
樹的三種儲存結構(轉)
阿新 • • 發佈:2018-11-11
出處為: http://blog.csdn.net/smile_from_2015/article/details/63687696
6.2樹的定義
之前我們一直在談的是一對一的線性結構,可現實中,還有很多一對多的情況需要處理,所以我們需要研究這種一對多的資料結構----"樹",考慮它的各種特性,來解決我們在程式設計中碰到的相關問題。 樹(Tree)是n(n>=0)個結點的有限集。n=0時稱為空樹。在任意一棵非空樹中:(1)有且僅有一個特定的稱為根(Root)的結點;(2)當n>1時,其餘結點可分為m(m>O)個互不相交的有限集T1、T2、……、 Tm,其中每一個集合本身又是一棵樹,並且稱為根的子樹(SubTree),如圖6-2-1所示。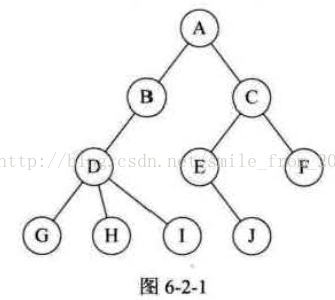
樹的定義其實就是我們在講解棧時提到的遞迴的方法。也就是在樹的定義之中還用到了樹的概念,這是一種比較新的定義方法。圖6-2-2的子樹T1和子樹T2就是根結點A的子樹。當然,D、G、H、I組成的樹又是B為結點的子樹,E、J組成的樹是C為結點的子樹。
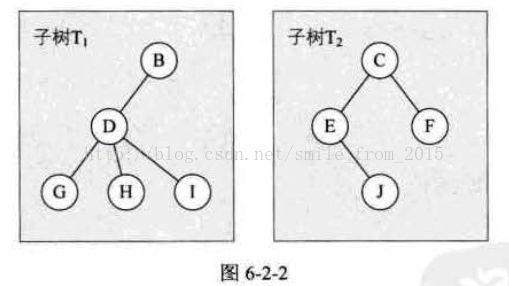
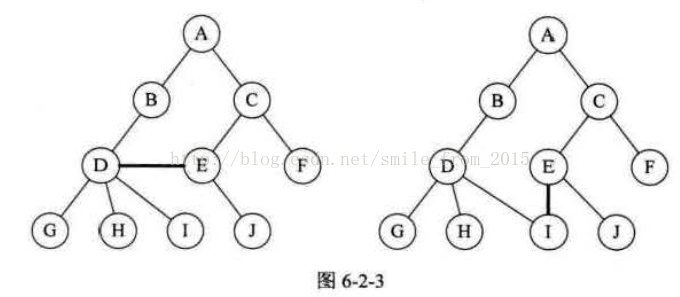
對於樹的定義還需要強調兩點: 1.n>0時根結點是唯一的,不可能存在多個根結點,別和現實中的大樹混在一起,現實中的樹有很多根鬚,那是真實的樹,資料結構中的樹是隻能有一個根結點。 2.m>0時,子樹的個數沒有限制,但它們一定是互不相交的。像圖6-2-3中的兩個結構就不符合樹的定義,因為它們都有相交的子樹。
6.2.1 結點分類
樹的結點包含一個數據元素及若干指向其子樹的分支。 結點擁有的子樹數稱為結點的度(Degree) 。 度為0的結點稱為葉結點(Leaf)或終端結點;度不為0的結點稱為非終端結點或分支結點。除根結點之外,分支結點也稱為內部結點。樹的度是樹內各結點的度的最大值 。如圖6-2-4所示,因為這棵樹結點的度的最大值是結點D的度,為3,所以樹的度也為3。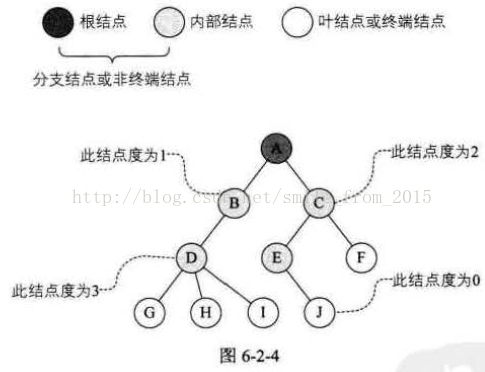
6.2.2 結點間關係
