
20172328 2018-2019《Java軟體結構與資料結構》第五週學習總結
20172328 2018-2019《Java軟體結構與資料結構》第五週學習總結
概述 Generalization
本週學習了第九章:排序與查詢,主要包括線性查詢和二分查詢演算法和幾種排序演算法。我們在軟體開發過程中要在某一組查詢某個特定的元素或要將某一組元素按特定順序排序,所以要學習排序與查詢的多種演算法。
教材學習內容總結 A summary of textbook
- 9.1查詢
- 查詢:是一個過程,即在某個專案組中尋找某一項指定目標元素,或者確定該指定目標並不存在。
- 高效的查詢會使該過程所做的比較操作次數最小化。
- 靜態方法:也稱為類方法,可以通過類名來呼叫,無需例項化該類的物件。 在方法宣告中,通過使用static修飾符就可以把他宣告為靜態的。
- 泛型方法:要建立一個泛型方法,只需要在方法頭的返回型別前插入一個泛型宣告即可:
public static <T extends Comparable<T>> Booolean linearSearch(T[] data,int min,int max,T target); - 這樣,就可以直接通過類名和要用來替換泛型的具體資料型別來呼叫靜態方法啦。
Searching.linearSearch(targetarray,min,max,target) - 線性查詢法
- 線性查詢法就是從頭開始查詢,與每一個列表中的元素進行比較,直到找到該目標元素或查詢到末尾還沒找到。
- 以下的方法實現了一個線性查詢。該方法返回一個布林值,若是true,便是找到該元素,否則為false,表示沒找到。
public static <T> boolean linearSearch(T[] data, int min, int max, T target) { int index = min; boolean found = false; while (!found && index <= max) { found = data[index].equals(target); index++; } return found; }
- 二分查詢法
- 二分查詢是從排序列表(查詢池是已排序的)的中間開始查詢,而不是從一端或者另一端的開始的。通過比較,確定可行候選項就又減少了一半的元素量,以相同的方式繼續查詢,直到最後找到目標元素或者不再存在可行候選項。
- 二分查詢的關鍵在於每次比較都會刪除一半的可行候選項。
- 以下的方法實現了一個二分查詢,其中的最大索引和最小索引定義了用於查詢(可行候選項)的陣列部分。
public static <T extends Comparable<T>>
boolean binarySearch(T[] data, int min, int max, T target)
{
boolean found = false;
int midpoint = (min + max) / 2; // determine the midpoint
if (data[midpoint].compareTo(target) == 0)
found = true;
else if (data[midpoint].compareTo(target) > 0)
{
if (min <= midpoint - 1)
found = binarySearch(data, min, midpoint - 1, target);
}
else if (midpoint + 1 <= max)
found = binarySearch(data, midpoint + 1, max, target);
return found;
}
}- 注意:在該演算法中,
