機器學習之sk-learn庫
1.1 總體說明
Scikit-Learn是基於Python的開源機器學習模組,最早由David Cournapeau在2007年發起的,目前也是由社群志願者進行維護。官方網站是:http://scikit-learn.org/stable/,在上面可以找到相關的資源、模組下載、文件、例程等。
Scikit-Learn的安裝需要numpy、scipy、matplotlib等模組,Windows系統可以在http://www.lfd.uci.edu/~gohlke/pythonlibs直接下載編譯好的安裝包以及依賴包,也可以到網址下載http://sourceforge.jp/projects/sfnet_scikit-learn/
Scikit-learn的基本功能主要分為六個部分:分類、迴歸、聚類、資料降維、模型選擇、資料預處理。對於具體的機器學習問題,通常可以分為三個步驟,資料準備與預處理,模型選擇與訓練,模型驗證與引數調優。
1.2 代表性函式使用介紹
1.載入資料
#coding:utf-8 import numpy as np import urllib url = 'http://archive.ics.uci.edu/ml/machine-learning-databases/00396/Sales_Transactions_Dataset_Weekly.csv' raw_data = urllib.urlopen(url) dataset = np.loadtxt(raw_data,delimiter=",",skiprows=1,usecols=(1,2,3,4,5,6,7,8,54)) X = dataset[:,0:7] Y = dataset[:,8]
我們要使用該資料集作為例子,將特徵矩陣作為x,目標變數作為y
2.資料歸一化
大多數機器學習演算法中的梯度方法對於資料的縮放和尺度都是很敏感的,在開始跑演算法之前,我們應該進行歸一化或標準化的過程,這使得特徵資料縮放到0-1範圍。scikit-learn提供了歸一化的方法:
from sklearn import preprocessing
normalized_X = preprocessing.normalize(X)
standardized_X = preprocessing.scale(X)3.特徵選擇
在解決一個實際問題的過程中,選擇適合的特徵或者構建特徵的能力特別重要。這稱為特徵選擇或者特徵工程。
特徵選擇是一個很需要創造力的過程,更多的依賴於直覺和專業知識,並且有很多現成的演算法來進行特徵選擇。下面是使用樹演算法計算特徵:
from sklearn import metrics
from sklearn.ensemble import ExtraTreesClassifier
model = ExtraTreesClassifier()
model.fit(X,Y)