結點的子樹的根稱為該結點的孩子(Child) ,相應地, 該結點稱為孩子的雙親(Parent) 。恩,為什麼不是父或母,叫雙親呢?對於結點來說其父母同體,唯一的一個,所以只能把它稱為雙親了。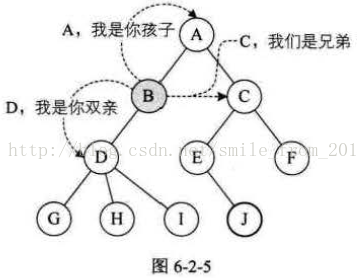
6.2.3 樹的其他相關概念
結點的層次(Level)從根開始定義起,根為第一層,根的孩子為第二層。 若某結點在第l層,則其子樹的根就在第1+1層。 其雙親在同一層的結點直為堂兄弟 。顯然圖6-2-6中的D、E、F是堂兄弟,而G、H、I、J也是。 樹中結點的最大層次稱為樹的深度(Depth)或高度 ,當前樹的深度為4。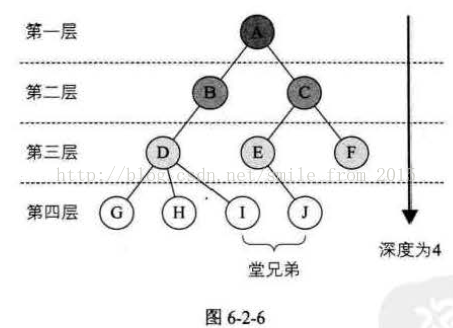
如果將樹中結點的各子樹看成從左至右是有次序的,不能互換的,則稱該樹為有序樹,否則稱為無序樹。 森林(Forest)是m(m>0)棵互不相交的樹的集合。對樹中每個結點而言,其子樹的集合即為森林。對於圖6-2-1中的樹而言,圖6-2-2中的兩棵子樹其實就可以理解為森林。 對比線性表與樹的結構,它們有很大的不同,如圖6-2-7所示。

6.4樹的儲存結構
說到儲存結構,就會想到我們前面章節講過的順序儲存和鏈式儲存兩種結構。 先來看看順序儲存結構,用一段地址連續的儲存單元依次儲存線性表的資料元素。這對於線性表來說是很自然的,對於樹這樣一多對的結構呢? 樹中某個結點的孩子可以有多個,這就意味著,無論按何種順序將樹中所有結點儲存到陣列中,結點的儲存位置都無法直接反映邏輯關係,你想想看,資料元素挨個的儲存,誰是誰的雙親,誰是誰的孩子呢?簡單的順序儲存結構是不能滿足樹的實現要求的。 不過充分利用順序儲存和鏈式儲存結構的特點,完全可以實現對樹的儲存結構的表示。我們這裡要介紹三種不同的表示法: 雙親表示法、孩子表示法、孩子兄弟表示法 。6.4.1 雙親表示法
我們人可能因為種種原因,沒有孩子,但無論是誰都不可能是從石頭裡蹦出來的,孫悟空顯然不能算是人,所以是人一定會有父母。樹這種結構也不例外,除了根結點外,其餘每個結點,它不一定有孩子,但是一定有且僅有一個雙親。 我們假設以一組連續空間儲存樹的結點,同時在每個結點中,附設一個指示器指示其雙親結點到連結串列中的位置。也就是說,每個結點除了知道自己是誰以外,還知道它的雙親在哪裡。它的結點結構為表6-4-1所示。