midpoint = (min + max) / 2,當min+max所得數值是基數的時候,會自動轉化成int型別,直接忽略小數部分,也就是確定中點索引時選擇的是兩個中間值的第一個(小一點的)。 - 查詢演算法的比較
- 對於線性查詢和二分查詢,最好的情形都是目標元素恰好是我們考察的第一個元素,最壞的情形也都是目標不在該組中。因此,線性查詢的時間複雜度為O(n),二分查詢的時間複雜度為O(log2(n))。
- 當n比較大時,即元素特別多的時候,二分查詢就會大大提高效率。而當n比較小的時候,線性查詢更簡單好除錯且不需要排序,因此也在小型問題上常用線性查詢。
- 9.2排序
- 排序:基於某一標準,將某一組專案按照某個規定順序排列。
- 順序排序:通常使用一對巢狀迴圈對n個元素進行排序,需要大約n^2次比較。
- 對數排序:對n個元素進行排序通常大約需要nlog2(n)次比較。
- 常見的三種順序排序:
- ①選擇排序、②插入排序、③氣泡排序;
- 常見的兩種對數排序:
- ①快速排序、②歸併排序
- 選擇排序:通過反覆地找到某個最小(或者最大)元素,並把它放置到最後的位置來給元素排序。
- 插入排序:通過反覆地把某個元素插入到之前已經排序的子列表中,實現元素的排序。
- 氣泡排序:通過反覆的比較相鄰元素並交換他們,來給元素排序。
- 快速排序:通過把未排序元素分隔成兩個分割槽,然後遞迴地給每個分割槽排序。
快速排序的平均時間複雜度為O(nlogn)。在所有平均時間複雜度為O(nlogn)的演算法中,快速排序的平均效能是最好的。

- 在課本程式碼中,需要重點理解Partition方法
while (left < right)
{
// search for an element that is > the partition element
while (left < right && data[left].compareTo(partitionelement) <= 0)
left++;
// search for an element that is < the partition element
while (data[right].compareTo(partitionelement) > 0)
right--;
// swap the elements
if (left < right)
swap(data, left, right);
}
// move the partition element into place
swap(data, min, right);兩個內層while迴圈用於尋找位於錯誤分割槽的交換元素,第一個迴圈從左邊掃到右邊,尋找大於分割槽元素的元素,第二個迴圈從右邊掃到左邊,尋找小於分割槽元素的元素,在找到這兩個元素後,將他們互換,該過程會一直持續下去直到左索引和右索引在該列表的“中間”相遇。
歸併排序:通過遞迴地把列表分半,直到每個子列表中只剩下一個元素為止,然後歸併這些子列表。
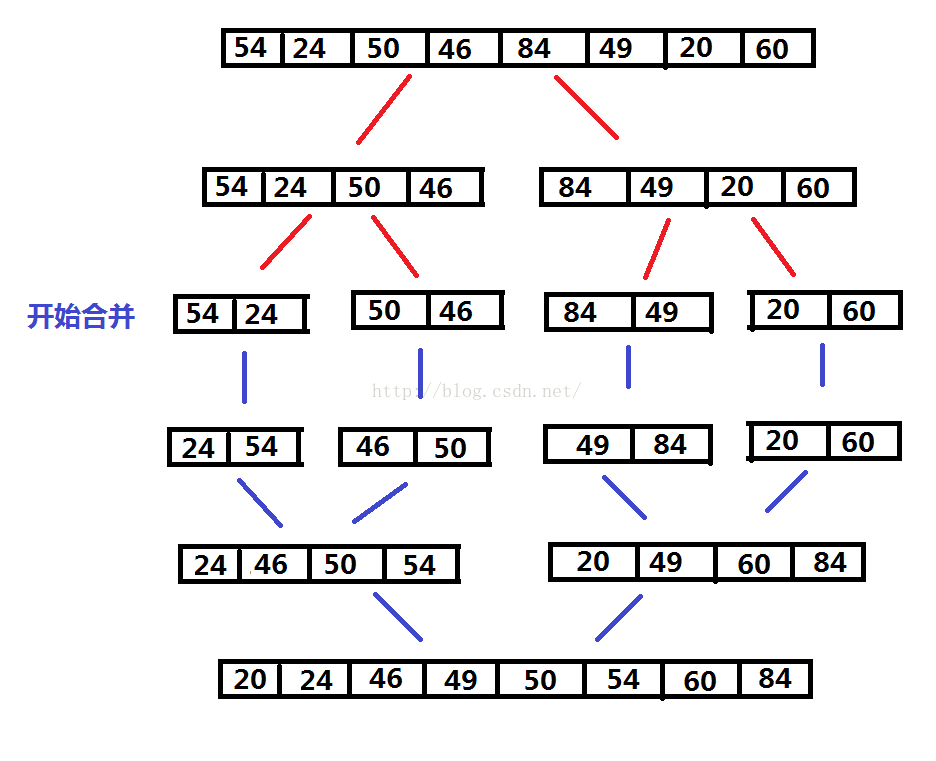
- 歸併排序演算法穩定,陣列需要O(n)的額外空間,連結串列需要O(log(n))的額外空間,時間複雜度為O(nlog(n)),不需要對資料的隨機讀取。
- 在課本程式碼中,需重點理解merge方法。
- 基數排序:使用排序金鑰而不是直接地進行比較元素,來實現元素排序。
- 比較數字大小,我們是先比位數,如果一個位數比另一個位數多,那這個數肯定更大。如果位數同樣多,就按位數遞減依次往下進行比較,哪個數在這一位上更大那就停止比較,得出這個在這個位上數更大的數字整體更大的結論。同樣來講我們也可以從最小的位開始比較。這就和基數排序原理相通了。
這是一篇介紹的很詳細的部落格,大家可以參考理解桶子法排序原理和實現
教材學習中的問題和解決過程 Problem and countermeasure
- 問題1:不明白基數排序RadixSort程式碼的迴圈中為什麼迴圈次數是10次?
