
Spark---What---Why---How!!!!!!!!
轉發:http://blog.csdn.net/bolu1234/article/details/51867099
Spark:大資料的電花火石!
2014年06月13日 23:19:10 anzhsoft 閱讀數:28516更多
所屬專欄: Spark技術內幕
版權宣告:本文為博主原創文章,未經博主允許不得轉載。 https://blog.csdn.net/anzhsoft2008/article/details/30272867
什麼是Spark?可能你很多年前就使用過Spark,反正當年我四六級單詞都是用的星火系列,沒錯,星火系列的洋名就是Spark。
當然這裡說的Spark指的是Apache Spark,Apache Spark™is a fast and general engine for large-scale data processing: 一種快速通用可擴充套件的資料分析引擎。如果想要搞清楚Spark是什麼,那麼我們需要知道它解決了什麼問題,還有是怎麼解決這些問題的。
Spark解決了什麼問題?
在這裡不得不提大資料,大資料有兩個根本性的問題,一個是資料很大,如何儲存?另外一個是資料很大,如何分析?畢竟分析大資料是為了改善產品的使用者體驗,從而獲取更多的價值。
對於第一個問題,開源社群給出的方案就是HDFS,一個非常優秀的分散式儲存系統。
對於第二個問題,在Hadoop之 後,開源社群推出了許多值得關注的大資料分析平臺。這些平臺範圍廣闊,從簡單的基於指令碼的產品到與Hadoop 類似的生產環境。Bashreduce在 Bash環境中的多個機器上執行 MapReduce 型別的操作,可以直接引用強大的Linux命令。GraphLab 也是一種MapReduce 抽象實現,側重於機器學習演算法的並行實現。還有Twitter 的 Storm(通過收購 BackType 獲得)。Storm 被定義為 “實時處理的 Hadoop”,它主要側重於流處理和持續計算。
Spark就是解決第二個問題的佼佼者。Why Spark?
Why Spark?
現在有很多值得關注的大資料分析平臺,那麼為什麼要選擇Spark呢?
速度
與Hadoop的MapReduce相比,Spark基於記憶體的運算比MR要快100倍;而基於硬碟的運算也要快10倍!

易用
Spark支援Java,Python和Scala。而且支援互動式的Python和Scala的shell,這意味這你可以非常方便的在這些shell中使用Spark叢集來驗證你的解決問題的方法,而不是像以前一樣,打包。。。這對於原型開發非常重要!
Hadoop的WorldCount的Mapper和Reducer加起來要20多行吧。Spark僅需要:
val file = spark.textFile("hdfs://...")
val counts = file.flatMap(line => line.split(" "))
.map(word => (word, 1))
.reduceByKey(_ + _)
counts.saveAsTextFile("hdfs://...") 甚至可以將它們放到一行。
通用性
Spark提供了All in One的解決方案!
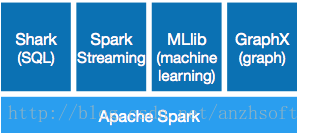
· Shark SQ:應用於即席查詢(Ad-hocquery)
· Spark Streaming:應用於流式計算
· MLlib:應用於機器學習
· GraphX: 應用於圖處理
Spark All In One的解決方案非常具有吸引力,畢竟任何公司都想要Unified的平臺去處理遇到的問題,可以減少開發和維護的人力成本和部署平臺的物力成本。
當然還有,作為All in One的解決方案,Spark並沒有以犧牲效能為代價。相反,在效能方面,Spark還有很大的優勢。
和Hadoop的整合
Spark可以使用YARN作為它的叢集管理器,並且可以處理HDFS的資料。這對於已經部署Hadoop叢集的使用者特別重要,畢竟不需要做任何的資料遷移就可以使用Spark的強大處理能力。Spark可以讀取HDFS,HBase, Cassandra等一切Hadoop的資料。
當然了對於沒有部署並且沒有計劃部署Hadoop叢集的使用者來說,Spark仍然是一個非常好的解決方法,它還支援standalone, EC2 和 Mesos。你只要保證叢集的節點可以訪問共享的內容,比如通過NFS你就可以非常容易的使用Spark!
How Spark?
Spark是如何做到呢?或者說Spark的核心是如何實現的?