其中data是資料域,儲存結點的資料資訊。而parent是指標域,儲存該結點的雙親在陣列中的下標。 由於根結點是沒有雙親的,所以我們約定根結點的位置域設定為-1,這也就意味著,我們所有的結點都存有它雙親的位置。如圖6-4-1中的樹結構和表6-4-2中的樹雙親表示所示。
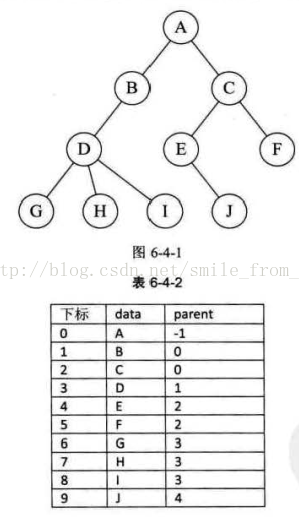
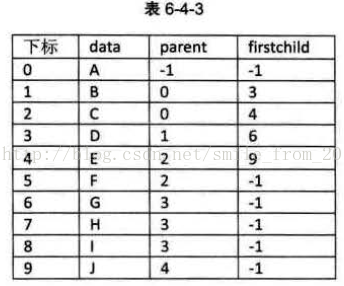
這樣的儲存結構,我們可以根據結點的parent指標很容易找到它的雙親結點,所用的時間複雜度為O(1),直到parent為-1時,表示找到了樹結點的根。可如果我們要知道結點的孩子是什麼,對不起,請遍歷整個結構才行。 這真是麻煩,能不能改進一下呢? 當然可以。我們增加一個結點最左邊孩子的域,不妨叫它長子域,這樣就可以很容易得到結點的孩子。如果沒有孩子的結點,這個長子域就設定為-1,如表6-4-3所示。(表中下標為0的firstchild應該為1)
對於有0個或1個孩子結點來說,這樣的結構是解決了要找結點孩子的問題了。甚至是有2個孩子,知道了長子是誰,另一個當然就是次子了。 另外一個問題場景,我們很關注各兄弟之間的關係,雙親表示法無法體現這樣的關係,那我們怎麼辦?嗯,可以增加一個右兄弟域來體現兄弟關係,也就是說,每一個結點如果它存在右兄弟,則記錄下右兄弟的下標。同樣的,如果右兄弟不存在,則賦值為-1 ,如表6-4-4所示。
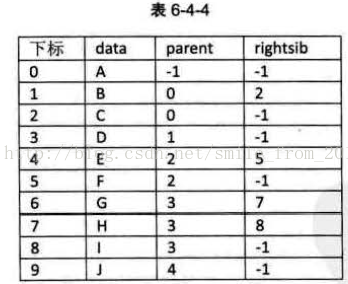
但如果結點的孩子很多,超過了2個。我們又關注結點的雙親、又關注結點的孩子、還關注結點的兄弟,而且對時間遍歷要求還比較高,那麼我們還可以把此結構擴充套件為有雙親域、長子域、再有右兄弟域。儲存結構的設計是一個非常靈活的過程。一個儲存結構設計得是否合理,取決於基於該儲存結構的運算是否適合、是否方便,時間複雜度好不好等。注意也不是越多越好,有需要時再設計相應的結構。就像再好昕的音樂,不停反覆聽上千遍也會膩味,再好看的電影,一段時間反覆看上百遍,也會無趣,你們說是吧?
6.4.2 孩子表示法
換一種完全不同的考慮方法 . 由於樹中每個結點可能有多棵子樹,可以考慮用多重連結串列,即每個結點有多個指標域,其中每個指標指向一棵子樹的根結點,我們把這種方法叫做多重連結串列表示法。不過,樹的每個結點的度,也就是它的孩子個數是不同的。所以可以設計兩種方案來解決。 方案一 一種是指標域的個數就等於樹的度,複習一下,樹的度是樹各個結點度的最大值。其結構如表6-4-5所示。