for (int digitVal = 0; digitVal <= 9; digitVal++)
digitQueues[digitVal] = (Queue<Integer>)(new LinkedList<Integer>());- 問題1的解決:關鍵就在於
Queue<Integer>[] digitQueues = (LinkedList<Integer>[])(new LinkedList[10]);中,最初建立的陣列中含有十個佇列,那為什麼創造10個佇列呢?通過Debug跟著程式走一遍,我才明白原來這10個佇列是分別儲存不同的關鍵字取值。而每一個數字位上可取0~9的數字,故建立了包含10個佇列的陣列。 - 問題2:還是在基數排序RadixSort的程式碼中,不理解Character.digit方法
digit = Character.digit(temp.charAt(3-position), 10);,隱隱約約覺得Character是一個類,而digit是裡面的靜態方法,從程式碼的實現目的來看,應該是得到特殊位置的元素值。 問題2的解決:通過查詢JavaAPI文件,得到如下的解釋。

其實意思就是將3-position這個位置上的數字值返回。程式碼實現時的問題作答 Exercise
1.在做pp9.2的時候程式寫完後借用Contact的測試類來測試新的gapSort方法,沒有報錯但是排序直接沒有改變。
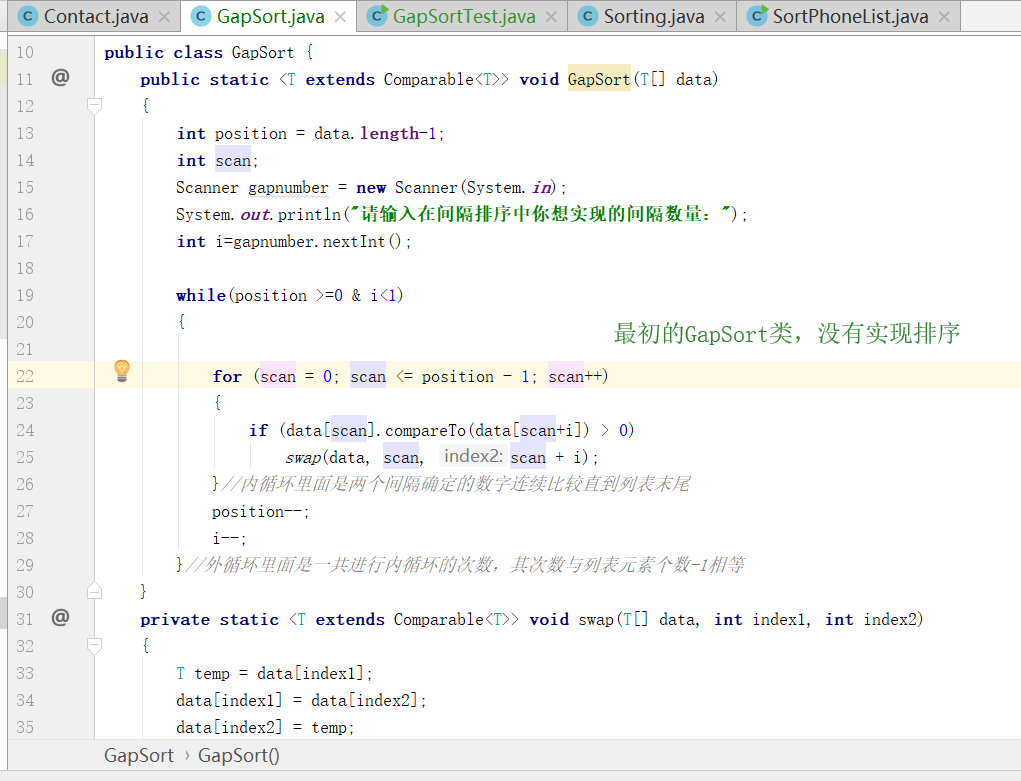
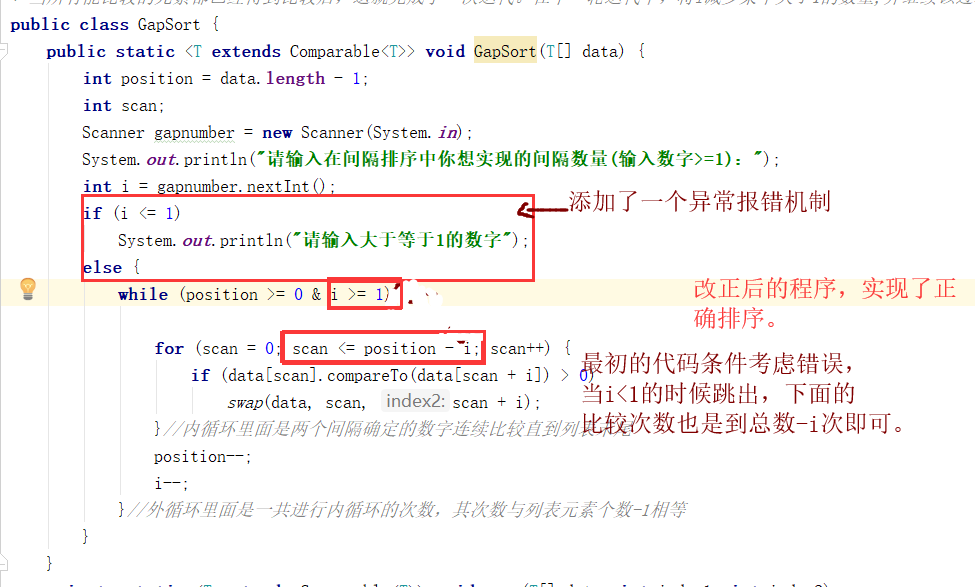
問題1的解決:其實是很簡單的錯誤,又檢查了一遍就發現了問題所在,當進行外迴圈的時候,while語句中應該是滿足的條件,而不是跳出迴圈的條件,在內迴圈中,只要從比較
position-i次即可,這樣所有數字都可以遍歷比較到了。
- 2:對pp9.3要求的“在每個排序法中新增程式碼以使得他們能夠對總的比較次數和每一演算法的總執行時間進行計數”中的計算時間不太瞭解。
- 問題2的解決:我找到啦java計算程式碼段執行時間
也就是在程式執行前獲取當前系統時間,然後在程式執行完之後再獲取此時的系統時間,兩者相減就得到了該程式的執行時間。 - 程式碼也是很簡潔明瞭の
第一種是以毫秒為單位計算的。
long startTime = System.currentTimeMillis(); //獲取開始時間
doSomething(); //測試的程式碼段
long endTime = System.currentTimeMillis(); //獲取結束時間
System.out.println("程式執行時間:" + (endTime - startTime) + "ms"); //輸出程式執行時間
第二種是以納秒為單位計算的。
long startTime=System.nanoTime(); //獲取開始時間
doSomeThing(); //測試的程式碼段
long endTime=System.nanoTime(); //獲取結束時間