print(model.feature_importances_)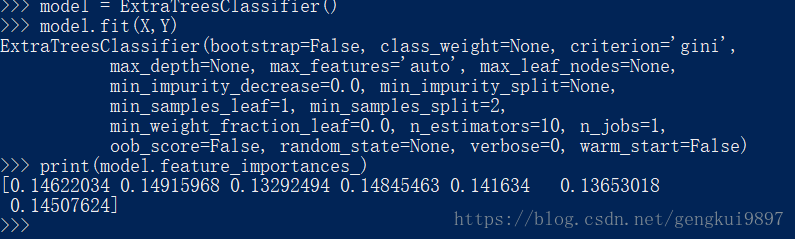
1.3 機器學習演算法的使用
1.邏輯迴歸
大多數問題都可以歸結為二元分類問題。這個演算法的優點是可以給出資料所在類別的概率。
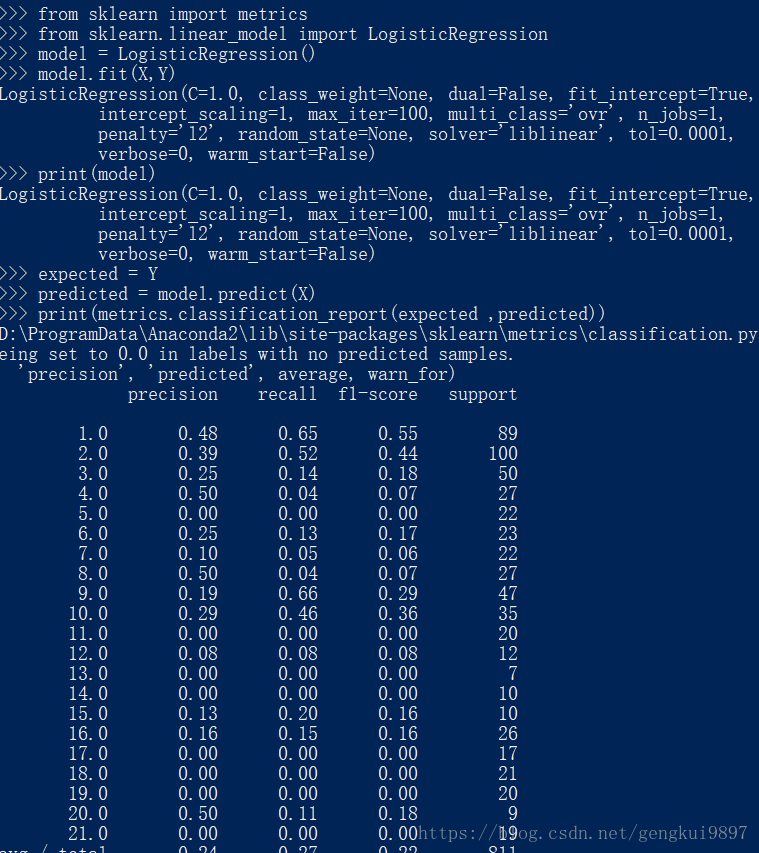
from sklearn import metrics
from sklearn.linear_model import LogisticRegression
model = LogisticRegression()
model.fit(X,Y)
print(model)
expected = Y
predicted = model.predict(X)
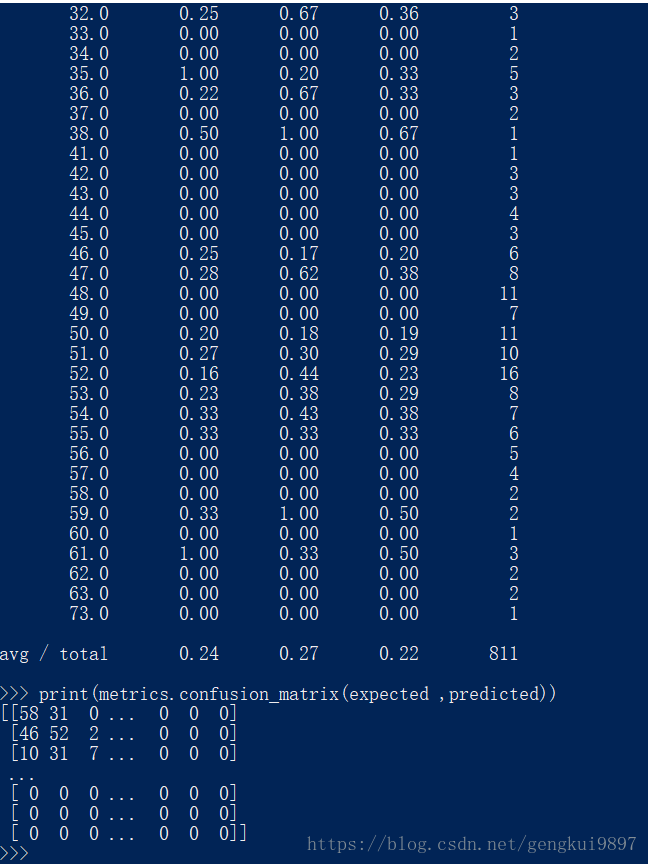
print(metrics.classification_report(expected ,predicted))
print(metrics.confusion_matrix(expected ,predicted))
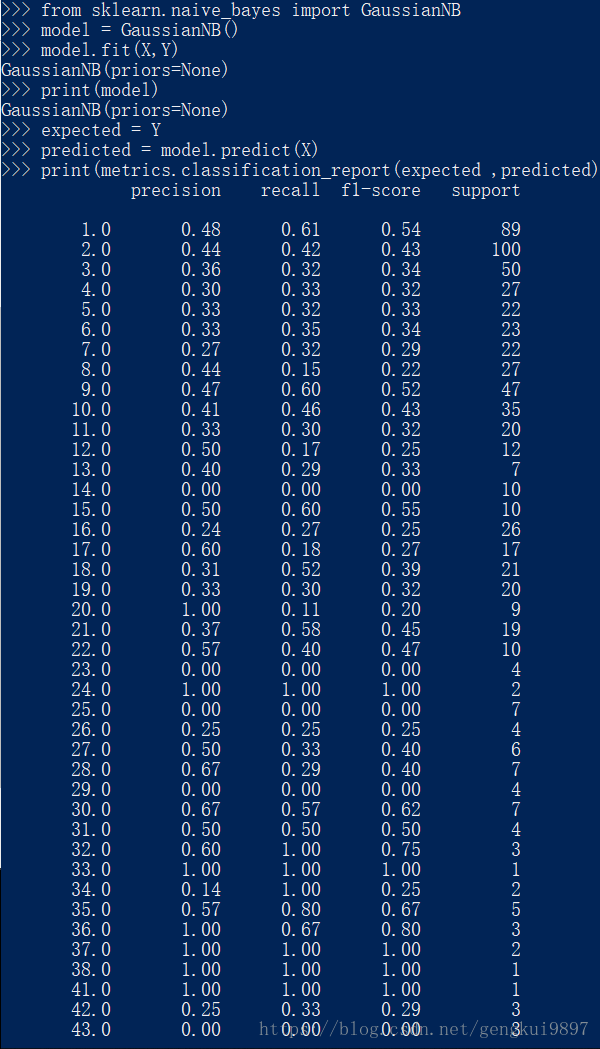
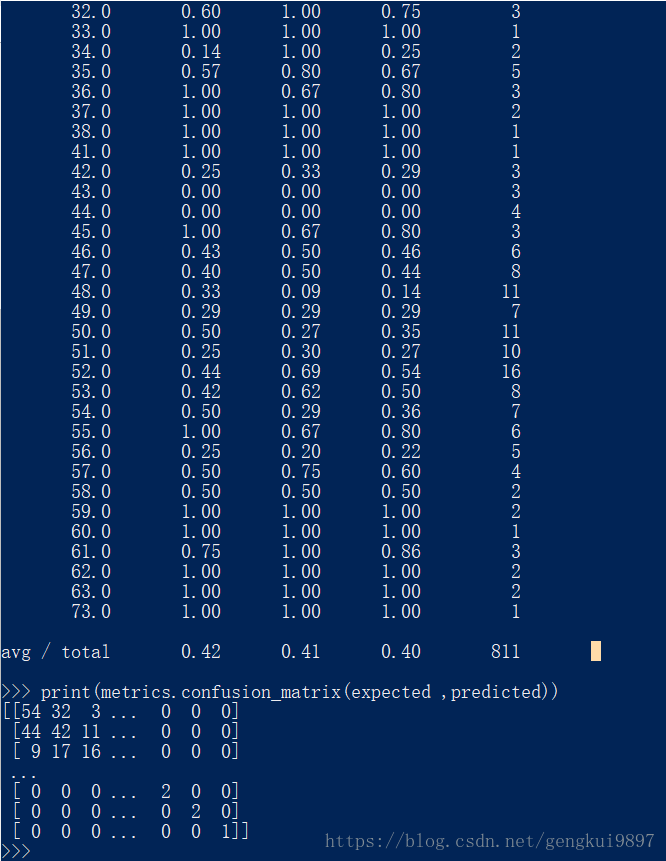
2.樸素貝葉斯
這也是著名的機器學習演算法,該方法的任務是還原訓練樣本資料的分佈密度,其在多類別分類中有很好的效果。