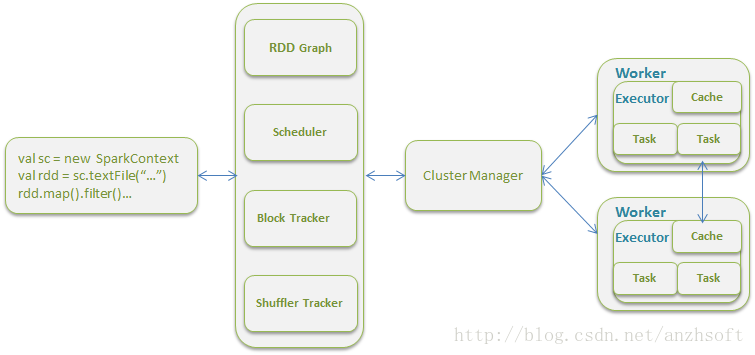
架構綜述
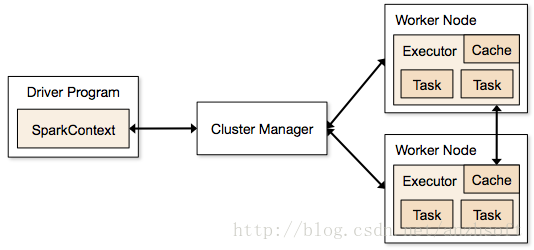
先說解釋一下上圖的術語:
Driver Program: 執行main函式並且新建SparkContext的程式。
SparkContext:Spark程式的入口,負責排程各個運算資源,協調各個Worker Node上的Executor。
Application: 基於Spark的使用者程式,包含了driver程式和叢集上的executor
Cluster Manager: 叢集的資源管理器(例如: Standalone,Mesos,Yarn)
Worker Node: 叢集中任何可以執行應用程式碼的節點
Executor: 是在一個worker node上為某應用啟動的一個程序,該程序負責執行任務,並且負責將資料存在記憶體或者磁碟上。每個應用都有各自獨立的executors
Task: 被送到某個executor上的工作單元
瞭解了各個術語的含義後,我們看一下一個使用者程式是如何從提交到最終到叢集上執行的:
1. SparkContext連線到ClusterManager,並且向ClusterManager申請executors。
2. SparkContext向executors傳送application code。
3. SparkContext向executors傳送tasks,executor會執行被分配的tasks。
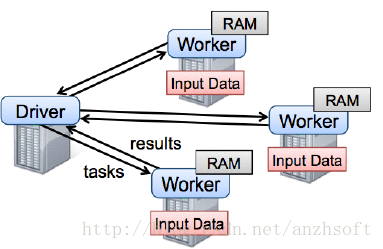
執行時的狀態如下圖:
Spark為什麼這麼快?
首先看一下為什麼MapReduce那麼慢。速度可能是MapReduce最被人們詬病的地方。傳統的MapReduce框架慢在哪裡。
基於記憶體的計算式Spark速度很快的原因之一。Spark的運算模型也是它出色效能的重要保障。Spark的關鍵運算元件如下圖。
什麼是RDD
RDD是Spark的基石,也是Spark的靈魂。說Spark不得不提RDD,那麼RDD(Resilient Distributed Dataset,彈性分散式資料集)是什麼呢?當然了,論文Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing是瞭解RDD必不可少的,它從學術,實現給出了什麼是RDD。下面是從RDD的實現原始碼的註釋中說明了RDD的特性。
- A list of partitions
- A function for computing each split
- A list of dependencies on other RDDs
- Optionally, a Partitioner for key-value RDDs (e.g. to say that the RDD is hash-partitioned)
- Optionally, a list of preferred locations to compute each split on (e.g. block locations for an HDFS file)
接著把對應的實現介面的原始碼貼一下,以方便去原始碼中查詢RDD的核心框架:
- 分割槽 protected def getPartitions: Array[Partition]
- 依賴 protected def getDependencies: Seq[Dependency[_]] = deps
- 函式 def compute(split: Partition, context: TaskContext): Iterator[T]
- 最佳位置(可選) protected def getPreferredLocations(split: Partition): Seq[String] = Nil
- 分割槽策略(可選) @transient val partitioner: Option[Partitioner] = None
RDD的操作
RDD支援兩種操作:轉換(transformation)從現有的資料集建立一個新的資料集;而動作(actions)在資料集上執行計算後,返回一個值給驅動程式。 例如,map就是一種轉換,它將資料集每一個元素都傳遞給函式,並返回一個新的分佈資料集表示結果。另一方面,reduce是一種動作,通過一些函式將所有的元素疊加起來,並將最終結果返回給Driver程式。(不過還有一個並行的reduceByKey,能返回一個分散式資料集)