其中data是資料域。childl到childd是指標域,用來指向該結點的孩子結點。 對於圖6-4-1的樹來說,樹的度是3,所以我們的指標域的個數是3,這種方法實現如圖6-4-2所示。
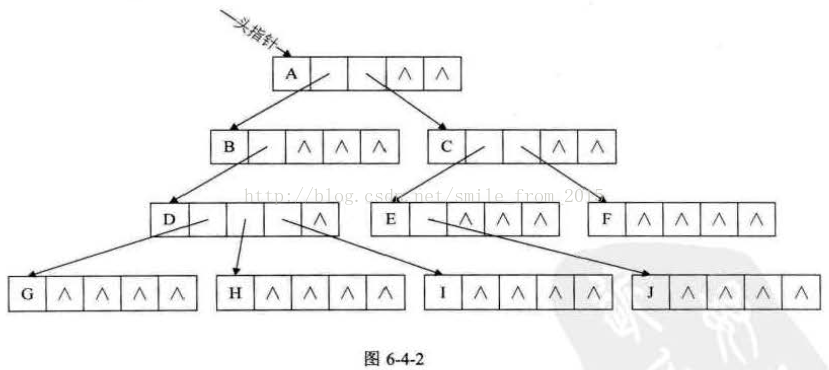
這種方法對於樹中各結點的度相差很大時,顯然是很浪費空間的,因為有很多的結點,它的指標域都是空的。不過如果樹的各結點度相差很小時,那就意味著開闢的空間被充分利用了,這時儲存結構的缺點反而變成了優點。 既然很多指標域都可能為空,為什麼不按需分配空間呢。於是我們有了第二種方案。 方案二 第二種方案每個結點指標域的個數等於該結點的度,我們專門取一個位置來儲存結點指標域的個數,其結構如表6-4-6所示。

其中data為資料域,degree為度域,也就是儲存該結點的孩子結點的個數,child1到childd為指標域,指向該結點的各個孩子的結點。 對於圖6-4-2的樹來說,這種方法實現如圖6-4-3所示。
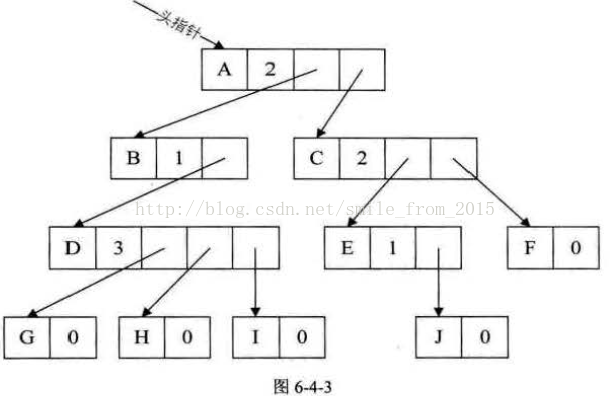
這種方法克服了浪費空間的缺點,對空間利用率是很高了,但是由於各個結點的連結串列是不相同的結構,加上要維護結點的度的數值,在運算上就會帶來時間上的損耗。 能否有更好的方法,既可以減少空指標的浪費又能使結點結構相同。 仔細觀察,我們為了要遍歷整棵樹,把每個結點放到一個順序儲存結構的陣列中是合理的,但每個結點的孩子有多少是不確定的,所以我們再對每個結點的孩子建立一個單鏈表體現它們的關係 。 這就是我們要講的孩子表示法。 具體辦法是,把每個結點的孩子結點排列起來,以單鏈表作儲存結構,則n個結點有n個孩子連結串列,如果是葉子結點則此單鏈表為空。然後n個頭指標又組成一個線性表,採用順序儲存結構,存放進一個一維陣列中 ,如圖6-4-4所示。
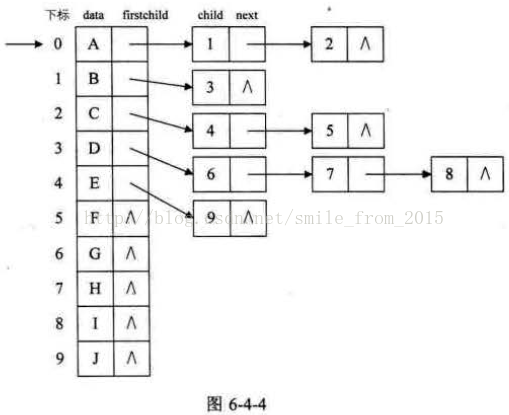
為此,設計兩種結點結構,一個是孩子連結串列的孩子結點,如表6-4-7所示。

其中child是資料域,用來儲存某個結點在表頭陣列中的下標。next是指標域,用來儲存指向某結點的下一個孩子結點的指標。 另一個是表頭陣列的表頭結點,如表6-4-8所示。