from sklearn import metrics
from sklearn.naive_bayes import GaussianNB
model = GaussianNB()
model.fit(X,Y)
print(model)
expected = Y
predicted = model.predict(X)
print(metrics.classification_report(expected ,predicted))
print(metrics.confusion_matrix(expected ,predicted))
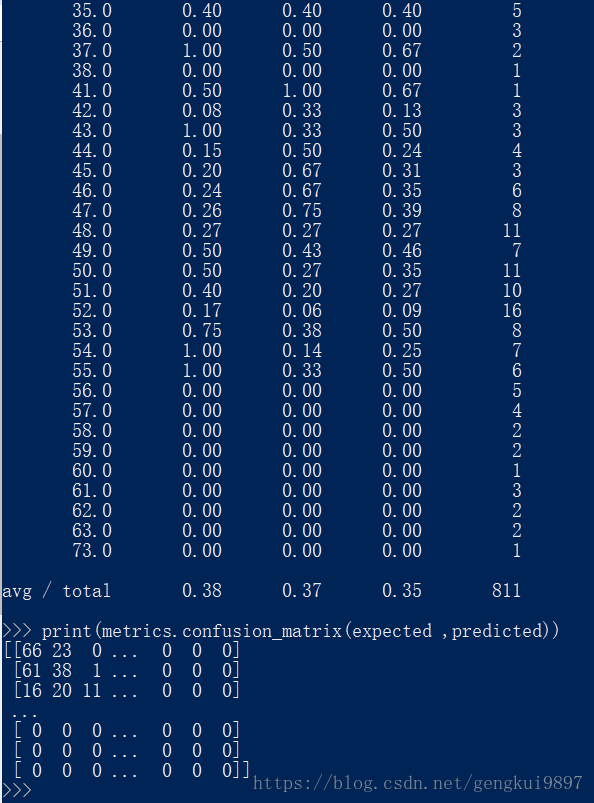
3.k近鄰
k近鄰演算法常常被用作分類演算法的一部分,比如可以用它來評估特徵,在特徵選擇上我們可以用到它。
from sklearn import metrics
from sklearn.neighbors import KNeighborsClassifier
model = KNeighborsClassifier()
model.fit(X,Y)
print(model)
expected = Y
predicted = model.predict(X)
print(metrics.classification_report(expected ,predicted))