Spark中的所有轉換都是惰性的,也就是說,他們並不會直接計算結果。相反的,它們只是記住應用到基礎資料集(例如一個檔案)上的這些轉換動作。只有當發生一個要求返回結果給Driver的動作時,這些轉換才會真正執行。這個設計讓Spark更加有效率的執行。例如,我們可以實現:通過map建立的一個新資料集,並在reduce中使用,最終只返回reduce的結果給driver,而不是整個大的新資料集。
預設情況下,每一個轉換過的RDD都會在你在它之上執行一個動作時被重新計算。不過,你也可以使用persist(或者cache)方法,持久化一個RDD在記憶體中。在這種情況下,Spark將會在叢集中,儲存相關元素,下次你查詢這個RDD時,它將能更快速訪問。在磁碟上持久化資料集,或在叢集間複製資料集也是支援的,詳盡的RDD操作請參見 RDD API doc。
資料的本地性
資料本地性的意思就是儘量的避免資料在網路上的傳輸。Hadoop的MR之所以慢,頻繁的讀寫HDFS是原因之一,為了解決這個問題,Spark將資料都放在了記憶體中(當然這是理想的情況,當記憶體不夠用時資料仍然需要寫到檔案系統中)。但是如果資料需要在網路上傳輸,也會導致大量的延時和開銷,畢竟disk IO和network IO都是叢集的昂貴資源。
資料本地性是儘量將計算移到資料所在的節點上進行。畢竟移動計算要比移動資料所佔的網路資源要少得多。而且,由於Spark的延時排程機制,使得Spark可以在更大的程度上去做優化。比如,擁有資料的節點當前正被其他的task佔用,那麼這種情況是否需要將資料移動到其他的空閒節點呢?答案是不一定。因為如果預測當前節點結束當前任務的時間要比移動資料的時間還要少,那麼排程會等待,直到當前節點可用。

Spark的現狀與未來
值得慶祝的里程碑:
· 2009:Spark誕生於AMPLab
· 2010:開源
· 2013年6月:Apache孵化器專案
· 2014年2月:Apache頂級專案
· Hadoop最大的廠商Cloudera宣稱加大Spark框架的投入來取代Mapreduce
· Hadoop廠商MapR投入Spark陣營
· Apache mahout放棄MapReduce,將使用Spark作為後續運算元的計算平臺
· 2014年5月30日Spark1.0.0釋出
進一步學習
熟讀原始碼永遠是知道真相的唯一方式。尤其是Scala語言是如此簡潔,如此易讀。當然了在這之前最好還是讀一下論文,尤其是RDD的,這樣可以讓你有個整體把握整個系統的能力。
- Shark: SQL and Rich Analytics at Scale. Reynold Xin, Joshua Rosen, Matei Zaharia, Michael J. Franklin, Scott Shenker, Ion Stoica. Technical Report UCB/EECS-2012-214. November 2012.
- Discretized Streams: An Efficient and Fault-Tolerant Model for Stream Processing on Large Clusters. Matei Zaharia, Tathagata Das, Haoyuan Li, Scott Shenker, Ion Stoica. HotCloud 2012. June 2012.
- Shark: Fast Data Analysis Using Coarse-grained Distributed Memory (demo). Cliff Engle, Antonio Lupher, Reynold Xin, Matei Zaharia, Haoyuan Li, Scott Shenker, Ion Stoica. SIGMOD 2012. May 2012. Best Demo Award.
- Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing. Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael J. Franklin, Scott Shenker, Ion Stoica. Technical Report UCB/EECS-2011-82. July 2011.
- Spark: Cluster Computing with Working Sets. Matei Zaharia, Mosharaf Chowdhury, Michael J. Franklin, Scott Shenker, Ion Stoica. HotCloud 2010. June 2010.
敬請期待
原始碼之前,了無真相。接下來,我將從原始碼分析的角度,深入Spark內部,來系統學習Spark,學習它的架構,學習它的實現。
請您支援:
如果你看到這裡,相信這篇文章對您有所幫助。如果是的話,請為本文投一下票吧: 點選投票,多謝。