其中data是資料域,儲存某結點的資料資訊。firstchild是頭指標域,儲存該結點的孩子連結串列的頭指標。 這樣的結構對於我們要查詢某個結點的某個孩子,或者找某個結點的兄弟,只需要查詢這個結點的孩子單鏈表即可。對於遍歷整棵樹也是很方便的,對頭結點的陣列迴圈即可。 但是,這也存在著問題,我如何知道某個結點的雙親是誰呢?比較麻煩,需要整棵樹遍歷才行,難道就不可以把雙親表示法和孩子表示法綜合一下嗎?當然是可以。如圖6-4-5所示。
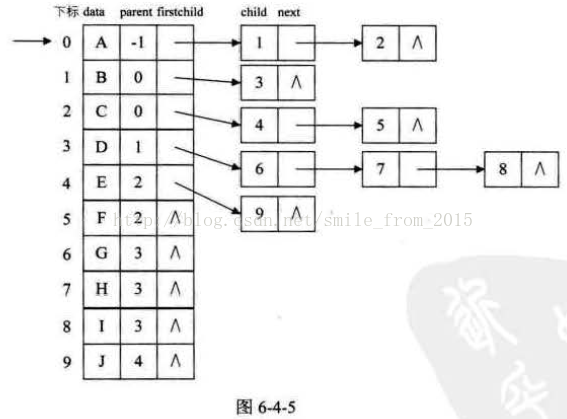
我們把這種方法稱為雙親孩子表示法 ,應該算是孩子表示法的改進。
6.4.3 孩子兄弟表示法
剛才我們分別從雙親的角度和從孩子的角度研究樹的儲存結構,如果我們從樹結點的兄弟的角度又會如何呢? 當然,對於樹這樣的層級結構來說,只研究結點的兄弟是不行的,我們觀察後發現,任意一棵樹,它的結點的第一個孩子如果存在就是唯一的,它的右兄弟如果存在也是唯一的。 因此,我們設定兩個指標,分別指向該結點的第一個孩子和此結點的右兄弟。結點結構如表6-4-9所示。
其中data是資料域,firstchild為指標域,儲存該結點的第一個孩子結點的儲存地址,rightsib是指標域,儲存該結點的右兄弟結點的儲存地址。 對於圖6-4-1的樹來說,這種方法實現的示意圖如圖6-4-6所示。
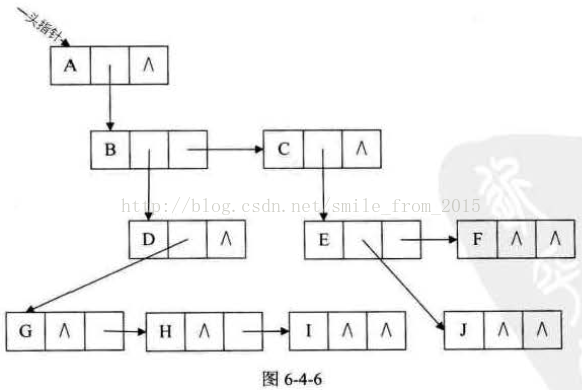
這種表示法,給查詢某個結點的某個孩子帶來了方便,只需要通過firstchild找到此結點的長子,然後再通過長子結點的rightsib找到它的二弟,接著一直下去,直到找到具體的孩子。當然,如果想找某個結點的雙親,這個表示法也是有做陷的,那怎麼辦呢? 對,如果真的有必要,完全可以再增加一個parent指標域來解決快速查詢雙親的問題,這裡就不再細談了。 其實這個表示法的最大好處是它把一棵複雜的樹變成了一棵二叉樹。我們把圖6-4-6變變形就成了圖6-4-7這個樣子。
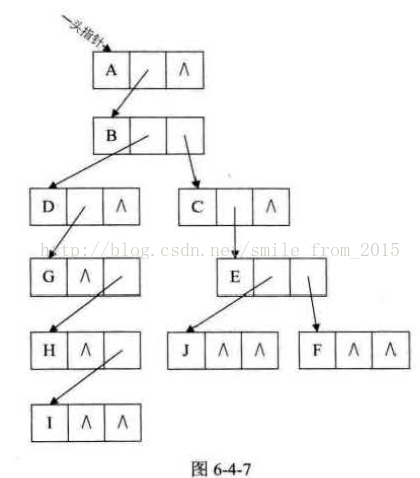
這樣就可以充分利用二叉樹的特性和演算法來處理這棵樹了。嗯?有人間,二叉樹是什麼?哈哈,別急,這正是我接下來要重點講的內容。 引用《大話資料結構》作者:程傑