法、目前深度學習
深度學習之目標檢測常用演算法原理+實踐精講 YOLO / Faster RCNN / SSD / 文字檢測 / 多工網路
深度學習之目標檢測常用演算法原理+實踐精講 YOLO / Faster RCNN / SSD / 文字檢測 / 多工網路 資源獲取連結:點選這裡 第1章 課程介紹 本章節主要介紹課程的主要內容、核心知識點、課程涉及到的應用案例、深度學習演算法設計通用流程、適應人群、學習本門
NIN 演算法原理解讀
NIN (Network In Network) Network In Network 論文Network In Network(Min Lin, ICLR2014). 傳統CNN使用的線性濾波器是一種廣義線性模型(Generalized linear model,GLM)。所以用CNN
基於深度學習的文字分類6大演算法-原理、結構、論文、原始碼打包分享
導讀:文字分類是NLP領域一項基礎工作,在工業界擁有大量且豐富的應用場景。傳統的文字分類需要依賴很多詞法、句法相關的human-extracted feature,自2012年深度學習技術快速發展之後,尤其是迴圈神經網路RNN、卷積神經網路CNN在NLP領域逐漸獲得廣
深度學習之神經網路(CNN/RNN/GAN) (演算法原理+實戰) 完整版下載
第1章 課程介紹 深度學習的導學課程,主要介紹了深度學習的應用範疇、人才需求情況和主要演算法。對課程章節、課程安排、適用人群、前提條件以及學習完成後達到的程度進行了介紹,讓同學們對本課程有基本的認識。 第2章 神經網路入門 本次實戰課程的入門課程。對機器學習和深
推薦系統遇上深度學習(二十)--貝葉斯個性化排序(BPR)演算法原理及實戰
原創:石曉文 小小挖掘機 2018-06-29推薦系統遇上深度學習系列:排序推薦演算法大體上可以分為三類,第一類排序演算法類別是點對方法(Pointwise Approach),這類演算法將排序問題被轉化為分類、迴歸之類的問題,並使用現有分類、迴歸等方法進行實現。第二類排序演算法是成對
深度學習之神經網路(CNN/RNN/GAN) (演算法原理+實戰)完整版
第1章 課程介紹 深度學習的導學課程,主要介紹了深度學習的應用範疇、人才需求情況和主要演算法。對課程章節、課程安排、適用人群、前提條件以及學習完成後達到的程度進行了介紹,讓同學們對本課程有基本的認識。 1-1 課程導學 第2章 神經網路入門 本次實戰課程的入門課程。對機器學
深度學習演算法原理——神經網路的基本原理
一、神經網路 1、神經元概述 神經網路是由一個個的被稱為“神經元”的基本單元構成,單個神經元的結構如下圖所示: 對於上述的神經元,其輸入為x1x1,x2x2,x3x3以及截距+1+1,其輸出為: hW,b(x)=f(WTx)=f(∑i
佛爺芸: 深度學習演算法原理與應用系列---深度學習介紹
機器學習演算法已經基本學習完了,在這一系列,佛爺將開始著手學習深度學習的各種演算法和應用,由於本身難度偏大,我會不定期的更新,基本清楚和更加深入的研究深度學習。程式碼方面我基本會使用Tensorf
訊息佇列Kafka高可靠性原理深度解讀上篇
1 概述 Kakfa起初是由LinkedIn公司開發的一個分散式的訊息系統,後成為Apache的一部分,它使用Scala編寫,以可水平擴充套件和高吞吐率而被廣泛使用。目前越來越多的開源分散式處理系統如Cloudera、Apache Storm、Spark等都支援與Kafka整合。 Kafka憑藉著自身
推薦系統遇上深度學習(二十)-貝葉斯個性化排序演算法原理及實戰
排序推薦演算法大體上可以分為三類,第一類排序演算法類別是點對方法(Pointwise Approach),這類演算法將排序問題被轉化為分類、迴歸之類的問題,並使用現有分類、迴歸等方法進行實現。第二類排序演算法是成對方法(Pairwise Approach),在序列方法中
深度學習演算法原理——Softmax Regression
一、Logistic迴歸簡介 Logistic迴歸是解決二分類問題的分類演算法。假設有mm個訓練樣本{(x(1),y(1)),(x(2),y(2)),⋯,(x(m),y(m))}{(x(1),y(1)),(x(2),y(2)),⋯,(x(m),y(m))},對
深度解讀最流行的優化算法:梯度下降
example 分別是 課程 拓展 高斯分布 正則 當前時間 lam 選擇 深度解讀最流行的優化算法:梯度下降 By 機器之心2016年11月21日 15:08 梯度下降法,是當今最流行的優化(optimization)算法,亦是至今最常用的優化神經網絡的方法。本文旨在