
Multi-Task CNN
- 同時實習人臉檢測與人臉對齊;
- 級聯結構,三階段卷積網路,由粗到細的預測人臉候選框和關鍵點位置
資料預處理
對影象進行多尺度的resize,構成影象金字塔,頂端金字塔最小應該大於12 * 12。這樣網路的輸入尺寸雖然固定,但是可以處理不同尺寸的人臉。
訓練集構建
由於網路同時執行人臉檢測和對齊,因此在這裡我們在訓練過程中使用四種不同的資料型別:
- Positives:與ground truth face的IOU高於閾值0.65,
- Negatives: 與ground truth face的IOU低於閾值0.3
- partfaces: 與ground truth face的IOU處於0.4和0.65之間
- landmarkface: 擁有landmark的標籤的人臉
在人臉分類任務中使用使用positives & negatives; 在候選框bbox預測任務中使用positives & partface; 在人臉landmark預測任務中使用landmarkfaces
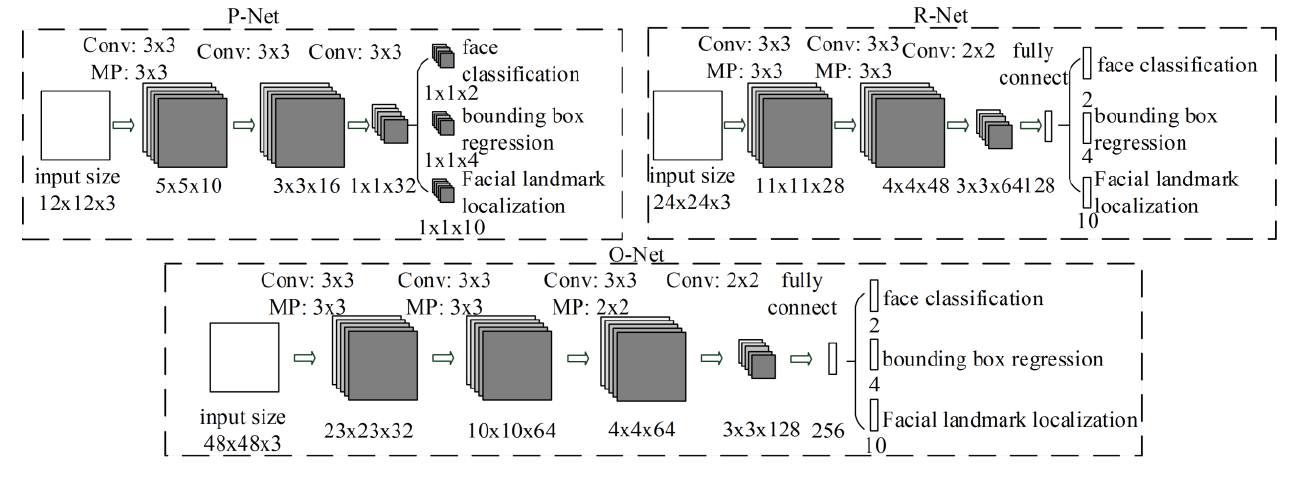
Proposal Network (P-Net)
得到5個通道的特徵圖:第一個通道代表置信度:凡是大於0.7的留下來然後。反算回去:IDX(特徵圖的索引)*步長=進入P網路圖的尺寸,然後除以原圖的比例,得到建議框(為正方形),另外四個通道為位置的偏移:XX * / W = X關(偏移)得到原框X.然後通過非大值抑制,將多餘的框去掉。
- 藉助FCN思想,每個12*12*3的bbox候選框作為輸入,PNet只能檢測12*12內人臉,所以應對影象按比例縮放;將每個金字塔的圖片輸入到P網路
- 在訓練時,有3條支路輸出為人臉分類,邊框迴歸,關鍵點定位;而在測試時,輸出只有N個邊框的4個座標資訊和score(人臉分類置信度)
- 輸出候選框和相對應的邊界框迴歸向量(K*9,K就是bbox的數量,9包含4個座標點資訊(利用迴歸支路進行修改),1個置信度score和4個用來調整前面4個座標點的偏移資訊).
- 利用迴歸向量修改邊框,然後NMS去除重疊輸出為N*5,N為最終bbox個數.
Refine Network (R-Net)
由於得到的原框大小可能為長方形,所以需要PIL等工具在原圖上接一個正方形,然後在等比例縮放,得到的24×24的人臉不會變形。然後重新確定位置的偏移,得到新的框,再做NMS
- 以P-Net預測的bbox資訊為基礎,對原始圖片切片並resize尺寸,即將bbox pading 為24*24,增加為4維,最終輸入(N,3,24,24)
- 經過人臉概率濾除,迴歸資訊利用,NMS得到最終輸出M*5,即M個4個座標點資訊(利用迴歸支路進行修改)和score組合
O-Net
- 與R-Net類似,但增加landmark位置資訊的迴歸,輸入N*3*48*48,
- output[0]N*10表示5個關鍵點的x,y資訊.ouput[1]表示最終若干個bbox的4個座標資訊和置信度分數
訓練過程
三個任務:
face/non-face classification
此為二分類問題,對於每個輸入,我們採用交叉熵損失函式:
這裡是網路預測樣本為人臉的概率,
表示真實人臉標籤資料
bounding box regression
對於每個候選視窗,我們預測它與最近的真實標籤之間的偏移(左上、寬度、高度),為迴歸任務,採用歐幾里得損失函式(L2範數損失函式):
這裡為網路輸出的邊框迴歸
landmark localization
如同邊框迴歸,關鍵點定位也是迴歸問題,最小化損失函式
多工訓練
通過損失函式分配實現:根據不同的輸入計算上述三種損失值
這裡N是樣本數,表示任務重要性,P-Net,R-Net(
),O-Net(
)。P-Net and R-Net的landmark任務重要性小於O-Net,說明前兩個stage重在濾除非人臉bbox
為樣本探測器,非人臉情況下,只需計算交叉熵損失。
此外,在每個mini-batch中,對前向傳播中所有樣本的損失進行排序,選擇前70%,作為hard sample,然後只將硬樣本的梯度用於反向傳播.