System.out.println("程式執行時間: "+(endTime-startTime)+"ns"); 上週測試活動錯題改正 Correction
- 1.A circular array implementation of a queue is more efficient than a fixed array implementation of a queue because elements never have to be ___________.(一個用迴圈陣列實現的佇列比起一個用普通陣列實現的佇列更高效是因為元素不需要__?)
A .added(新增)
B .removed(刪除)
C .shifted(移動)
D .initialized(初始化) 問題的改正和理解:由於佇列操作會修改集合的兩端,因此將一端固定在索引0處要求移動元素,這樣就會使得元素移位產生O(n)的複雜度,而環形陣列可以除去在佇列陣列實現中把元素移位的需要。
本道題不該錯,也不知道是點錯了還是當時理解錯題目了碼雲連結
程式碼量(截圖)
結對及互評Group Estimate
點評模板:
- 部落格中值得學習的或問題:
- 20172301:這周的部落格不僅交的早,質量也超級高。課本上的問題有關於
public static <T extends Comparable<? super T>>的理解實在到位,而且那個盤裝水果真的妙啊。 - 20172304:
- 20172301:這周的部落格不僅交的早,質量也超級高。課本上的問題有關於
其他(感悟、思考等,可選)Else
紙上得來終覺淺,絕知此事要躬行。
在本週的學習過程中,其實連得來紙上也花費了一番功夫,尤其是後面的快速排序、歸併排序和基數排序。
大二其實也不算清閒,每天過的還是很充實。曾經瞭解過工作外8小時決定人生理論,所以很多時候我們要去往哪裡也是一點一點時間累積著告訴我們的。時間安排對一個成年人太重要了,我漸漸意識到自己的生命正因為有侷限才有不同的階段、不同的需要、不同的安排。
知道我是誰,我要做什麼就好。
本來上面就是這周想說的全部內容了,但是又手欠看了幾篇班裡同學的部落格,真的是太敬佩了。真的有一種我的作業太差了不敢交的感覺。就像小時候寫作文寫的不工整不敢交的感覺一模一樣。捂臉逃跑~~~
學習進度條Learning List
| 程式碼行數(新增/累積) | 部落格量(新增/累積) | 學習時間(新增/累積) | |
|---|---|---|---|
| 目標 | 5000行 | 30篇 | 400小時 |
| 第一週 | 0/0 | 1/1 | 8/8 |
| 第二週 | 621/621 | 1/2 | 12/20 |
| 第三週 | 678/1299 | 1/3 | 10/30 |
| 第四周 | 2734/4033 | 1/4 | 20/50 |
| 第五週 | 1100/5133 | 1/5 | 20/70 |
參考資料Reference
- 《Java軟體結構與資料結構》(第四版)
- 《JavaAPI文件》
- java計算程式碼段執行時間
- java快速排序原理
- java歸併排序原理