print(metrics.confusion_matrix(expected ,predicted))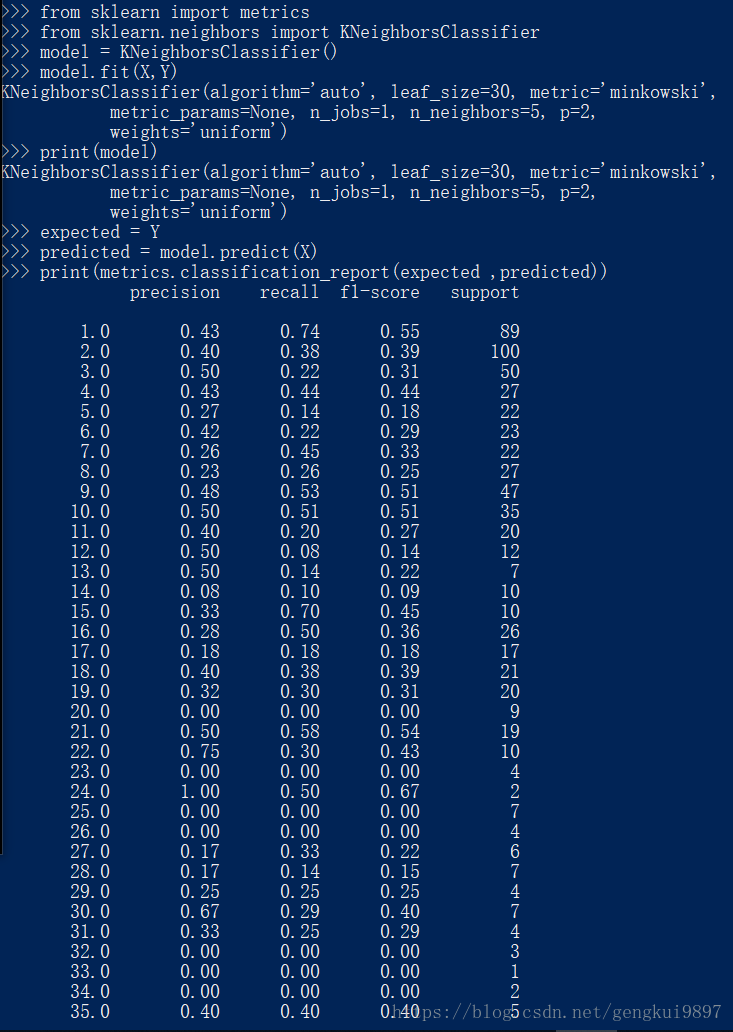
4.決策樹
分類與迴歸樹(CART)演算法常用於特徵含有類別資訊的分類或者回歸問題,這種方法非常適用於多分類情況。
from sklearn import metrics
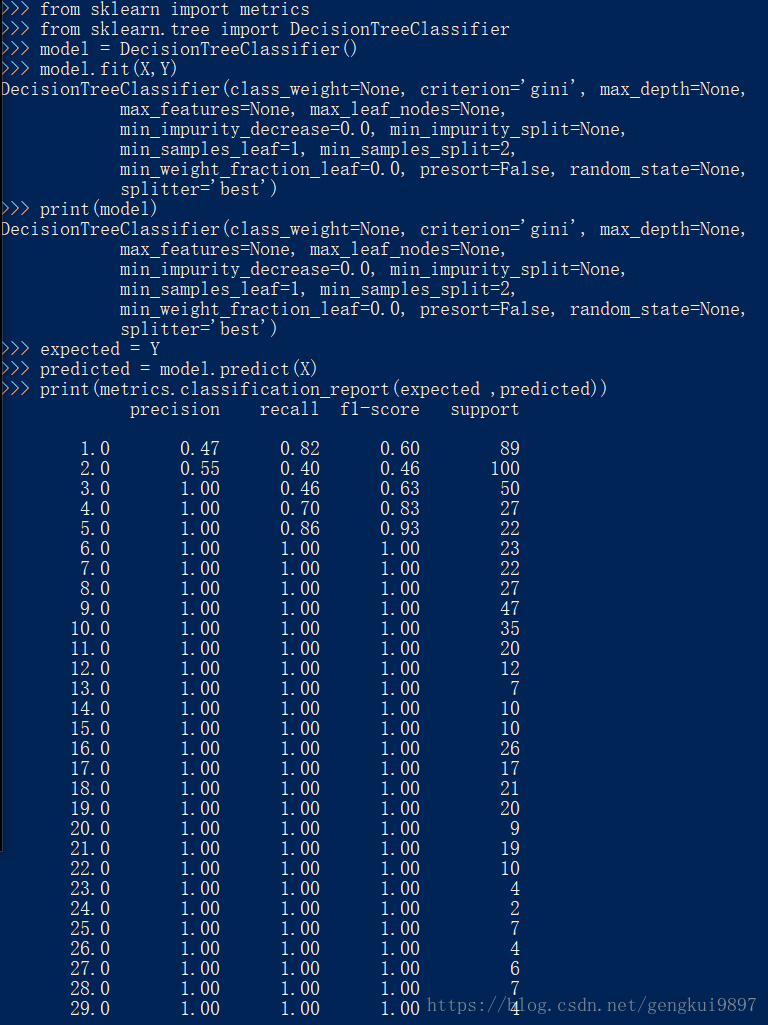
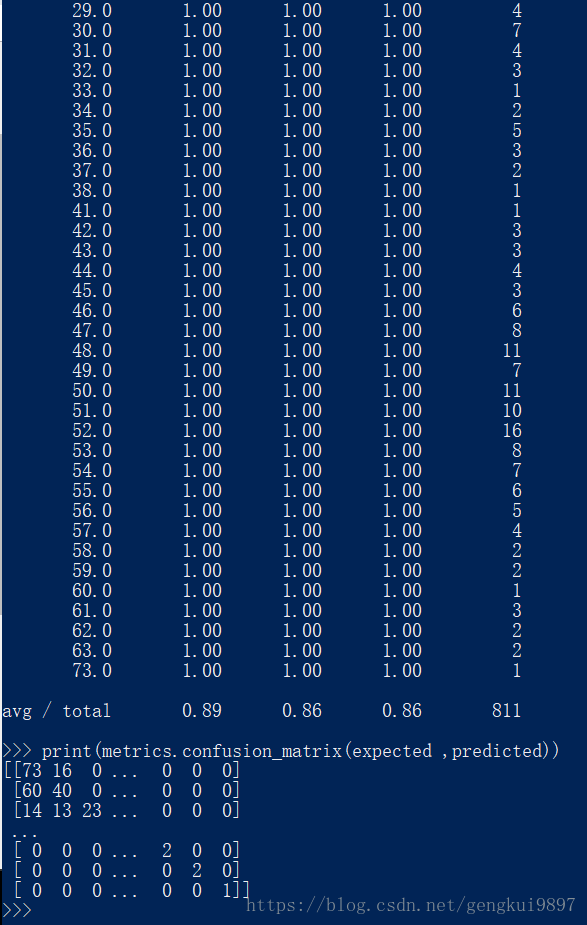
from sklearn.tree import DecisionTreeClassifier
model = DecisionTreeClassifier()
model.fit(X,Y)
print(model)
expected = Y
predicted = model.predict(X)
print(metrics.classification_report(expected ,predicted))
print(metrics.confusion_matrix(expected ,predicted))
5.支援向量機
SVM是非常流行的機器學習演算法,主要用於分類問題,如同邏輯迴歸問題,它可以使用一對多的方法進行多類別的分類。
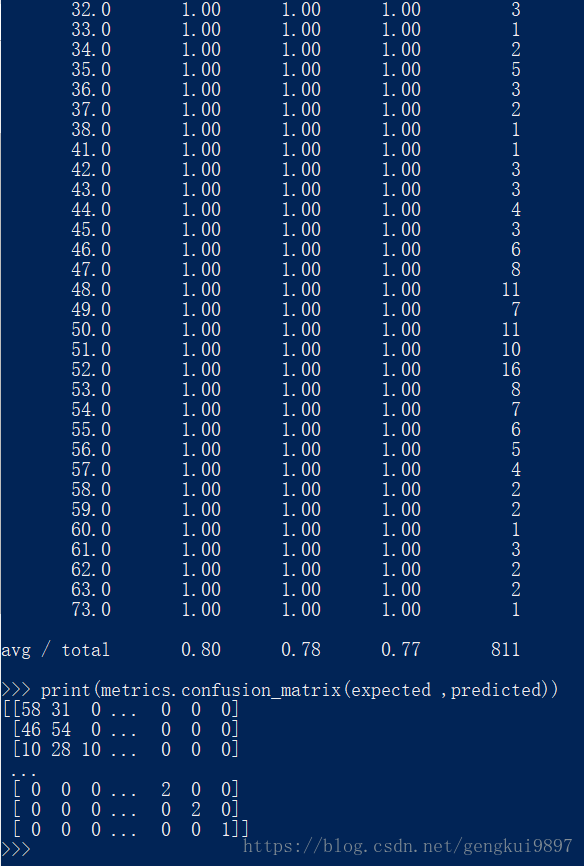
from sklearn import metrics
from sklearn.svm import SVC
model = SVC()
model.fit(X,Y)
print(model)
expected = Y
predicted = model.predict(X)
print(metrics.classification_report(expected ,predicted))
print(metrics.confusion_matrix(expected ,predicted))

除了分類和迴歸演算法外,scikit-learn提供了更加複雜的演算法,比如聚類演算法,還實現了演算法組合的技術,如Bagging和Boosting演算法。
1.4 如何優化演算法引數
一項更加困難的任務是構建一個有效的方法用於選擇正確的引數,我們需要使用搜索的方法來確定引數。scikit-learn提供了實現這一目標的函式。
下面例子是一個進行正則引數選擇的程式:
import numpy as np
from sklearn.linear_model import Ridge
from sklearn.grid_search import GridSearchCV
alphas = np.array([1,0.1,0.01,0.001,0.0001,0])
model = Ridge()
grid = GridSearchCV(estimator=model,param_grid=dict(alpha=alphas))
grid.fit(X,Y)
print(grid)
print(grid.best_score_)
print(grid.best_estimator_.alpha)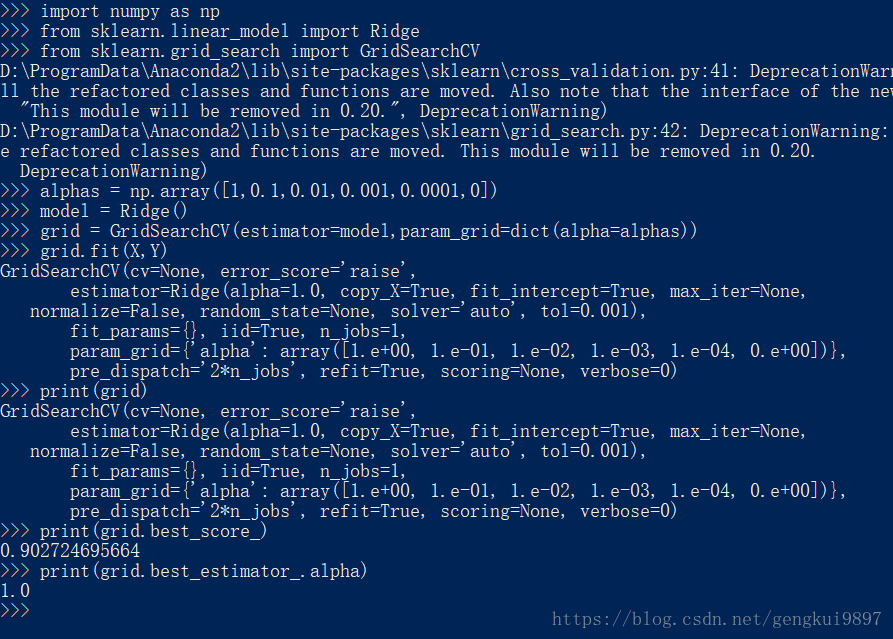
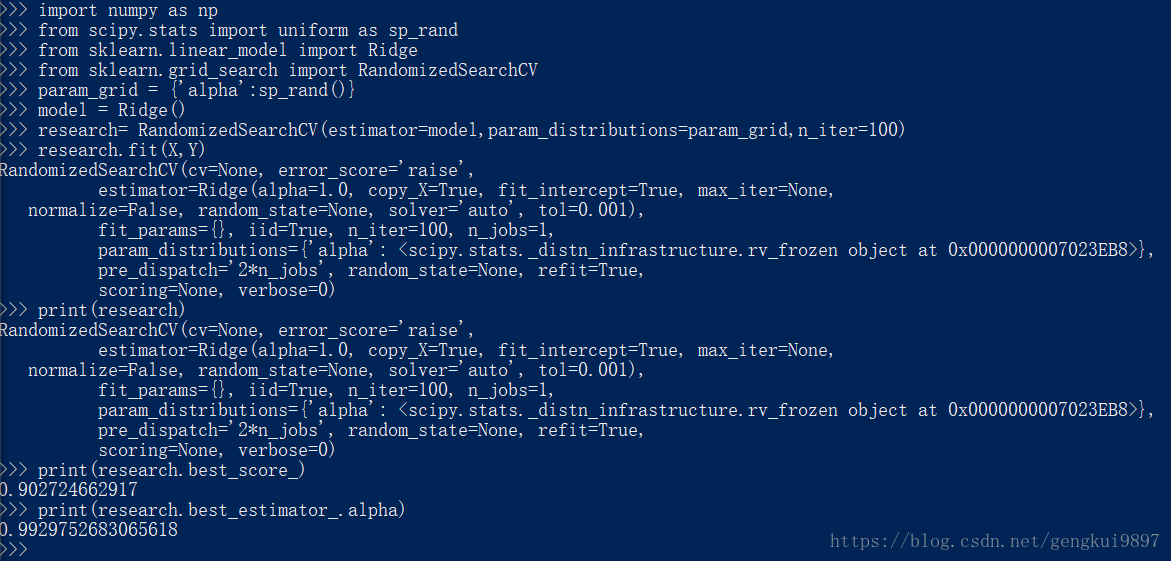
有時隨機從給定的區間中選擇引數是很有效的方法,然後根據這些引數來評估演算法的效果,進而選擇最佳的那個。
import numpy as np
from scipy.stats import uniform as sp_rand
from sklearn.linear_model import Ridge
from sklearn.grid_search import RandomizedSearchCV
param_grid = {'alpha':sp_rand()}
model = Ridge()
research= RandomizedSearchCV(estimator=model,param_distributions=param_grid,n_iter=100)
research.fit(X,Y)
print(research)
print(research.best_score_)
print(research.best_estimator_.alpha)